Cluster haute disponibilité · 12 min read · Nov 10, 2025
Comment déployer un cluster tolérant aux pannes avec disponibilité continue ou haute disponibilité
Certaines entreprises ne peuvent pas se permettre d’avoir leurs services hors ligne. En cas de panne de serveur, un opérateur de téléphonie mobile pourrait connaître une interruption de son système de facturation, entraînant une perte de connexion pour tous ses clients. L’admission de l’impact potentiel de telles situations conduit à l’idée d’avoir toujours un plan B.
Dans cet article, nous mettons en lumière différentes façons de se protéger contre les pannes de serveur, ainsi que les architectures utilisées pour le déploiement de VMmanager Cloud, un panneau de contrôle pour la construction d’un cluster à haute disponibilité.

Préface
La terminologie dans le domaine de la tolérance des clusters diffère d’un site à l’autre. Afin d’éviter de mélanger différents termes et définitions, définissons ceux qui seront utilisés dans cet article :
- La tolérance aux pannes (TP) est la capacité d’un système à continuer son fonctionnement après la défaillance de l’un de ses composants.
- Un cluster est un groupe de serveurs (nœuds de cluster) connectés par des canaux de communication.
- Un cluster tolérant aux pannes (CTP) est un cluster où la défaillance d’un serveur ne conduit pas à l’indisponibilité complète de l’ensemble du cluster. Les fonctions du nœud défaillant sont automatiquement réaffectées entre les nœuds restants.
- La disponibilité continue (AC) signifie qu’un utilisateur peut utiliser le service sans rencontrer de délais. Peu importe combien de temps s’est écoulé depuis la défaillance du nœud.
- La haute disponibilité (HA) signifie qu’un utilisateur peut rencontrer des délais de service si l’un des nœuds tombe en panne ; cependant, le système sera récupéré automatiquement avec un minimum de temps d’arrêt.
- Un cluster AC est un cluster à disponibilité continue.
- Un cluster HA est un cluster à haute disponibilité.
Supposons qu’il soit nécessaire de déployer un cluster composé de 10 nœuds avec des machines virtuelles fonctionnant sur chaque nœud. L’objectif est de protéger les machines virtuelles après la défaillance du serveur. Des serveurs à double CPU sont utilisés pour maximiser la densité de calcul des racks.
À première vue, l’option la plus attrayante pour une entreprise est de déployer un cluster à disponibilité continue lorsque le service est toujours fourni après la défaillance de l’équipement. En effet, la disponibilité continue est indispensable si vous devez maintenir le fonctionnement d’un système de facturation ou automatiser un processus de production continu. Cependant, cette approche a également ses pièges et ses écueils, qui sont abordés ci-dessous.
Disponibilité continue
La continuité d’un service n’est réalisable que si une copie exacte d’une machine physique ou virtuelle avec ce service est construite, qui est disponible à tout moment. Ce modèle de redondance est appelé 2N. Créer une copie du serveur après la défaillance de l’équipement prendrait du temps, entraînant un délai de service. De plus, dans ce cas, il ne serait pas possible de récupérer le dump de RAM du serveur défaillant, ce qui signifie que toutes les informations qu’il contenait seraient perdues.
Il existe deux méthodes utilisées pour fournir l’AC : au niveau matériel et au niveau logiciel. Concentrons-nous sur chacune d’elles plus en détail.
La méthode matérielle représente un serveur double où tous les composants sont dupliqués et les calculs sont exécutés simultanément et indépendamment. La synchronisation est réalisée à l’aide d’un nœud dédié qui vérifie les résultats provenant des deux parties. Si le nœud détecte une quelconque incohérence, il essaie de définir le problème et de corriger les erreurs. Si l’erreur ne peut pas être corrigée, le système éteint le module défaillant.
Stratus, un fabricant de serveurs AC, garantit que le temps d’arrêt global du système ne dépasse pas 32 secondes par an. De tels résultats peuvent être obtenus en utilisant un équipement spécial. Selon les représentants de Stratus, le coût d’un serveur AC avec des CPU doubles pour chaque module synchronisé est d’environ 160 000 $, selon les spécifications. Le prix total pour l’ensemble du cluster AC dans ce cas serait de 1 600 000 $.
La méthode logicielle
L’outil logiciel le plus populaire pour le déploiement d’un cluster à disponibilité continue au moment de l’article est VMware vSphere. La technologie de disponibilité continue de ce produit est appelée tolérance aux pannes.
