Hadoop Installation · 11 min read · Dec 21, 2025
So installieren Sie Apache Hadoop auf Ubuntu 22.04

Apache Hadoop ist ein Open-Source-Framework zur Verarbeitung und Speicherung von Big Data. In den heutigen Branchen ist Hadoop der Standardrahmen für Big Data geworden. Hadoop ist so konzipiert, dass es auf verteilten Systemen mit Hunderten oder sogar Tausenden von Cluster-Computern oder dedizierten Servern ausgeführt wird. Vor diesem Hintergrund kann Hadoop große Datensätze mit hohem Volumen und Komplexität sowohl für strukturierte als auch für unstrukturierte Daten verarbeiten.
Jede Hadoop-Bereitstellung enthält die folgenden Komponenten:
- Hadoop Common: Die gemeinsamen Dienstprogramme, die die anderen Hadoop-Module unterstützen.
- Hadoop Distributed File System (HDFS): Ein verteiltes Dateisystem, das einen Hochdurchsatz-Zugriff auf Anwendungsdaten bietet.
- Hadoop YARN: Ein Framework für die Jobplanung und das Cluster-Ressourcenmanagement.
- Hadoop MapReduce: Ein YARN-basiertes System zur parallelen Verarbeitung großer Datensätze.
In diesem Tutorial installieren wir die neueste Version von Apache Hadoop auf einem Ubuntu 22.04-Server. Hadoop wird auf einem Single-Node-Server installiert und wir erstellen einen Pseudo-Distributed Mode der Hadoop-Bereitstellung.
Voraussetzungen
Um diese Anleitung abzuschließen, benötigen Sie die folgenden Anforderungen:
- Einen Ubuntu 22.04-Server - Dieses Beispiel verwendet einen Ubuntu-Server mit dem Hostnamen ‘hadoop’ und der IP-Adresse ‘192.168.5.100’.
- Einen Nicht-Root-Benutzer mit sudo/root Administratorrechten.
Java OpenJDK installieren
Hadoop ist ein großes Projekt unter der Apache Software Foundation, es ist hauptsächlich in Java geschrieben. Zum Zeitpunkt des Schreibens ist die neueste Version von Hadoop v3.3.4, die vollständig mit Java v11 kompatibel ist.
Das Java OpenJDK 11 ist standardmäßig im Ubuntu-Repository verfügbar, und Sie installieren es über APT.
Um zu beginnen, führen Sie den folgenden apt-Befehl aus, um die Paketlisten/Repositories auf Ihrem Ubuntu-System zu aktualisieren und zu aktualisieren.
sudo apt updateInstallieren Sie nun das Java OpenJDK 11 über den folgenden apt-Befehl. Im Ubuntu 22.04-Repository bezieht sich das Paket ‘default-jdk’ auf das Java OpenJDK v11.
sudo apt install default-jdkWenn Sie dazu aufgefordert werden, geben Sie y ein, um zu bestätigen, und drücken Sie ENTER, um fortzufahren. Und die Installation von Java OpenJDK beginnt.
Nachdem Java installiert ist, führen Sie den folgenden Befehl aus, um die Java-Version zu überprüfen. Sie sollten das Java OpenJDK 11 auf Ihrem Ubuntu-System installiert haben.
java -versionJetzt, da das Java OpenJDK installiert ist, richten Sie einen neuen Benutzer mit passwortloser SSH-Authentifizierung ein, der verwendet wird, um Hadoop-Prozesse und -Dienste auszuführen.
Benutzer und passwortlose SSH-Authentifizierung einrichten
Apache Hadoop benötigt, dass der SSH-Dienst auf dem System ausgeführt wird. Dies wird von Hadoop-Skripten verwendet, um den Remote-Hadoop-Daemon auf dem Remote-Server zu verwalten. In diesem Schritt erstellen Sie einen neuen Benutzer, der verwendet wird, um Hadoop-Prozesse und -Dienste auszuführen, und richten dann die passwortlose SSH-Authentifizierung ein.
