Kubernetes · 24 min read · Nov 03, 2025
Kernkomponenten eines Kubernetes-Clusters

Kubernetes ist eine Open-Source-Plattform zur Verwaltung von containerisierten Workloads und Diensten, die deklarative Konfiguration und Automatisierung erleichtert. Der Name Kubernetes stammt aus dem Griechischen und bedeutet Steuermann oder Pilot. Es ist portabel sowie erweiterbar und hat ein schnell wachsendes Ökosystem. Die Dienste und Tools von Kubernetes sind weit verbreitet.
In diesem Artikel werden wir einen Überblick über die Hauptkomponenten von Kubernetes geben, von dem, woraus jeder Container besteht, bis hin dazu, wie ein Container in einem Pod bereitgestellt und über jeden der Worker geplant wird. Es ist entscheidend, die vollständigen Einzelheiten des Kubernetes-Clusters zu verstehen, um in der Lage zu sein, eine Lösung basierend auf Kubernetes als Orchestrator für containerisierte Anwendungen zu entwerfen und bereitzustellen.
Hier ist eine kurze Übersicht über die Themen, die wir in diesem Artikel behandeln werden:
- Komponenten des Kontrollpanels
- Die Komponenten der Kubernetes-Worker
- Pods als grundlegende Bausteine
- Kubernetes-Dienste, Lastenausgleicher und Ingress-Controller
- Kubernetes-Bereitstellungen und Daemon-Sets
- Persistente Speicherung in Kubernetes
Der Kubernetes-Kontrollbereich
Die Kubernetes-Masterknoten sind der Ort, an dem die Kernkontrollbereichsdienste leben; nicht alle Dienste müssen auf demselben Knoten wohnen; jedoch werden sie aus Zentralisierungs- und Praktikabilitätsgründen oft so bereitgestellt. Dies wirft offensichtlich Fragen zur Verfügbarkeit der Dienste auf; diese können jedoch leicht überwunden werden, indem mehrere Knoten vorhanden sind und Lastenausgleichsanfragen bereitgestellt werden, um ein hochverfügbares Set von Masterknoten zu erreichen.
Die Masterknoten bestehen aus vier grundlegenden Diensten:
- Der kube-apiserver
- Der kube-scheduler
- Der kube-controller-manager
- Die etcd-Datenbank
Masterknoten können entweder auf Bare-Metal-Servern, virtuellen Maschinen oder in einer privaten oder öffentlichen Cloud ausgeführt werden, es wird jedoch nicht empfohlen, Container-Workloads auf ihnen auszuführen. Dazu werden wir später mehr sehen.
Das folgende Diagramm zeigt die Komponenten der Kubernetes-Masterknoten:
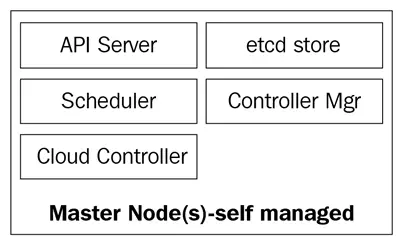
Der kube-apiserver
Der API-Server ist das, was alles zusammenbindet. Es ist die Frontend-REST-API des Clusters, die Manifeste empfängt, um API-Objekte wie Dienste, Pods, Ingress und andere zu erstellen, zu aktualisieren und zu löschen.
Der kube-apiserver ist der einzige Dienst, mit dem wir sprechen sollten; er ist auch der einzige, der mit der etcd-Datenbank schreibt und spricht, um den Clusterzustand zu registrieren. Mit dem kubectl-Befehl werden wir Befehle senden, um mit ihm zu interagieren. Dies wird unser Schweizer Taschenmesser in Bezug auf Kubernetes sein.
Der kube-controller-manager
Der kube-controller-manager-Daemon ist zusammengefasst eine Reihe von unendlichen Kontrollschleifen, die zur Vereinfachung in einer einzigen Binärdatei bereitgestellt werden. Er überwacht den definierten gewünschten Zustand des Clusters und stellt sicher, dass dieser erreicht und erfüllt wird, indem er alle notwendigen Teile bewegt. Der kube-controller-manager ist nicht nur ein Controller; er enthält mehrere verschiedene Schleifen, die verschiedene Komponenten im Cluster überwachen. Einige von ihnen sind der Dienst-Controller, der Namensraum-Controller, der Dienstkonten-Controller und viele andere. Sie können jeden Controller und seine Definition im Kubernetes-GitHub-Repository finden: https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
Der kube-scheduler
Der kube-scheduler plant Ihre neu erstellten Pods auf Knoten mit genügend Platz, um die Ressourcenanforderungen der Pods zu erfüllen. Er hört im Wesentlichen auf den kube-apiserver und den kube-controller-manager, um neu erstellte Pods, die in eine Warteschlange gestellt werden, zu planen und dann einem verfügbaren Knoten zuzuweisen. Die Definition des kube-schedulers finden Sie hier: https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Neben den Rechenressourcen liest der kube-scheduler auch die Affinitäts- und Anti-Affinitätsregeln der Knoten, um herauszufinden, ob ein Knoten diesen Pod ausführen kann oder nicht.
