Hadoop Installation · 12 min read · Dec 21, 2025
Comment installer Apache Hadoop sur Ubuntu 22.04

Apache Hadoop est un cadre open-source pour le traitement et le stockage de grandes données. Dans les industries d’aujourd’hui, Hadoop est devenu le cadre standard pour les grandes données. Hadoop est conçu pour être exécuté sur des systèmes distribués avec des centaines, voire des milliers d’ordinateurs regroupés ou de serveurs dédiés. Avec cela à l’esprit, Hadoop peut gérer de grands ensembles de données avec un volume et une complexité élevés pour les données structurées et non structurées.
Chaque déploiement Hadoop contient les composants suivants :
- Hadoop Common : Les utilitaires communs qui soutiennent les autres modules Hadoop.
- Hadoop Distributed File System (HDFS) : Un système de fichiers distribué qui fournit un accès à haut débit aux données d’application.
- Hadoop YARN : Un cadre pour la planification des tâches et la gestion des ressources du cluster.
- Hadoop MapReduce : Un système basé sur YARN pour le traitement parallèle de grands ensembles de données.
Dans ce tutoriel, nous allons installer la dernière version d’Apache Hadoop sur un serveur Ubuntu 22.04. Hadoop est installé sur un serveur à nœud unique et nous créons un mode pseudo-distribué de déploiement Hadoop.
Prérequis
Pour compléter ce guide, vous aurez besoin des exigences suivantes :
- Un serveur Ubuntu 22.04 - Cet exemple utilise un serveur Ubuntu avec le nom d’hôte ‘hadoop’ et l’adresse IP ‘192.168.5.100’.
- Un utilisateur non-root avec des privilèges d’administrateur sudo/root.
Installation de Java OpenJDK
Hadoop est un énorme projet sous la Fondation Apache Software, il est principalement écrit en Java. Au moment de la rédaction de cet article, la dernière version de Hadoop est v3.3.4, qui est entièrement compatible avec Java v11.
Le Java OpenJDK 11 est disponible par défaut dans le dépôt Ubuntu, et vous l’installerez via APT.
Pour commencer, exécutez la commande apt ci-dessous pour mettre à jour et rafraîchir les listes de paquets/dépôts sur votre système Ubuntu.
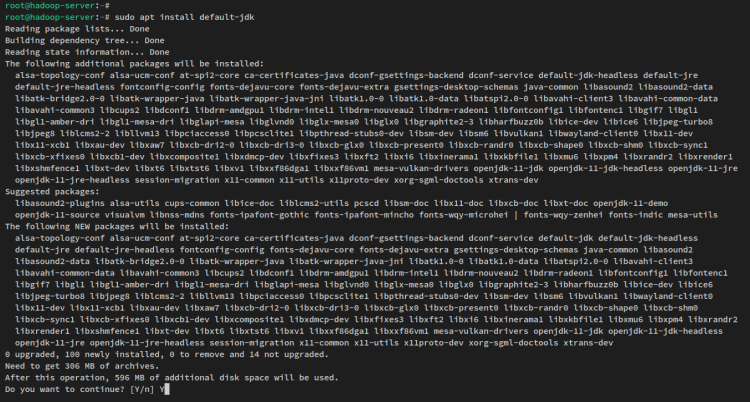
sudo apt updateMaintenant, installez le Java OpenJDK 11 via la commande apt ci-dessous. Dans le dépôt Ubuntu 22.04, le paquet ‘default-jdk’ fait référence à Java OpenJDK v11.
sudo apt install default-jdkLorsque vous y êtes invité, saisissez y pour confirmer et appuyez sur ENTRÉE pour continuer. L’installation de Java OpenJDK va commencer.
Après l’installation de Java, exécutez la commande ci-dessous pour vérifier la version de Java. Vous devriez obtenir le Java OpenJDK 11 installé sur votre système Ubuntu.
java -versionMaintenant que le Java OpenJDK est installé, vous allez configurer un nouvel utilisateur avec une authentification SSH sans mot de passe qui sera utilisé pour exécuter les processus et services Hadoop.