Contrairement à la méthode matérielle, cette technologie a certaines exigences, telles que les suivantes :
- CPU sur l’hôte physique : - Intel avec architecture Sandy Bridge (ou plus récente). Avoton n’est pas pris en charge.
- AMD Bulldozer (ou plus récent).
- Les machines avec tolérance aux pannes doivent être connectées à un réseau 10 Gb avec faible latence. VMware recommande fortement d’utiliser un réseau dédié.
- Pas plus de 4 CPU virtuels par VM.
- Pas plus de 8 CPU virtuels par hôte physique.
- Pas plus de 4 machines virtuelles par hôte physique.
- Les instantanés de machines virtuelles ne sont pas disponibles.
- Le stockage vMotion n’est pas disponible.
La liste complète des limitations et des incompatibilités peut être trouvée dans la documentation officielle.
La licence vSphere est basée sur les CPU physiques. Le prix commence à 1750 $ par licence + 550 $ pour l’abonnement annuel et le support. L’automatisation de la gestion du cluster nécessite également VMware vCenter Server qui coûte plus de 8000 $. Le modèle 2N est utilisé pour fournir la disponibilité continue, il est donc nécessaire d’acheter 10 serveurs répliqués avec des licences pour chacun d’eux afin de construire un cluster avec 10 nœuds avec des machines virtuelles.
Le coût total du logiciel serait 2[ Nombre de CPU par serveur ](10[ Nombre de nœuds avec machines virtuelles ]+10[ Nombre de nœuds répliqués ])(1750+550)[ Coût de la licence par CPU ]+8000[ Coût de VMware vCenter Server ]=100 000 $. Tous les prix sont arrondis.
Les configurations spécifiques des nœuds ne sont pas décrites dans cet article car les composants des serveurs diffèrent toujours en fonction de l’objectif du cluster. L’équipement réseau n’est également pas décrit car il doit être identique dans tous les cas. Cet article se concentre sur les composants qui varieraient certainement, à savoir le coût de la licence.
Il est également important de mentionner les produits qui ne sont plus développés et pris en charge.
Le produit appelé Remus est basé sur la virtualisation Xen. C’est une solution open source gratuite qui utilise la technologie de micro instantané. Malheureusement, sa documentation n’a pas été mise à jour depuis longtemps : le guide d’installation fournit des instructions pour Ubuntu 12.10 dont la fin de vie a été annoncée en 2014. Même la recherche Google n’a pas trouvé d’entreprise utilisant Remus pour ses opérations.
Des tentatives ont été faites pour modifier QEMU afin de construire des clusters à disponibilité continue sur cette technologie. Il existe deux projets qui ont annoncé leur travail dans ce sens.
Le premier est Kemari, un produit open source dirigé par Yoshiaki Tamura. Ce projet avait l’intention d’utiliser la migration en direct de QEMU. Le dernier commit a été effectué en février 2011, ce qui suggère que le développement a atteint une impasse et ne sera pas poursuivi.
Le deuxième produit est Micro Checkpointing, un projet open source fondé par Michael Hines. Aucune activité n’a été trouvée dans son changelog au cours de la dernière année, ce qui ressemble au projet Kemari.
Ces faits nous permettent de conclure qu’il n’y a tout simplement pas de possibilité de disponibilité continue sur la virtualisation KVM à ce jour.
Malgré tous les avantages des systèmes de disponibilité continue, il existe de nombreux obstacles à la mise en œuvre et à l’exploitation de telles solutions. Néanmoins, dans certains cas, la tolérance aux pannes peut être requise, mais sans la nécessité d’être continuellement disponible. De tels scénarios permettent d’utiliser des clusters à haute disponibilité.
Haute disponibilité
Un cluster à haute disponibilité fournit une tolérance aux pannes en détectant automatiquement si le matériel est hors service et en lançant ensuite le service sur le nœud disponible.
La haute disponibilité ne prend pas en charge la synchronisation des CPU lancés sur les nœuds et ne permet pas toujours de synchroniser les disques locaux. Dans cet esprit, il est recommandé de localiser les disques utilisés par les nœuds dans un stockage indépendant séparé tel qu’un stockage en réseau.