Falls Sie SSH nicht auf Ihrem System installiert haben, führen Sie den folgenden apt-Befehl aus, um SSH zu installieren. Das Paket ‘pdsh‘ ist ein multithreaded Remote-Shell-Client, mit dem Sie Befehle parallel auf mehreren Hosts ausführen können.
sudo apt install openssh-server openssh-client pdshFühren Sie nun den folgenden Befehl aus, um einen neuen Benutzer ‘hadoop’ zu erstellen und das Passwort für den Benutzer ‘hadoop’ festzulegen.
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoopGeben Sie das neue Passwort für den Benutzer ‘hadoop‘ ein und wiederholen Sie das Passwort.
Fügen Sie als Nächstes den Benutzer ‘hadoop’ über den folgenden usermod-Befehl zur ‘sudo‘-Gruppe hinzu. Dies ermöglicht es dem Benutzer ‘hadoop’, den ‘sudo’-Befehl auszuführen.
sudo usermod -aG sudo hadoopJetzt, da der Benutzer ‘hadoop’ erstellt wurde, melden Sie sich über den folgenden Befehl beim Benutzer ‘hadoop‘ an.
su - hadoopNach der Anmeldung wird Ihre Eingabeaufforderung so aussehen: “ hadoop@hostname.. “.
Führen Sie als Nächstes den folgenden Befehl aus, um den SSH-öffentlichen und privaten Schlüssel zu generieren. Wenn Sie dazu aufgefordert werden, ein Passwort für den Schlüssel festzulegen, drücken Sie ENTER, um zu überspringen.
ssh-keygen -t rsaDer SSH-Schlüssel wird jetzt im ~/.ssh-Verzeichnis generiert. Die id_rsa.pub ist der SSH-öffentliche Schlüssel und die ‘id_rsa’-Datei ist der private Schlüssel.
Sie können den generierten SSH-Schlüssel mit dem folgenden Befehl überprüfen.
ls ~/.ssh/Führen Sie als Nächstes den folgenden Befehl aus, um den SSH-öffentlichen Schlüssel ‘id_rsa.pub‘ in die Datei ‘authorized_keys‘ zu kopieren und die Standardberechtigung auf 600 zu ändern.
Im SSH ist die Datei ‘authorized_keys‘ der Ort, an dem Sie den SSH-öffentlichen Schlüssel speichern, der mehrere öffentliche Schlüssel enthalten kann. Jeder, der den öffentlichen Schlüssel in der Datei ‘authorized_keys‘ gespeichert hat und den richtigen privaten Schlüssel besitzt, kann sich ohne Passwortauthentifizierung als Benutzer ‘hadoop‘ mit dem Server verbinden.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
Mit der passwortlosen SSH-Konfiguration abgeschlossen, können Sie überprüfen, indem Sie sich über den folgenden SSH-Befehl mit der lokalen Maschine verbinden.
ssh localhostGeben Sie yes ein, um zu bestätigen und den SSH-Fingerabdruck hinzuzufügen, und Sie sind ohne Passwortauthentifizierung mit dem Server verbunden.
Jetzt, da der Benutzer ‘hadoop‘ erstellt und die passwortlose SSH-Authentifizierung konfiguriert wurde, werden wir die Hadoop-Installation durch Herunterladen des Hadoop-Binärpakets durchführen.
Hadoop herunterladen
Nachdem Sie einen neuen Benutzer erstellt und die passwortlose SSH-Authentifizierung konfiguriert haben, können Sie jetzt das Apache Hadoop-Binärpaket herunterladen und das Installationsverzeichnis dafür einrichten. In diesem Beispiel werden Sie Hadoop v3.3.4 herunterladen, und das Zielinstallationsverzeichnis wird das Verzeichnis ‘/usr/local/hadoop‘ sein.