Configuration de l’utilisateur et de l’authentification SSH sans mot de passe
Apache Hadoop nécessite que le service SSH soit en cours d’exécution sur le système. Cela sera utilisé par les scripts Hadoop pour gérer le démon Hadoop distant sur le serveur distant. Dans cette étape, vous allez créer un nouvel utilisateur qui sera utilisé pour exécuter les processus et services Hadoop, puis configurer l’authentification SSH sans mot de passe.
Au cas où vous n’auriez pas SSH installé sur votre système, exécutez la commande apt ci-dessous pour installer SSH. Le paquet ‘pdsh‘ est un client de shell distant multithread qui vous permet d’exécuter des commandes sur plusieurs hôtes en mode parallèle.
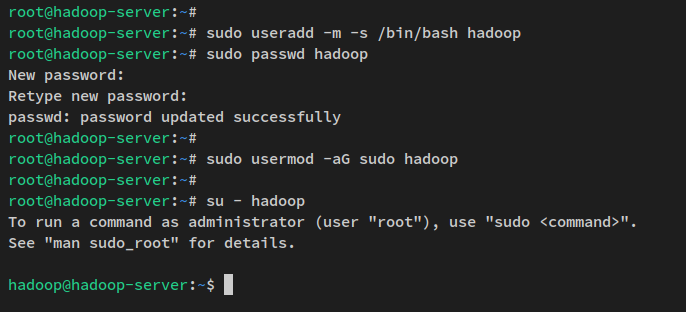
sudo apt install openssh-server openssh-client pdshMaintenant, exécutez la commande ci-dessous pour créer un nouvel utilisateur ‘hadoop’ et configurer le mot de passe pour l’utilisateur ‘hadoop’.
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoopSaisissez le nouveau mot de passe pour l’utilisateur ‘hadoop‘ et répétez le mot de passe.
Ensuite, ajoutez l’utilisateur ‘hadoop’ au groupe ‘sudo‘ via la commande usermod ci-dessous. Cela permet à l’utilisateur ‘hadoop’ d’exécuter la commande ‘sudo’.
sudo usermod -aG sudo hadoopMaintenant que l’utilisateur ‘hadoop’ est créé, connectez-vous à l’utilisateur ‘hadoop‘ via la commande ci-dessous.
su - hadoopAprès vous être connecté, votre invite deviendra comme ceci : “ hadoop@hostname.. “.
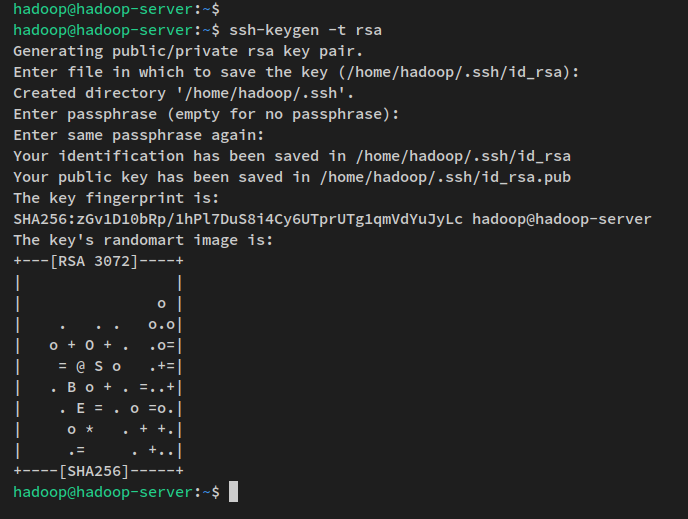
Ensuite, exécutez la commande ci-dessous pour générer une clé SSH publique et privée. Lorsque vous êtes invité à configurer le mot de passe pour la clé, appuyez sur ENTRÉE pour passer.
ssh-keygen -t rsaLa clé SSH est maintenant générée dans le répertoire ~/.ssh. Le fichier id_rsa.pub est la clé publique SSH et le fichier ‘id_rsa’ est la clé privée.
Vous pouvez vérifier la clé SSH générée via la commande suivante.
ls ~/.ssh/Ensuite, exécutez la commande ci-dessous pour copier la clé publique SSH ‘id_rsa.pub‘ dans le fichier ‘authorized_keys‘ et changer la permission par défaut à 600.
