Récupération de données · 2 min read · Sep 06, 2025
4 façons de récupérer les pages Web supprimées d'Internet
Il y a quelques jours, un de mes amis sur Twitter, @rivahratt, a tweeté comment la base de données MySQL de son blog Wordpress a planté et son hébergeur (un service d’hébergement gratuit) lui a dit qu’ils ne pouvaient pas l’aider puisqu’il n’est pas un utilisateur PRO. Cela m’a fait poser quelques questions – Que se passe-t-il si votre base de données plante et que vous n’avez aucune sauvegarde ? Que se passe-t-il si un fichier est corrompu lors de la mise à jour de votre Wordpress ? Que se passe-t-il si Blogger.com supprime accidentellement votre blog ainsi que la copie de sauvegarde ?

Eh bien, si quelque chose comme cela vous est arrivé en ce moment, ne perdez pas espoir. Il existe quelques façons de récupérer automatiquement ou manuellement les articles supprimés de votre blog, selon votre préférence et votre temps.
1. Récupérer vos articles de blog supprimés à partir du cache Google
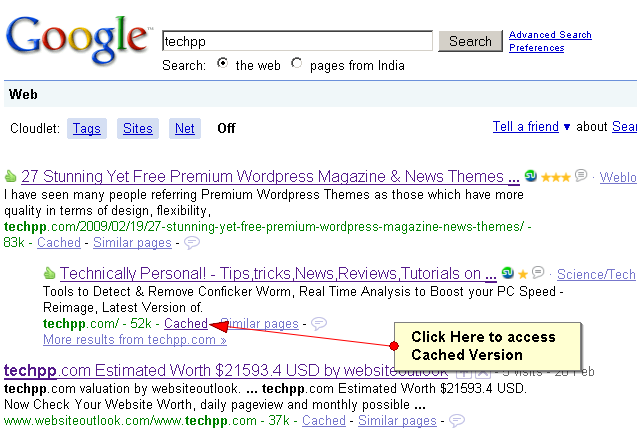
En supposant que vos articles de blog soient indexés sur Google, allez sur la recherche Google et cherchez “ site:votresitename.com “. Cela renverra toutes les pages indexées par Google. Sous chaque article, vous trouverez un lien vers la version “cached” de l’article. Cliquez dessus et copiez tout le contenu. C’est un processus très fastidieux et soyez prêt à fournir beaucoup d’efforts manuels. Brian Cook a un article détaillé expliquant cette procédure.
2. Utiliser Warrick – Outil de récupération automatique de blog
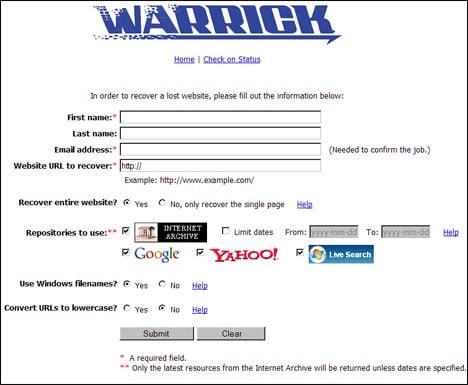
Au lieu de copier manuellement chaque article mis en cache, vous pouvez jeter un œil à Warrick. C’est une application web de récupération de blog automatique qui vous permet de reconstruire n’importe quel site Web perdu (ou page Web unique) automatiquement. Il vous suffit de taper l’URL du site Web et Warrick vous informera par e-mail une fois le processus de récupération terminé. L’outil est essentiellement un robot d’exploration web qui scanne et collecte les pages web manquantes de quatre dépôts web – Internet Archive, Google, Live Search et Yahoo. Si une page web est trouvée dans plus d’un dépôt web, Warrick enregistre la page avec la date la plus récente.
3. Utiliser le cache Firefox pour récupérer un article de blog
Si vous gérez un blog Wordpress, vous voudrez lire cet article de WpHackr sur la façon d’utiliser le cache Firefox pour récupérer un article de blog. Attention, ce n’est pas du tout la méthode la plus facile, c’est plein de tracas mais peut encore être utilisé en dernier recours.
4. Récupérer les articles à partir du flux RSS
C’est quelque chose de très logique et facile. Si vous avez publié vos articles de blog complets en tant que flux RSS, vous pouvez retourner sur feedBurner et commencer à fouiller dans les anciens flux et récupérer les articles de blog individuels. Fouillez dans vos propres articles !!
Que pensez-vous de ces idées ? Avez-vous des alternatives / de meilleures façons ? À quelle fréquence faites-vous la sauvegarde de votre blog ?
Recevez de nouveaux articles dans votre boîte de réception.
Aucun spam. Désabonnez-vous à tout moment.