Die etcd-Datenbank
Die etcd-Datenbank ist ein sehr zuverlässiger konsistenter Schlüssel-Wert-Speicher, der verwendet wird, um den Zustand des Kubernetes-Clusters zu speichern. Sie enthält den aktuellen Status der Pods, auf denen der Knoten läuft, wie viele Knoten der Cluster derzeit hat, was der Zustand dieser Knoten ist, wie viele Replikate der Bereitstellung ausgeführt werden, Dienstnamen und andere.
Wie bereits erwähnt, spricht nur der kube-apiserver mit der etcd-Datenbank. Wenn der kube-controller-manager den Zustand des Clusters überprüfen muss, wird er über den API-Server gehen, um den Zustand aus der etcd-Datenbank abzurufen, anstatt die etcd-Speicher direkt abzufragen. Das Gleiche passiert mit dem kube-scheduler, wenn der Scheduler bekannt geben muss, dass ein Pod gestoppt oder einem anderen Knoten zugewiesen wurde; er wird den API-Server informieren, und der API-Server wird den aktuellen Zustand in der etcd-Datenbank speichern.
Mit etcd haben wir alle Hauptkomponenten für unsere Kubernetes-Masterknoten abgedeckt, sodass wir bereit sind, unseren Cluster zu verwalten. Aber ein Cluster besteht nicht nur aus Masterknoten; wir benötigen immer noch die Knoten, die die schwere Arbeit leisten, indem sie unsere Anwendungen ausführen.
Kubernetes-Worker-Knoten
Die Worker-Knoten, die diese Aufgabe in Kubernetes ausführen, werden einfach Knoten genannt. Früher, um 2014, wurden sie Minions genannt, aber dieser Begriff wurde später durch einfach Knoten ersetzt, da der Name mit den Terminologien von Salt verwirrend war und die Leute denken ließ, dass Salt eine wichtige Rolle in Kubernetes spielt.
Diese Knoten sind der einzige Ort, an dem Sie Workloads ausführen werden, da es nicht empfohlen wird, Container oder Lasten auf den Masterknoten zu haben, da sie verfügbar sein müssen, um den gesamten Cluster zu verwalten. Die Knoten sind in Bezug auf Komponenten sehr einfach; sie benötigen nur drei Dienste, um ihre Aufgabe zu erfüllen:
- Kubelet
- Kube-proxy
- Container-Laufzeit
Lassen Sie uns diese drei Komponenten etwas genauer untersuchen.
Der kubelet
Der kubelet ist eine niedrigstufige Kubernetes-Komponente und eine der wichtigsten nach dem kube-apiserver; beide Komponenten sind entscheidend für die Bereitstellung von Pods/Containern im Cluster. Der kubelet ist ein Dienst, der auf den Kubernetes-Knoten läuft und auf den API-Server für die Pod-Erstellung hört. Der kubelet ist nur dafür verantwortlich, Container in Pods zu starten/stoppen und sicherzustellen, dass sie gesund sind; der kubelet kann keine Container verwalten, die nicht von ihm erstellt wurden.
Der kubelet erreicht die Ziele, indem er mit der Container-Laufzeit über die Container-Runtime-Schnittstelle (CRI) spricht. Die CRI bietet dem kubelet über einen gRPC-Client Plug-and-Play-Funktionalität, die es ihm ermöglicht, mit verschiedenen Container-Laufzeiten zu kommunizieren. Wie bereits erwähnt, unterstützt Kubernetes mehrere Container-Laufzeiten, um Container bereitzustellen, und so erreicht es eine so vielfältige Unterstützung für verschiedene Engines.
Sie können den Quellcode des kubelet unter https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet einsehen.
Der kube-proxy
Der kube-proxy ist ein Dienst, der auf jedem Knoten des Clusters residiert und die Kommunikation zwischen Pods, Containern und Knoten ermöglicht. Dieser Dienst überwacht den kube-apiserver auf Änderungen an definierten Diensten (ein Dienst ist eine Art logischer Lastenausgleicher in Kubernetes; wir werden später in diesem Artikel näher auf Dienste eingehen) und hält das Netzwerk über iptables-Regeln auf dem neuesten Stand, die den Datenverkehr an die richtigen Endpunkte weiterleiten. Der kube-proxy richtet auch Regeln in iptables ein, die eine zufällige Lastenverteilung über Pods hinter einem Dienst durchführen.
Hier ist ein Beispiel für eine iptables-Regel, die vom kube-proxy erstellt wurde:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment –comment “default/example: hat keine Endpunkte” -m tcp –dport 80 -j REJECT –reject-with icmp-port-unreachable
Beachten Sie, dass dies ein Dienst ohne Endpunkte ist (keine Pods dahinter).
Container-Laufzeit
Um Container starten zu können, benötigen wir eine Container-Laufzeit. Dies ist die Basismaschine, die die Container im Kernel der Knoten erstellt, damit unsere Pods ausgeführt werden können. Der kubelet wird mit dieser Laufzeit kommunizieren und unsere Container nach Bedarf starten oder stoppen.
Derzeit unterstützt Kubernetes jede OCI-konforme Container-Laufzeit, wie Docker, rkt, runc, runsc usw.
Sie können dies hier https://github.com/opencontainers/runtime-spec nachlesen, um mehr über alle Spezifikationen von der OCI-Git-Hub-Seite zu erfahren.