Dans ssh, le fichier ‘authorized_keys‘ est l’endroit où vous stockez la clé publique ssh, qui peut être plusieurs clés publiques. Quiconque possède la clé publique stockée dans le fichier ‘authorized_keys‘ et a la bonne clé privée pourra se connecter au serveur en tant qu’utilisateur ‘hadoop‘ sans mot de passe.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys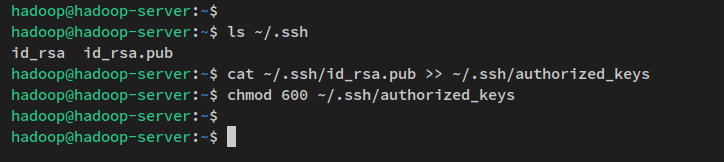
Avec la configuration SSH sans mot de passe terminée, vous pouvez vérifier en vous connectant à la machine locale via la commande ssh ci-dessous.
ssh localhostSaisissez oui pour confirmer et ajouter l’empreinte SSH et vous serez connecté au serveur sans authentification par mot de passe.
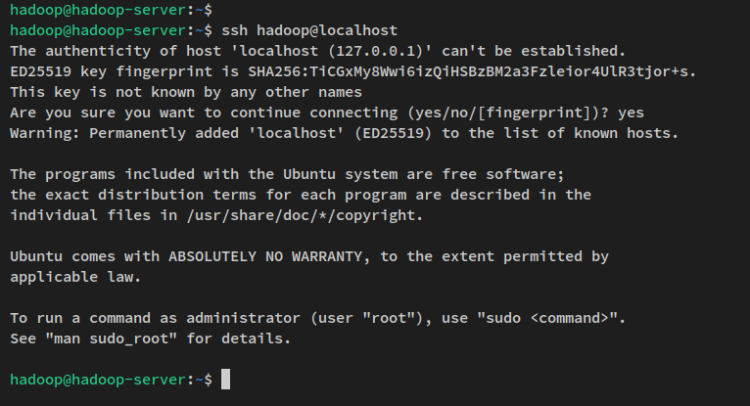
Maintenant que l’utilisateur ‘hadoop‘ est créé et que l’authentification SSH sans mot de passe est configurée, vous allez passer à l’installation de Hadoop en téléchargeant le paquet binaire Hadoop.
Téléchargement de Hadoop
Après avoir créé un nouvel utilisateur et configuré l’authentification SSH sans mot de passe, vous pouvez maintenant télécharger le paquet binaire Apache Hadoop et configurer le répertoire d’installation pour celui-ci. Dans cet exemple, vous allez télécharger Hadoop v3.3.4 et le répertoire d’installation cible sera le répertoire ‘/usr/local/hadoop‘.
Exécutez la commande wget ci-dessous pour télécharger le paquet binaire Apache Hadoop dans le répertoire de travail actuel. Vous devriez obtenir le fichier ‘hadoop-3.3.4.tar.gz‘ dans votre répertoire de travail actuel.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gzEnsuite, extrayez le paquet Apache Hadoop ‘hadoop-3.3.4.tar.gz’ via la commande tar ci-dessous. Ensuite, déplacez le répertoire extrait vers ‘/usr/local/hadoop‘.
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoopEnfin, changez la propriété du répertoire d’installation de Hadoop ‘/usr/local/hadoop’ à l’utilisateur ‘hadoop‘ et au groupe ‘hadoop‘.
sudo chown -R hadoop:hadoop /usr/local/hadoop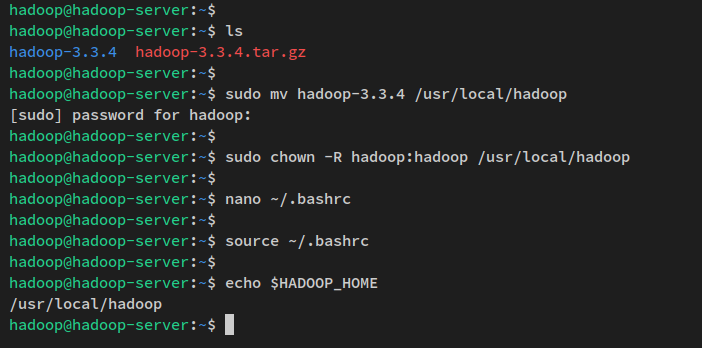
Dans cette étape, vous avez téléchargé le paquet binaire Apache Hadoop et configuré le répertoire d’installation de Hadoop. Avec cela à l’esprit, vous pouvez maintenant commencer à configurer l’installation de Hadoop.