Führen Sie den folgenden wget-Befehl aus, um das Apache Hadoop-Binärpaket in das aktuelle Arbeitsverzeichnis herunterzuladen. Sie sollten die Datei ‘hadoop-3.3.4.tar.gz‘ in Ihrem aktuellen Arbeitsverzeichnis erhalten.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gzExtrahieren Sie als Nächstes das Apache Hadoop-Paket ‘hadoop-3.3.4.tar.gz’ über den folgenden tar-Befehl. Verschieben Sie dann das extrahierte Verzeichnis nach ‘/usr/local/hadoop‘.
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoopÄndern Sie schließlich den Eigentümer des Hadoop-Installationsverzeichnisses ‘/usr/local/hadoop’ in den Benutzer ‘hadoop‘ und die Gruppe ‘hadoop‘.
sudo chown -R hadoop:hadoop /usr/local/hadoop
In diesem Schritt haben Sie das Apache Hadoop-Binärpaket heruntergeladen und das Hadoop-Installationsverzeichnis konfiguriert. Vor diesem Hintergrund können Sie jetzt mit der Konfiguration der Hadoop-Installation beginnen.
Hadoop-Umgebungsvariablen einrichten
Öffnen Sie die Konfigurationsdatei ‘~/.bashrc‘ über den folgenden nano-Editor-Befehl.
nano ~/.bashrcFügen Sie die folgenden Zeilen in die Datei ein. Stellen Sie sicher, dass Sie die folgenden Zeilen am Ende der Datei platzieren.
# Hadoop-Umgebungsvariablen
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Speichern Sie die Datei und beenden Sie den Editor, wenn Sie fertig sind.
Führen Sie als Nächstes den folgenden Befehl aus, um die neuen Änderungen in der Datei ‘~/.bashrc‘ anzuwenden.
source ~/.bashrcNachdem der Befehl ausgeführt wurde, werden die neuen Umgebungsvariablen angewendet. Sie können dies überprüfen, indem Sie jede Umgebungsvariable über den folgenden Befehl überprüfen. Und Sie sollten die Ausgabe jeder Umgebungsvariable erhalten.
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTSAls Nächstes konfigurieren Sie auch die JAVA_HOME-Umgebungsvariable im Skript ‘hadoop-env.sh‘.
Öffnen Sie die Datei ‘hadoop-env.sh’ mit dem folgenden nano-Editor-Befehl. Die Datei ‘hadoop-env.sh’ ist im Verzeichnis ‘$HADOOP_HOME‘ verfügbar, das auf das Hadoop-Installationsverzeichnis ‘/usr/local/hadoop‘ verweist.
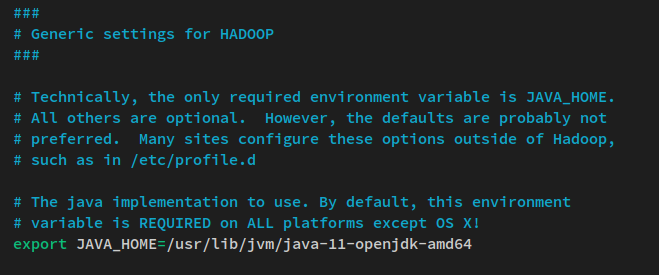
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shKommentieren Sie die JAVA_HOME-Umgebungszeile aus und ändern Sie den Wert auf das Installationsverzeichnis von Java OpenJDK ‘/usr/lib/jvm/java-11-openjdk-amd64‘.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64Speichern Sie die Datei und beenden Sie den Editor, wenn Sie fertig sind.