Jetzt, da wir alle Kernkomponenten, die einen Cluster bilden, untersucht haben, lassen Sie uns nun einen Blick darauf werfen, was mit ihnen getan werden kann und wie Kubernetes uns helfen wird, unsere containerisierten Anwendungen zu orchestrieren und zu verwalten.
Kubernetes-Objekte
Kubernetes-Objekte sind genau das: Sie sind logische persistente Objekte oder Abstraktionen, die den Zustand Ihres Clusters darstellen. Sie sind dafür verantwortlich, Kubernetes zu sagen, was Ihr gewünschter Zustand dieses Objekts ist, damit es daran arbeiten kann, ihn aufrechtzuerhalten und sicherzustellen, dass das Objekt existiert.
Um ein Objekt zu erstellen, muss es zwei Dinge haben: einen Status und seine Spezifikation. Der Status wird von Kubernetes bereitgestellt und ist der aktuelle Zustand des Objekts. Kubernetes verwaltet und aktualisiert diesen Status nach Bedarf, um mit Ihrem gewünschten Zustand übereinzustimmen. Das Spezifikationsfeld hingegen ist das, was Sie Kubernetes bereitstellen, und beschreibt das Objekt, das Sie wünschen. Zum Beispiel das Bild, das Sie möchten, dass der Container ausgeführt wird, die Anzahl der Container dieses Bildes, die Sie ausführen möchten, usw.
Jedes Objekt hat spezifische Spezifikationsfelder für die Art der Aufgabe, die sie ausführen, und Sie werden diese Spezifikationen in einer YAML-Datei bereitstellen, die an den kube-apiserver mit kubectl gesendet wird, der sie in JSON umwandelt und als API-Anfrage sendet. Wir werden später in diesem Artikel näher auf jedes Objekt und seine Spezifikationsfelder eingehen.
Hier ist ein Beispiel für eine YAML, die an kubectl gesendet wurde:
cat << EOF | kubectl create -f -kind: ServiceapiVersion: v1metadata: Name: frontend-servicespec: selector: web: frontend ports: - protocol: TCP port: 80 targetPort: 9256EOF
Die grundlegenden Felder der Objektdokumentation sind die allerersten, und diese werden von Objekt zu Objekt nicht variieren und sind sehr selbsterklärend. Lassen Sie uns einen kurzen Blick darauf werfen:
- kind: Das Kindfeld sagt Kubernetes, welchen Typ von Objekt Sie definieren: einen Pod, einen Dienst, eine Bereitstellung usw.
- apiVersion: Da Kubernetes mehrere API-Versionen unterstützt, müssen wir einen REST-API-Pfad angeben, an den wir unsere Definition senden möchten.
- metadata: Dies ist ein verschachteltes Feld, was bedeutet, dass Sie mehrere weitere Unterfelder zu den Metadaten haben, in denen Sie grundlegende Definitionen wie den Namen Ihres Objekts, die Zuordnung zu einem bestimmten Namensraum und auch das Taggen eines Labels vornehmen, um Ihr Objekt mit anderen Kubernetes-Objekten zu verknüpfen.
Wir haben nun die am häufigsten verwendeten Felder und deren Inhalte durchgesehen; Sie können mehr über die Kubernetes-API-Konventionen unter https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md erfahren.
Einige der Felder des Objekts können später nach der Erstellung des Objekts geändert werden, aber das hängt vom Objekt und dem Feld ab, das Sie ändern möchten.
Die folgende Liste ist eine kurze Übersicht über die verschiedenen Kubernetes-Objekte, die Sie erstellen können:
- Pod
- Volume
- Dienst
- Bereitstellung
- Ingress
- Geheimnis
- ConfigMap
Und es gibt noch viele mehr.
Lassen Sie uns einen genaueren Blick auf jedes dieser Elemente werfen.
Pods – die Basis von Kubernetes
Pods sind die grundlegendsten Objekte in Kubernetes und auch die wichtigsten. Alles dreht sich um sie; wir können sagen, dass Kubernetes für die Pods ist! Alle anderen Objekte sind hier, um ihnen zu dienen, und alle Aufgaben, die sie ausführen, dienen dazu, die Pods in den gewünschten Zustand zu versetzen.
Was ist also ein Pod und warum sind Pods so wichtig?
Ein Pod ist ein logisches Objekt, das ein oder mehrere Container zusammen im selben Netzwerk-Namespace, derselben Interprozesskommunikation (IPC) und manchmal, je nach Version von Kubernetes, im selben Prozess-ID (PID)-Namespace ausführt. Dies liegt daran, dass sie die Container ausführen werden und somit im Mittelpunkt stehen. Der ganze Sinn von Kubernetes ist es, ein Container-Orchestrator zu sein, und mit Pods machen wir die Orchestrierung möglich.
Wie bereits erwähnt, leben Container im selben Pod in einer „Blase“, in der sie über localhost miteinander kommunizieren können, da sie lokal zueinander sind. Ein Container in einem Pod hat die gleiche IP-Adresse wie der andere Container, da sie einen Netzwerk-Namespace teilen, aber in den meisten Fällen werden Sie auf einer Eins-zu-Eins-Basis arbeiten, das heißt, ein einzelner Container pro Pod. Mehrere Container pro Pod werden nur in sehr spezifischen Szenarien verwendet, z. B. wenn eine Anwendung einen Helfer benötigt, wie einen Daten-Pusher oder einen Proxy, der schnell und resilient mit der Hauptanwendung kommunizieren muss.