Configuration des variables d’environnement Hadoop
Ouvrez le fichier de configuration ‘~/.bashrc‘ via la commande de l’éditeur nano ci-dessous.
nano ~/.bashrcAjoutez les lignes suivantes au fichier. Assurez-vous de placer les lignes suivantes à la fin du fichier.
# Variables d'environnement Hadoop
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Enregistrez le fichier et quittez l’éditeur lorsque vous avez terminé.
Ensuite, exécutez la commande ci-dessous pour appliquer les nouvelles modifications dans le fichier ‘~/.bashrc‘.
source ~/.bashrcAprès l’exécution de la commande, les nouvelles variables d’environnement seront appliquées. Vous pouvez vérifier en vérifiant chaque variable d’environnement via la commande ci-dessous. Et vous devriez obtenir la sortie de chaque variable d’environnement.
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTSEnsuite, vous allez également configurer la variable d’environnement JAVA_HOME dans le script ‘hadoop-env.sh‘.
Ouvrez le fichier ‘hadoop-env.sh’ en utilisant la commande de l’éditeur nano suivante. Le fichier ‘hadoop-env.sh’ est disponible dans le répertoire ‘$HADOOP_HOME‘, qui fait référence au répertoire d’installation de Hadoop ‘/usr/local/hadoop‘.
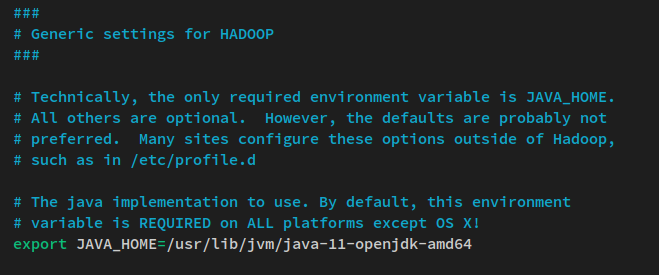
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shDécommentez la ligne d’environnement JAVA_HOME et changez la valeur pour le répertoire d’installation de Java OpenJDK ‘/usr/lib/jvm/java-11-openjdk-amd64‘.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64Enregistrez le fichier et quittez l’éditeur lorsque vous avez terminé.
Avec la configuration des variables d’environnement, exécutez la commande ci-dessous pour vérifier la version de Hadoop sur votre système. Vous devriez voir Apache Hadoop 3.3.4 installé sur votre système.
hadoop version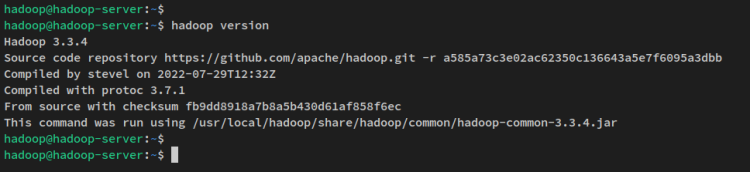
À ce stade, vous êtes prêt à configurer et à déployer le cluster Hadoop, qui peut être déployé en plusieurs modes.
Configuration du cluster Apache Hadoop : Mode Pseudo-Distribué
Dans Hadoop, vous pouvez créer un cluster en trois modes différents :
- Mode Local (Standalone) - installation Hadoop par défaut, qui est exécutée comme un seul processus Java et en mode non distribué. Avec cela, vous pouvez facilement déboguer le processus Hadoop.
- Mode Pseudo-Distribué - Cela vous permet d’exécuter un cluster Hadoop en mode distribué même avec un seul nœud/serveur. Dans ce mode, les processus Hadoop seront exécutés dans des processus Java séparés.
- Mode Entièrement Distribué - déploiement Hadoop important avec plusieurs, voire des milliers de nœuds/serveurs. Si vous souhaitez exécuter Hadoop en production, vous devez utiliser Hadoop en mode entièrement distribué.