Mit der Konfiguration der Umgebungsvariablen führen Sie den folgenden Befehl aus, um die Hadoop-Version auf Ihrem System zu überprüfen. Sie sollten Apache Hadoop 3.3.4 auf Ihrem System installiert sehen.
hadoop version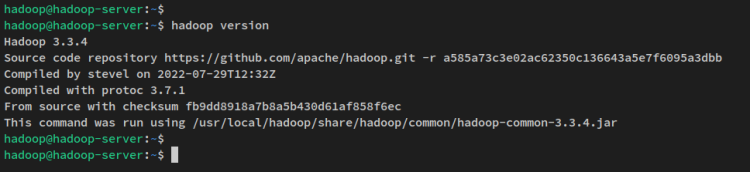
An diesem Punkt sind Sie bereit, das Hadoop-Cluster einzurichten und zu konfigurieren, das in mehreren Modi bereitgestellt werden kann.
Apache Hadoop-Cluster einrichten: Pseudo-Distributed Mode
In Hadoop können Sie ein Cluster in drei verschiedenen Modi erstellen:
- Local Mode (Standalone) - Standard-Hadoop-Installation, die als einzelner Java-Prozess und nicht verteilte Mode ausgeführt wird. Damit können Sie den Hadoop-Prozess einfach debuggen.
- Pseudo-Distributed Mode - Dies ermöglicht es Ihnen, ein Hadoop-Cluster im verteilten Modus auszuführen, selbst mit nur einem einzigen Node/Server. In diesem Modus werden Hadoop-Prozesse in separaten Java-Prozessen ausgeführt.
- Fully-Distributed Mode - große Hadoop-Bereitstellung mit mehreren oder sogar Tausenden von Nodes/Servern. Wenn Sie Hadoop in der Produktion ausführen möchten, sollten Sie Hadoop im vollständig verteilten Modus verwenden.
In diesem Beispiel werden Sie ein Apache Hadoop-Cluster im Pseudo-Distributed Mode auf einem einzelnen Ubuntu-Server einrichten. Dazu werden Sie einige Änderungen an den Hadoop-Konfigurationen vornehmen:
- core-site.xml - Dies wird verwendet, um den NameNode für das Hadoop-Cluster zu definieren.
- hdfs-site.xml - Diese Konfiguration wird verwendet, um den DataNode im Hadoop-Cluster zu definieren.
- mapred-site.xml - Die MapReduce-Konfiguration für das Hadoop-Cluster.
- yarn-site.xml - ResourceManager- und NodeManager-Konfiguration für das Hadoop-Cluster.
NameNode und DataNode einrichten
Zuerst werden Sie den NameNode und den DataNode für das Hadoop-Cluster einrichten.
Öffnen Sie die Datei ‘$HADOOP_HOME/etc/hadoop/core-site.xml‘ mit dem folgenden nano-Editor.
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlFügen Sie die folgenden Zeilen in die Datei ein. Stellen Sie sicher, dass Sie die IP-Adresse des NameNode ändern, oder Sie können sie durch ‘0.0.0.0’ ersetzen, damit der NameNode an allen Schnittstellen und IP-Adressen ausgeführt wird.
fs.defaultFS
hdfs://192.168.5.100:9000
Speichern Sie die Datei und beenden Sie den Editor, wenn Sie fertig sind.
Führen Sie als Nächstes den folgenden Befehl aus, um neue Verzeichnisse zu erstellen, die für den DataNode im Hadoop-Cluster verwendet werden. Ändern Sie dann den Eigentümer der DataNode-Verzeichnisse in den Benutzer ‘hadoop‘.
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsÖffnen Sie danach die Datei ‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’ mit dem folgenden nano-Editor-Befehl.
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlFügen Sie die folgende Konfiguration in die Datei ein. In diesem Beispiel werden Sie das Hadoop-Cluster in einem einzelnen Node einrichten, daher müssen Sie den Wert ‘dfs.replication’ auf ‘1’ ändern. Außerdem müssen Sie das Verzeichnis angeben, das für den DataNode verwendet wird.
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
Speichern Sie die Datei und beenden Sie den Editor, wenn Sie fertig sind.