Die Art und Weise, wie Sie einen Pod definieren, ist die gleiche, wie Sie es für jedes andere Kubernetes-Objekt tun würden: über eine YAML, die alle Pod-Spezifikationen und -Definitionen enthält:
kind: PodapiVersion: v1metadata:name: hello-podlabels: hello: podspec: containers: - name: hello-container image: alpine args: - echo - “Hallo Welt”
Lassen Sie uns die grundlegenden Pod-Definitionen durchgehen, die unter dem Spezifikationsfeld benötigt werden, um unseren Pod zu erstellen:
- Container: Ein Container ist ein Array; daher haben wir eine Reihe von mehreren Unterfeldern darunter. Im Grunde ist es das, was die Container definiert, die im Pod ausgeführt werden. Wir können einen Namen für den Container, das Bild, von dem er abgeleitet wird, und die Argumente oder den Befehl angeben, den wir benötigen, dass er ausgeführt wird. Der Unterschied zwischen Argumenten und Befehlen ist derselbe wie der Unterschied zwischen CMD und ENTRYPOINT. Beachten Sie, dass alle Felder, die wir gerade durchgegangen sind, für das Container-Array sind. Sie sind nicht direkt Teil der Spezifikation des Pods.
- restartPolicy: Dieses Feld ist genau das: Es sagt Kubernetes, was mit einem Container zu tun ist, und es gilt für alle Container im Pod im Falle eines Null- oder Nicht-Null-Austrittscodes. Sie können zwischen den Optionen Never, OnFailure oder Always wählen. Always wird der Standard sein, falls eine restartPolicy nicht definiert ist.
Dies sind die grundlegendsten Spezifikationen, die Sie für einen Pod deklarieren werden; andere Spezifikationen erfordern, dass Sie ein wenig mehr Hintergrundwissen darüber haben, wie Sie sie verwenden und wie sie mit verschiedenen anderen Kubernetes-Objekten interagieren. Wir werden sie später in diesem Artikel wieder besuchen; einige von ihnen sind:
- Volume
- Env
- Ports
- dnsPolicy
- initContainers
- nodeSelector
- Ressourcenlimits und -anforderungen
Um die Pods anzuzeigen, die derzeit in Ihrem Cluster ausgeführt werden, können Sie kubectl get pods ausführen:
dsala@MININT-IB3HUA8:~$ kubectl get podsNAME READY STATUS RESTARTS AGEbusybox 1/1 Running 120 5d
Alternativ können Sie kubectl describe pods ausführen, ohne einen Pod anzugeben. Dies wird eine Beschreibung jedes Pods ausgeben, der im Cluster ausgeführt wird. In diesem Fall wird es nur der busybox-Pod sein, da er der einzige ist, der derzeit ausgeführt wird:
dsala@MININT-IB3HUA8:~$ kubectl describe podsName: busyboxNamespace: defaultPriority: 0PriorityClassName:
Pods sind sterblich. Sobald sie sterben oder gelöscht werden, können sie nicht wiederhergestellt werden. Ihre IP und die Container, die darauf ausgeführt wurden, werden verschwunden sein; sie sind völlig vergänglich. Die Daten in den Pods, die als Volume gemountet sind, können je nach Ihrer Konfiguration überleben oder auch nicht. Wenn unsere Pods sterben und wir sie verlieren, wie stellen wir sicher, dass alle unsere Mikrodienste ausgeführt werden? Nun, Bereitstellungen sind die Antwort.
Bereitstellungen
Pods allein sind nicht sehr nützlich, da es nicht sehr effizient ist, mehr als eine einzige Instanz unserer Anwendung in einem einzigen Pod auszuführen. Hunderte von Kopien unserer Anwendung in verschiedenen Pods bereitzustellen, ohne eine Methode zu haben, um sie alle zu finden, wird sehr schnell unübersichtlich.
Hier kommen Bereitstellungen ins Spiel. Mit Bereitstellungen können wir unsere Pods mit einem Controller verwalten. Dies ermöglicht es uns nicht nur zu entscheiden, wie viele wir ausführen möchten, sondern wir können auch Updates verwalten, indem wir die Bildversion oder das Bild selbst ändern, das unsere Container ausführen. Bereitstellungen sind das, womit Sie die meiste Zeit arbeiten werden. Mit Bereitstellungen sowie Pods und allen anderen Objekten, die wir zuvor erwähnt haben, haben sie ihre eigene Definition in einer YAML-Datei:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deployment labels: deployment: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
Lassen Sie uns mit der Erkundung ihrer Definition beginnen.
Am Anfang der YAML haben wir allgemeinere Felder wie apiVersion, kind und metadata. Aber unter spec finden wir die spezifischen Optionen für dieses API-Objekt.