La raison est claire : le nœud ne peut pas être atteint après sa défaillance, et les informations de son dispositif de stockage ne peuvent pas être récupérées. Le système de stockage de données doit également être tolérant aux pannes, sinon il n’y a pas de possibilité de haute disponibilité. En conséquence, le cluster à haute disponibilité se compose de deux sous-clusters :
- Cluster de calcul composé de nœuds avec des machines virtuelles
- Cluster de stockage avec des disques utilisés par les nœuds de calcul.
À l’heure actuelle, les solutions suivantes sont utilisées pour mettre en œuvre des clusters à haute disponibilité avec des machines virtuelles sur des nœuds de cluster :
- Heartbeat, version 1.? avec DRBD ;
- Pacemaker ;
- VMware vSphere ;
- Proxmox VE ;
- XenServer ;
- OpenStack ;
- oVirt ;
- Red Hat Enterprise Virtualization ;
- Windows Server Failover Clustering avec le rôle de serveur Hyper-V ;
- VMmanager Cloud.
Examinons de plus près VMmanager Cloud.
VMmanager Cloud
VMmanager Cloud est un produit qui permet de déployer des clusters à haute disponibilité et utilise la virtualisation QEMU-KVM. Cette technologie a été choisie car elle est activement développée et prise en charge et permet d’installer n’importe quel système d’exploitation sur une machine virtuelle. Le produit utilise Corosync pour détecter la disponibilité du cluster. Si l’un des serveurs est hors service, VMmanager distribue ses machines virtuelles entre les nœuds restants un par un.
De manière simplifiée, ce mécanisme fonctionne comme suit :
- Le système identifie le nœud du cluster avec le plus petit nombre de machines virtuelles.
- Il vérifie s’il y a suffisamment de RAM pour localiser la machine.
- S’il y a suffisamment de mémoire sur un nœud pour la machine concernée, VMmanager crée une nouvelle machine virtuelle sur ce nœud.
- S’il n’y a pas assez de mémoire, le système vérifie les autres nœuds avec plus de machines virtuelles.
Des tests de plusieurs configurations matérielles et des enquêtes auprès de nombreux utilisateurs actuels de VMmanager Cloud ont identifié qu’il faut normalement entre 45 et 90 secondes pour distribuer et restaurer le fonctionnement de toutes les VM du nœud défaillant, selon les performances de l’équipement.
Il est recommandé de dédier un ou plusieurs nœuds comme protection contre les situations d’urgence et de ne pas déployer de VM sur ces nœuds pendant le fonctionnement normal. Cela minimise les chances de manquer de ressources sur les nœuds de cluster actifs pour ajouter des machines virtuelles du nœud défaillant. Dans le cas où un seul nœud de sauvegarde est utilisé, ce modèle de sécurité est appelé N+1.
VMmanager Cloud prend en charge les types de stockage suivants : système de fichiers, LVM, LVM réseau, iSCSI et Ceph [en particulier RBD (RADOS Block Device), l’une des implémentations de Ceph]. Les trois derniers sont utilisés pour la haute disponibilité.
Une licence à vie pour dix nœuds opérationnels et un nœud de sauvegarde coûte 3520 €, soit 3865 $ à ce jour (une licence coûte 320 € par nœud, indépendamment du nombre de CPU). La licence comprend un an de mises à jour gratuites ; à partir de la deuxième année, les mises à jour sont fournies selon un modèle d’abonnement au prix de 880 € par an pour l’ensemble du cluster.
Voyons comment VMmanager Cloud a déjà été utilisé pour le déploiement de clusters à haute disponibilité.
FirstByte
FirstByte a commencé à fournir un hébergement cloud en février 2016. Initialement, leur cluster était construit sur OpenStack ; cependant, le manque de spécialistes pour ce système en termes de disponibilité et de coût les a poussés à chercher une solution alternative. Le nouveau système de construction d’un cluster à haute disponibilité devait répondre aux exigences suivantes :
- Capacité à déployer des machines virtuelles KVM.
- Intégration avec Ceph.
- Intégration avec un système de facturation pour offrir les services existants.
- Coût de licence abordable.
- Support du développeur de logiciels.
VMmanager Cloud répondait à toutes les exigences.
Caractéristiques distinctives du cluster FirstByte :
- Le transfert de données est basé sur la technologie Ethernet et l’équipement Cisco.
- Le routage est effectué à l’aide de Cisco ASR9001. Le cluster utilise environ 50000 adresses IPv6.
- La vitesse de lien entre les nœuds de calcul et les commutateurs est de 10 Gbps.