Mit dem konfigurierten NameNode und DataNode führen Sie den folgenden Befehl aus, um das Hadoop-Dateisystem zu formatieren.
hdfs namenode -formatSie erhalten eine Ausgabe wie diese:
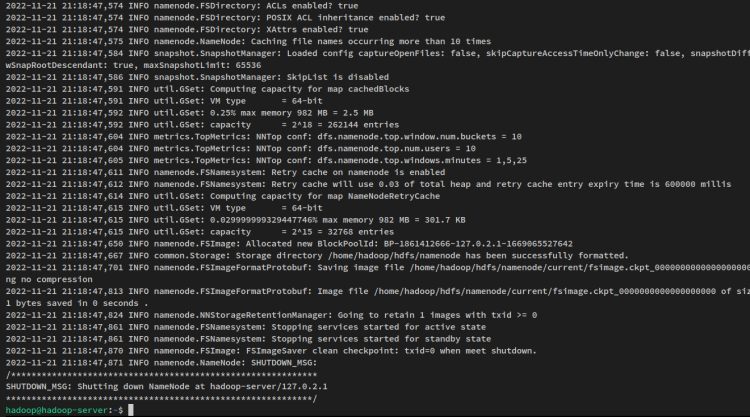
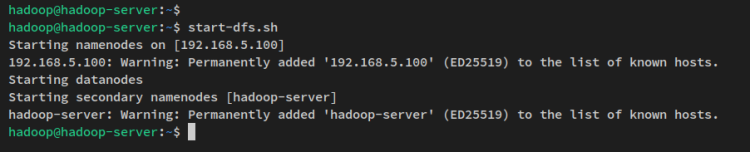
Starten Sie als Nächstes den NameNode und den DataNode über den folgenden Befehl. Der NameNode wird auf der Server-IP-Adresse ausgeführt, die Sie in der Datei ‘core-site.xml’ konfiguriert haben.
start-dfs.shSie werden eine Ausgabe wie diese sehen:
Jetzt, da der NameNode und der DataNode ausgeführt werden, werden Sie beide Prozesse über die Weboberfläche überprüfen.
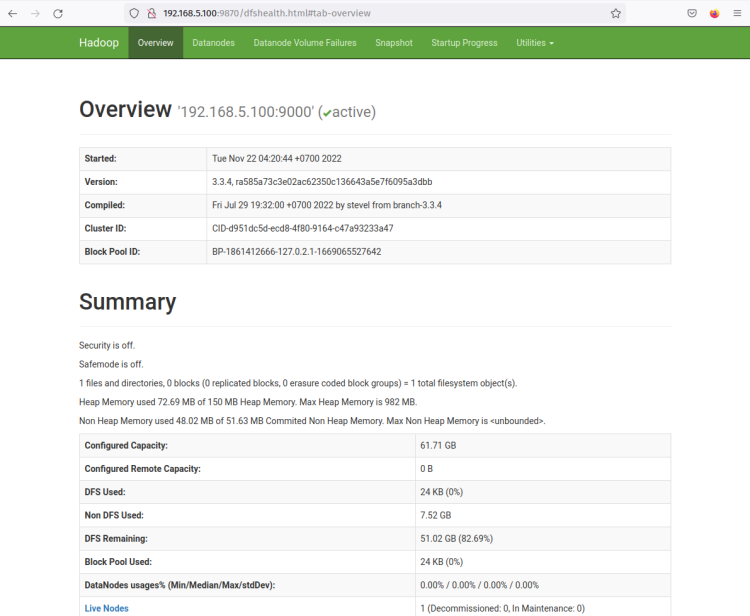
Die Hadoop NameNode-Weboberfläche läuft auf Port ‘9870‘. Öffnen Sie also Ihren Webbrowser und besuchen Sie die Server-IP-Adresse, gefolgt von Port 9870 (z. B.: http://192.168.5.100:9870/).
Sie sollten jetzt die Seite wie im folgenden Screenshot erhalten - Der NameNode ist derzeit aktiv.