Unter spec können wir die folgenden Felder hinzufügen:
Selector: Mit dem Selector-Feld weiß die Bereitstellung, welche Pods sie anvisieren soll, wenn Änderungen angewendet werden. Es gibt zwei Felder, die Sie unter dem Selector verwenden werden: matchLabels und matchExpressions. Mit matchLabels verwendet der Selector die Labels der Pods (Schlüssel/Wert-Paare). Es ist wichtig zu beachten, dass alle Labels, die Sie hier angeben, ANDed werden. Das bedeutet, dass der Pod alle Labels haben muss, die Sie unter matchLabels angeben.
Replicas: Dies gibt die Anzahl der Pods an, die die Bereitstellung über den Replikationscontroller am Laufen halten muss; wenn Sie beispielsweise drei Replikate angeben und einer der Pods stirbt, wird der Replikationscontroller die Replikatspezifikation als gewünschten Zustand überwachen und den Scheduler informieren, um einen neuen Pod zu planen, da der aktuelle Status jetzt 2 ist, da der Pod gestorben ist.
RevisionHistoryLimit: Jedes Mal, wenn Sie eine Änderung an der Bereitstellung vornehmen, wird diese Änderung als Revision der Bereitstellung gespeichert, auf die Sie später entweder zurückkehren oder einen Protokoll über die Änderungen führen können. Sie können Ihre Historie mit kubectl rollout history deployment/
Strategy: Dies ermöglicht es Ihnen zu entscheiden, wie Sie mit einem Update oder einer horizontalen Pod-Skalierung umgehen möchten. Um den Standardwert, der rollingUpdate ist, zu überschreiben, müssen Sie den Typ-Schlüssel schreiben, bei dem Sie zwischen zwei Werten wählen können: recreate oder rollingUpdate.
Während recreate eine schnelle Möglichkeit ist, Ihre Bereitstellung zu aktualisieren, werden dabei alle Pods gelöscht und durch neue ersetzt, was bedeutet, dass Sie berücksichtigen müssen, dass bei dieser Strategie eine Systemausfallzeit ansteht. Das rollingUpdate hingegen ist sanfter und langsamer und ideal für zustandsbehaftete Anwendungen, die ihre Daten neu ausbalancieren können. Das rollingUpdate öffnet die Tür für zwei weitere Felder, die maxSurge und maxUnavailable sind.
Das erste gibt an, wie viele Pods über die Gesamtanzahl hinaus Sie bei einem Update haben möchten; beispielsweise wird eine Bereitstellung mit 100 Pods und einem maxSurge von 20 % auf maximal 120 Pods wachsen, während sie aktualisiert wird. Die nächste Option ermöglicht es Ihnen, auszuwählen, wie viele Pods in Prozent Sie bereit sind zu töten, um sie durch neue zu ersetzen, in einem Szenario mit 100 Pods. In Fällen, in denen 20 % maxUnavailable sind, werden nur 20 Pods getötet und durch neue ersetzt, bevor die restlichen Pods der Bereitstellung ersetzt werden.
Template: Dies ist nur ein verschachteltes Pod-Spezifikationsfeld, in dem Sie alle Spezifikationen und Metadaten der Pods einfügen, die die Bereitstellung verwalten wird.
Wir haben gesehen, dass wir mit Bereitstellungen unsere Pods verwalten und sie uns helfen, sie in einem Zustand zu halten, den wir wünschen. All diese Pods befinden sich immer noch in einem sogenannten Cluster-Netzwerk, das ein geschlossenes Netzwerk ist, in dem nur die Komponenten des Kubernetes-Clusters miteinander kommunizieren können, und sogar ihre eigenen IP-Bereiche haben. Wie kommunizieren wir von außen mit unseren Pods? Wie erreichen wir unsere Anwendung? Hier kommen die Dienste ins Spiel.
Dienste:
Der Name Dienst beschreibt nicht vollständig, was Dienste in Kubernetes tatsächlich tun. Kubernetes-Dienste sind das, was den Datenverkehr zu unseren Pods leitet. Wir können sagen, dass Dienste das sind, was Pods miteinander verbindet.
Stellen Sie sich vor, wir haben eine typische Frontend/Backend-Anwendung, bei der unsere Frontend-Pods über die IP-Adressen der Pods mit unseren Backend-Pods kommunizieren. Wenn ein Pod im Backend stirbt, verlieren wir die Kommunikation mit unserem Backend. Dies liegt nicht nur daran, dass der neue Pod nicht die gleiche IP-Adresse wie der Pod hat, der gestorben ist, sondern jetzt müssen wir auch unsere App neu konfigurieren, um die neue IP-Adresse zu verwenden. Dieses Problem und ähnliche Probleme werden mit Diensten gelöst.
Ein Dienst ist ein logisches Objekt, das dem kube-proxy sagt, iptables-Regeln zu erstellen, basierend darauf, welche Pods hinter dem Dienst stehen. Dienste konfigurieren ihre Endpunkte, was die Pods hinter einem Dienst sind, auf die gleiche Weise, wie Bereitstellungen wissen, welche Pods sie steuern sollen, das Selektorfeld und die Labels der Pods.