- La vitesse de transfert de données entre les commutateurs et les nœuds de stockage est de 20 Gbps, avec deux canaux combinés de 10 Gbps chacun.
- Un lien séparé de 20 Gbps est utilisé entre les racks avec des nœuds de stockage pour la réplication.
- Des disques SAS en combinaison avec des SSD sont installés sur tous les nœuds de stockage.
- Le type de stockage est RBD.
La disposition du système est présentée ci-dessous :
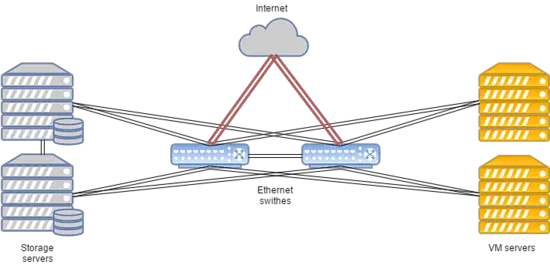
Cette configuration fonctionne pour l’hébergement de sites Web populaires, de serveurs de jeux et de bases de données avec une charge supérieure à la moyenne.
FirstVDS
FirstVDS fournit des services de cluster tolérant aux pannes qui ont été lancés en septembre 2015.
VMmanager Cloud a été choisi pour ce cluster en raison des facteurs suivants :
- Solide expérience d’utilisation des panneaux de contrôle ISPsystem.
- Intégration avec BILLmanager par défaut.
- Haute qualité du support technique.
- Intégration avec Ceph.
Leur cluster a les caractéristiques suivantes :
- Le transfert de données est basé sur un réseau Infiniband avec une vitesse de connexion de 56 Gbps ;
- Le réseau Infiniband est construit sur l’équipement Mellanox ;
- Les nœuds de stockage ont des disques SSD ;
- Le type de stockage est RBD.
Le système peut être disposé de la manière suivante :
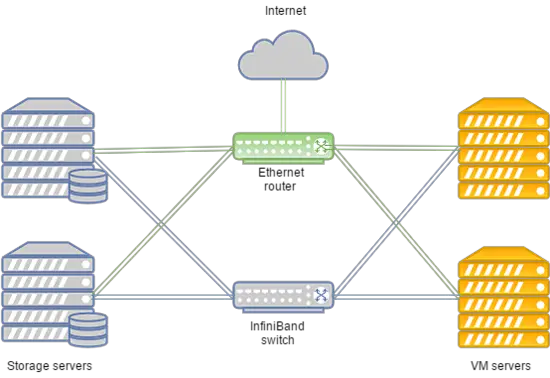
En cas de défaillance du réseau Infiniband, la connexion entre le stockage de disque VM et les serveurs de calcul est établie via un réseau Ethernet déployé sur l’équipement Juniper. La nouvelle connexion est configurée automatiquement.
En raison de la haute vitesse de communication avec le stockage, ce cluster fonctionne parfaitement pour l’hébergement de sites Web avec un trafic ultra-élevé, de la diffusion vidéo et de contenu, ainsi que de grandes données.
Conclusion
Récapitulons les principales conclusions de l’article.
Le cluster à disponibilité continue est indispensable lorsque chaque seconde d’arrêt entraîne des pertes substantielles. S’il est permis d’avoir une panne de 5 minutes lors du déploiement de machines virtuelles sur un nœud de sauvegarde, le cluster à haute disponibilité peut être une bonne option réduisant les coûts matériels et logiciels.
Il est également important de rappeler que le seul moyen d’atteindre la tolérance aux pannes est l’excès. Assurez-vous de répliquer vos serveurs, équipements de communication de données et liens, canaux d’accès Internet et alimentation. Répliquez tout ce que vous pouvez. De telles mesures permettent d’éliminer les goulets d’étranglement et les points de défaillance potentiels qui peuvent entraîner l’arrêt complet du système. En prenant les mesures ci-dessus, vous pouvez être sûr que vous disposez d’un cluster tolérant aux pannes résistant aux défaillances.
Si vous pensez que le modèle de haute disponibilité correspond à vos exigences et que VMmanager Cloud est un bon outil pour le réaliser, veuillez vous référer au manuel d’installation et à la documentation pour en savoir plus sur le système. Je vous souhaite des opérations sans pannes et continues !**
Recevez de nouveaux articles dans votre boîte de réception.
Aucun spam. Désabonnez-vous à tout moment.