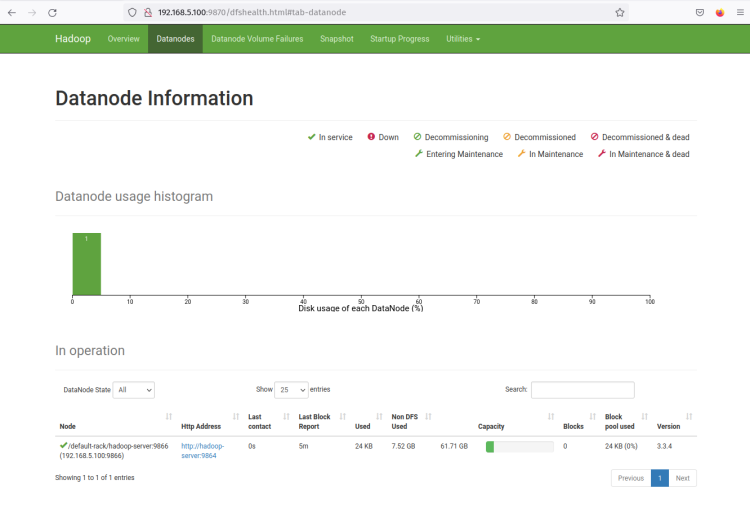
Klicken Sie nun auf das Menü ‘Datanodes’, und Sie sollten den aktuellen DataNode sehen, der im Hadoop-Cluster aktiv ist. Der folgende Screenshot bestätigt, dass der DataNode auf Port ‘9864‘ im Hadoop-Cluster ausgeführt wird.
Klicken Sie auf die ‘ Http-Adresse ‘ des DataNodes, und Sie sollten eine neue Seite mit detaillierten Informationen über den DataNode erhalten. Der folgende Screenshot bestätigt, dass der DataNode mit dem Volumenverzeichnis ‘/home/hadoop/hdfs/datanode‘ ausgeführt wird.
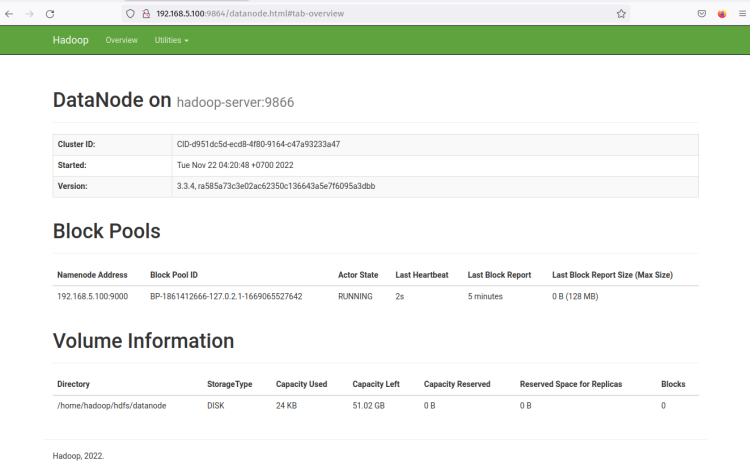
Mit dem laufenden NameNode und DataNode werden Sie als Nächstes MapReduce auf dem Yarn-Manager (Yet Another ResourceManager und NodeManager) einrichten und ausführen.
Yarn-Manager
Um ein MapReduce auf Yarn im Pseudo-Distributed Mode auszuführen, müssen Sie einige Änderungen an den Konfigurationsdateien vornehmen.
Öffnen Sie die Datei ‘$HADOOP_HOME/etc/hadoop/mapred-site.xml‘ mit dem folgenden nano-Editor-Befehl.
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlFügen Sie die folgenden Zeilen in die Datei ein. Stellen Sie sicher, dass Sie den Wert von mapreduce.framework.name auf ‘yarn’ ändern.
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
Speichern Sie die Datei und beenden Sie den Editor, wenn Sie fertig sind.