Dieses Diagramm zeigt Ihnen, wie Dienste Labels verwenden, um den Datenverkehr zu verwalten:
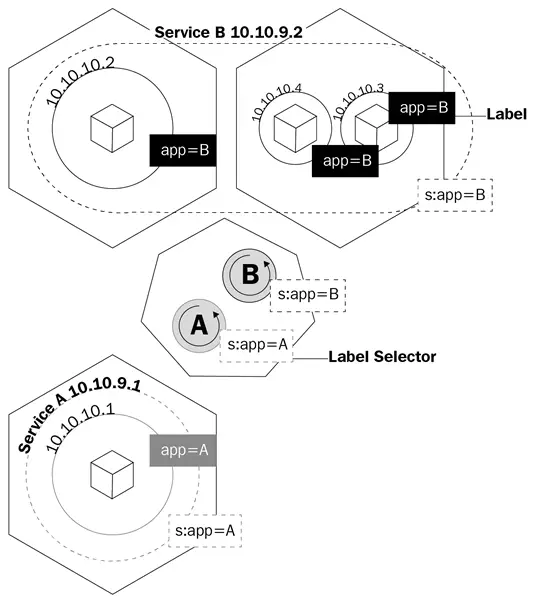
Dienste werden nicht nur den kube-proxy anweisen, Regeln zum Leiten von Datenverkehr zu erstellen; sie werden auch etwas auslösen, das kube-dns genannt wird.
Kube-dns ist eine Gruppe von Pods mit SkyDNS-Containern, die im Cluster ausgeführt werden und einen DNS-Server und -Weiterleiter bereitstellen, der Aufzeichnungen für Dienste und manchmal Pods zur Vereinfachung erstellt. Jedes Mal, wenn Sie einen Dienst erstellen, wird ein DNS-Eintrag erstellt, der auf die interne Cluster-IP-Adresse des Dienstes zeigt, in der Form service-name.namespace.svc.cluster.local. Sie können mehr über die Kubernetes-DNS-Spezifikationen hier erfahren: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Zurück zu unserem Beispiel müssen wir nun nur noch unsere Anwendung so konfigurieren, dass sie mit dem vollständig qualifizierten Domänennamen (FQDN) des Dienstes spricht, um mit unseren Backend-Pods zu kommunizieren. Auf diese Weise spielt es keine Rolle, welche IP-Adresse die Pods und Dienste haben. Wenn ein Pod hinter dem Dienst stirbt, kümmert sich der Dienst um alles, indem er den A-Eintrag verwendet, da wir in der Lage sein werden, unserem Frontend zu sagen, dass es den gesamten Datenverkehr zu my-svc leiten soll. Die Logik des Dienstes kümmert sich um alles andere.
Es gibt mehrere Arten von Diensten, die Sie erstellen können, wann immer Sie das Objekt deklarieren, das in Kubernetes erstellt werden soll. Lassen Sie uns diese durchgehen, um zu sehen, welche am besten für die Art von Arbeit geeignet ist, die wir benötigen:
ClusterIP: Dies ist der Standarddienst. Jedes Mal, wenn Sie einen ClusterIP-Dienst erstellen, wird ein Dienst mit einer clusterinternen IP-Adresse erstellt, die nur innerhalb des Kubernetes-Clusters routbar ist. Diese Art ist ideal für Pods, die nur miteinander kommunizieren müssen und nicht außerhalb des Clusters gehen müssen.
NodePort: Wenn Sie diesen Diensttyp erstellen, wird standardmäßig ein zufälliger Port von 30000 bis 32767 zugewiesen, um den Datenverkehr an die Endpunkt-Pods des Dienstes weiterzuleiten. Sie können dieses Verhalten überschreiben, indem Sie einen Knotenport im Ports-Array angeben. Sobald dies definiert ist, können Sie auf Ihre Pods über
LoadBalancer: Die meiste Zeit werden Sie Kubernetes bei einem Cloud-Anbieter ausführen. Der LoadBalancer-Typ ist ideal für diese Situationen, da Sie öffentliche IP-Adressen für Ihren Dienst über die API Ihres Cloud-Anbieters zuweisen können. Dies ist der ideale Dienst, wenn Sie von außerhalb Ihres Clusters mit Ihren Pods kommunizieren möchten. Mit LoadBalancer können Sie nicht nur eine öffentliche IP-Adresse zuweisen, sondern auch, wenn Sie Azure verwenden, eine private IP-Adresse aus Ihrem virtuellen privaten Netzwerk zuweisen. So können Sie von dem Internet oder intern in Ihrem privaten Subnetz mit Ihren Pods kommunizieren.
Lassen Sie uns die YAML-Definition eines Dienstes überprüfen:
apiVersion: v1kind: Servicemetadata: name: my-servicespec: selector: app: front-end type: NodePort ports: - name: http port: 80 targetPort: 8080 nodePort: 30024 protocol: TCP
Die YAML eines Dienstes ist sehr einfach, und die Spezifikationen variieren je nach Art des Dienstes, den Sie erstellen. Aber das Wichtigste, was Sie berücksichtigen müssen, sind die Portdefinitionen. Lassen Sie uns diese ansehen:
- port: Dies ist der Dienstport, der exponiert wird
- targetPort: Dies ist der Port auf den Pods, zu dem der Dienst den Datenverkehr sendet
- nodePort: Dies ist der Port, der exponiert wird
Obwohl wir jetzt verstehen, wie wir mit den Pods in unserem Cluster kommunizieren können, müssen wir immer noch verstehen, wie wir das Problem des Verlusts unserer Daten jedes Mal verwalten, wenn ein Pod beendet wird. Hier kommen Persistente Volumes (PV) ins Spiel.
Kubernetes und persistente Speicherung
Persistente Speicherung in der Containerwelt ist ein ernstes Problem. Der einzige Speicher, der über Containerläufe hinweg persistent ist, sind die Schichten des Images, und sie sind schreibgeschützt. Die Schicht, in der der Container läuft, ist schreibbar, aber alle Daten in dieser Schicht werden gelöscht, sobald der Container stoppt. Bei Pods ist es dasselbe. Wenn ein Container stirbt, sind die Daten, die darauf geschrieben wurden, weg.
Kubernetes hat eine Reihe von Objekten, um Speicher über Pods hinweg zu verwalten. Das erste, das wir besprechen werden, sind Volumes.
Volumes
Volumes lösen eines der größten Probleme, wenn es um persistente Speicherung geht. Zunächst einmal sind Volumes eigentlich keine Objekte, sondern eine Definition des Pod-Spezifikationsfeldes. Wenn Sie einen Pod erstellen, können Sie ein Volume im Spezifikationsfeld des Pods definieren. Container in diesem Pod können das Volume in ihrem Mount-Namespace einhängen, und das Volume wird über Container-Neustarts oder Abstürze hinweg verfügbar sein. Volumes sind jedoch an die Pods gebunden, und wenn der Pod gelöscht wird, ist das Volume ebenfalls verschwunden. Die Daten auf dem Volume sind eine andere Geschichte; die Datenpersistenz hängt vom Backend dieses Volumes ab.
Kubernetes unterstützt mehrere Arten von Volumes oder Volumenspeichern und wie sie in den API-Spezifikationen genannt werden, die von Dateisystemzuordnungen vom lokalen Knoten, virtuellen Festplatten von Cloud-Anbietern und softwaredefinierten, speicherunterstützten Volumes reichen. Lokale Dateisystemeinbindungen sind die häufigsten, die Sie bei regulären Volumes sehen werden. Es ist wichtig zu beachten, dass der Nachteil der Verwendung des lokalen Dateisystems des Knotens darin besteht, dass die Daten nicht über alle Knoten des Clusters hinweg verfügbar sind, sondern nur auf dem Knoten, auf dem der Pod geplant wurde.
Lassen Sie uns untersuchen, wie ein Pod mit einem Volume in YAML definiert wird:
apiVersion: v1kind: Podmetadata: name: test-pdspec: containers: - image: k8s.gcr.io/test-webserver name: test-container volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: path: /data type: Directory
Beachten Sie, dass es ein Feld namens volumes unter spec gibt und dann ein weiteres namens volumeMounts.
Das erste Feld (volumes) ist der Ort, an dem Sie das Volume definieren, das Sie für diesen Pod erstellen möchten. Dieses Feld erfordert immer einen Namen und dann eine Volumenspeicherquelle. Je nach Quelle variieren die Anforderungen. In diesem Beispiel wäre die Quelle hostPath, was das lokale Dateisystem eines Knotens ist. hostPath unterstützt mehrere Arten von Zuordnungen, die von Verzeichnissen, Dateien, Blockgeräten und sogar Unix-Sockets reichen.
Im zweiten Feld, volumeMounts, haben wir mountPath, wo Sie den Pfad innerhalb des Containers definieren, an dem Sie Ihr Volume einhängen möchten. Der name-Parameter ist, wie Sie dem Pod mitteilen, welches Volume verwendet werden soll. Dies ist wichtig, da Sie mehrere Arten von Volumes unter volumes definiert haben können, und der Name ist der einzige Weg für den Pod zu wissen, welches.
Sie können mehr über die verschiedenen Arten von Volumes hier https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes und im Kubernetes-API-Referenzdokument (https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.11/#volume-v1-core) erfahren.
Es ist nicht ideal, dass Volumes mit den Pods sterben. Wir benötigen Speicher, der persistent ist, und so entstand die Notwendigkeit für PVs.
Persistente Volumes, Persistente Volumenansprüche und Speicherklassen
Der Hauptunterschied zwischen Volumes und PVs besteht darin, dass PVs im Gegensatz zu Volumes tatsächlich Kubernetes-API-Objekte sind, sodass Sie sie individuell wie separate Entitäten verwalten können, und sie daher auch nach der Löschung eines Pods bestehen bleiben.
Sie fragen sich vielleicht, warum dieser Unterabschnitt PV, persistente Volumenansprüche (PVCs) und Speicherklassen alle gemischt sind. Das liegt daran, dass alle voneinander abhängen, und es entscheidend ist, zu verstehen, wie sie miteinander interagieren, um Speicher für unsere Pods bereitzustellen.
Lassen Sie uns mit PVs und PVCs beginnen. Wie Volumes haben PVs eine Speicherquelle, sodass der gleiche Mechanismus, den Volumes haben, hier gilt. Sie haben entweder einen softwaredefinierten Speichercluster, der eine logische Einheit Nummer (LUN) bereitstellt, einen Cloud-Anbieter, der virtuelle Festplatten bereitstellt, oder sogar ein lokales Dateisystem zum Kubernetes-Knoten, aber hier werden sie anstelle von Volumenspeicherquellen als persistente Volumen Typen bezeichnet.