Öffnen Sie als Nächstes die Yarn-Konfiguration ‘$HADOOP_HOME/etc/hadoop/yarn-site.xml‘ mit dem folgenden nano-Editor-Befehl.
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlÄndern Sie die Standardkonfiguration mit den folgenden Einstellungen.
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
Speichern Sie die Datei und beenden Sie den Editor, wenn Sie fertig sind.
Führen Sie den folgenden Befehl aus, um die Yarn-Daemons zu starten. Und Sie sollten sehen, dass sowohl ResourceManager als auch NodeManager gestartet werden.
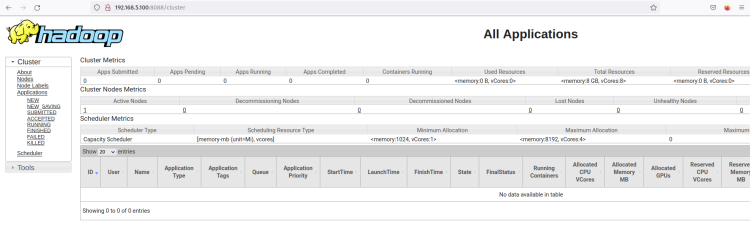
start-yarn.shDer ResourceManager sollte am Standardport 8088 ausgeführt werden. Gehen Sie zurück zu Ihrem Webbrowser und besuchen Sie die Server-IP-Adresse, gefolgt vom ResourceManager-Port ‘8088’ (z. B.: http://192.168.5.100:8088/).
Sie sollten die Weboberfläche des Hadoop ResourceManagers sehen. Von hier aus können Sie alle laufenden Prozesse im Hadoop-Cluster überwachen.
Klicken Sie auf das Menü ‘Nodes’, und Sie sollten die aktuell laufenden Nodes im Hadoop-Cluster sehen.
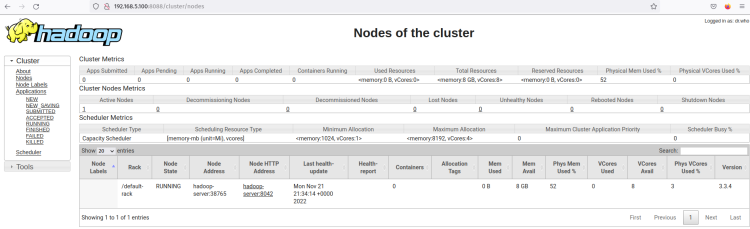
Jetzt läuft das Hadoop-Cluster im Pseudo-Distributed Mode. Das bedeutet, dass jeder Hadoop-Prozess als einzelner Prozess auf einem einzelnen Node-Ubuntu-Server 22.04 ausgeführt wird, einschließlich des NameNode, DataNode, MapReduce und Yarn.
Fazit
In diesem Leitfaden haben Sie Apache Hadoop auf einem einzelnen Ubuntu 22.04-Server installiert. Sie haben Hadoop mit aktiviertem Pseudo-Distributed Mode installiert, was bedeutet, dass jede Hadoop-Komponente als einzelner Java-Prozess auf dem System ausgeführt wird. In diesem Leitfaden haben Sie auch gelernt, wie man Java einrichtet, Systemumgebungsvariablen einrichtet und die passwortlose SSH-Authentifizierung über den SSH-öffentlichen und privaten Schlüssel einrichtet.
Diese Art der Hadoop-Bereitstellung, der Pseudo-Distributed Mode, wird nur für Tests empfohlen. Wenn Sie ein verteiltes System wünschen, das mittelgroße oder große Datensätze verarbeiten kann, können Sie Hadoop im Cluster-Modus bereitstellen, der mehr Computersysteme erfordert und eine hohe Verfügbarkeit für Ihre Anwendung bietet.
Erhalte neue Beiträge in deinem Posteingang.
Kein Spam. Jederzeit abmelden.