PVs sind ziemlich ähnlich wie LUNs in einem Speicherarray: Sie erstellen sie, aber ohne Zuordnung; sie sind einfach eine Menge zugewiesenen Speichers, die darauf warten, verwendet zu werden. PVCs sind wie LUN-Zuordnungen: Sie sind an einen PV gebunden und auch das, was Sie tatsächlich definieren, verknüpfen und dem Pod zur Verfügung stellen, den er dann für seine Container verwenden kann.
Die Art und Weise, wie Sie PVCs in Pods verwenden, ist genau die gleiche wie bei normalen Volumes. Sie haben zwei Felder: eines, um anzugeben, welches PVC Sie verwenden möchten, und das andere, um dem Pod zu sagen, in welchem Container dieses PVC verwendet werden soll.
Die YAML für eine PVC-API-Objektdokumentation sollte den folgenden Code haben:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: gluster-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi
Die YAML für den Pod sollte den folgenden Code haben:
kind: PodapiVersion: v1metadata: name: mypodspec: containers: - name: myfrontend image: nginx volumeMounts: - mountPath: “/mnt/gluster” name: volume volumes: - name: volume persistentVolumeClaim: claimName: gluster-pvc
Wenn ein Kubernetes-Administrator PVC erstellt, gibt es zwei Möglichkeiten, wie diese Anfrage erfüllt wird:
- Statisch: Mehrere PVs wurden bereits erstellt, und wenn ein Benutzer PVC erstellt, wird jeder verfügbare PV, der die Anforderungen erfüllen kann, an diesen PVC gebunden.
- Dynamisch: Einige PV-Typen können PVs basierend auf PVC-Definitionen erstellen. Wenn PVC erstellt wird, wird der PV-Typ dynamisch ein PV-Objekt erstellen und den Speicher im Backend zuweisen; dies ist die dynamische Bereitstellung. Der Haken bei der dynamischen Bereitstellung ist, dass Sie einen dritten Typ von Kubernetes-Speicherobjekt benötigen, das als Speicherklasse bezeichnet wird.
Speicherklassen sind wie eine Möglichkeit, Ihren Speicher zu stufen. Sie können eine Klasse erstellen, die langsame Speicher-Volumes bereitstellt, oder eine andere mit hyper-schnellen SSD-Laufwerken. Speicherklassen sind jedoch etwas komplexer als nur Stufen. Wie wir in den beiden Möglichkeiten zur Erstellung von PVC erwähnt haben, machen Speicherklassen die dynamische Bereitstellung möglich. Wenn Sie in einer Cloud-Umgebung arbeiten, möchten Sie nicht manuell jede Backend-Festplatte für jedes PV erstellen. Speicherklassen richten etwas ein, das als Provisioner bezeichnet wird, der das Volumen-Plugin aufruft, das erforderlich ist, um mit der API Ihres Cloud-Anbieters zu kommunizieren. Jeder Provisioner hat seine eigenen Einstellungen, damit er mit dem angegebenen Cloud-Anbieter oder Speicheranbieter kommunizieren kann.
Sie können Speicherklassen auf folgende Weise bereitstellen; dies ist ein Beispiel für eine Speicherklasse, die Azure-Disk als Festplatten-Provisioner verwendet:
kind: StorageClassapiVersion: storage.k8s.io/v1metadata: name: my-storage-classprovisioner: kubernetes.io/azure-diskparameters: storageaccounttype: Standard_LRS kind: Shared
Jeder Speicherklassens-Provisioner und PV-Typ hat unterschiedliche Anforderungen und Parameter, ebenso wie Volumes, und wir haben bereits einen allgemeinen Überblick darüber, wie sie funktionieren und wofür wir sie verwenden können. Das Lernen über spezifische Speicherklassen und PV-Typen hängt von Ihrer Umgebung ab; Sie können mehr über jeden von ihnen erfahren, indem Sie auf die folgenden Links klicken:
- https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner
- https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
In diesem Artikel haben wir gelernt, was Kubernetes ist, seine Komponenten und welche Vorteile die Verwendung von Orchestrierung hat. Damit sollte es einfach sein, jedes der Kubernetes-API-Objekte, ihren Zweck und ihre Anwendungsfälle zu identifizieren. Sie sollten jetzt in der Lage sein zu verstehen, wie die Masterknoten den Cluster steuern und die Planung der Container in den Worker-Knoten durchführen.
Wenn Sie diesen Artikel hilfreich fanden, sollte „ Hands-On Linux for Architects “ für Sie hilfreich sein. Mit diesem Buch werden Sie alles von Linux-Komponenten und -Funktionen bis hin zu Hardware- und Softwareunterstützung abdecken, was Ihnen helfen wird, effektive Linux-basierte Lösungen zu implementieren und zu optimieren. Sie werden durch einen Überblick über die Linux-Designmethodik und die Kernkonzepte des Designs einer Lösung geführt. Wenn Sie ein Linux-Systemadministrator, Linux-Support-Techniker, DevOps-Ingenieur, Linux-Berater oder jemand sind, der lernen oder sein Wissen im Bereich Architektur erweitern möchte, ist dieses Buch für Sie.
Erhalte neue Beiträge in deinem Posteingang.
Kein Spam. Jederzeit abmelden.