Dans cet exemple, vous allez configurer un cluster Apache Hadoop avec le mode Pseudo-Distribué sur un seul serveur Ubuntu. Pour ce faire, vous allez apporter des modifications à certaines des configurations Hadoop :
- core-site.xml - Cela sera utilisé pour définir le NameNode pour le cluster Hadoop.
- hdfs-site.xml - Cette configuration sera utilisée pour définir le DataNode sur le cluster Hadoop.
- mapred-site.xml - La configuration MapReduce pour le cluster Hadoop.
- yarn-site.xml - Configuration ResourceManager et NodeManager pour le cluster Hadoop.
Configuration du NameNode et du DataNode
Tout d’abord, vous allez configurer le NameNode et le DataNode pour le cluster Hadoop.
Ouvrez le fichier ‘$HADOOP_HOME/etc/hadoop/core-site.xml‘ en utilisant l’éditeur nano suivant.
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlAjoutez les lignes ci-dessous au fichier. Assurez-vous de changer l’adresse IP du NameNode, ou vous pouvez la remplacer par ‘0.0.0.0’ afin que le NameNode soit exécuté sur toutes les interfaces et adresses IP.
fs.defaultFS
hdfs://192.168.5.100:9000
Enregistrez le fichier et quittez l’éditeur lorsque vous avez terminé.
Ensuite, exécutez la commande suivante pour créer de nouveaux répertoires qui seront utilisés pour le DataNode sur le cluster Hadoop. Ensuite, changez la propriété des répertoires DataNode à l’utilisateur ‘hadoop‘.
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsAprès cela, ouvrez le fichier ‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’ en utilisant la commande de l’éditeur nano ci-dessous.
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlAjoutez la configuration suivante au fichier. Dans cet exemple, vous allez configurer le cluster Hadoop sur un seul nœud, donc vous devez changer la valeur ‘dfs.replication’ à ‘1’. De plus, vous devez spécifier le répertoire qui sera utilisé pour le DataNode.
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
Enregistrez le fichier et quittez l’éditeur lorsque vous avez terminé.
Avec le NameNode et le DataNode configurés, exécutez la commande ci-dessous pour formater le système de fichiers Hadoop.
hdfs namenode -formatVous recevrez une sortie comme celle-ci :
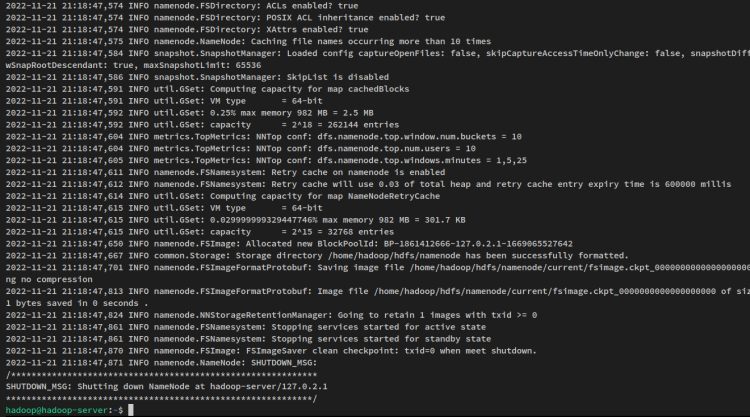
Ensuite, démarrez le NameNode et le DataNode via la commande suivante. Le NameNode sera exécuté sur l’adresse IP du serveur que vous avez configurée dans le fichier ‘core-site.xml’.
start-dfs.shVous verrez une sortie comme celle-ci :
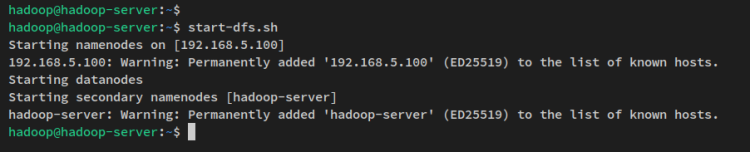
Maintenant que le NameNode et le DataNode sont en cours d’exécution, vous allez vérifier les deux processus via l’interface web.
L’interface web du NameNode Hadoop fonctionne sur le port ‘9870‘. Donc, ouvrez votre navigateur web et visitez l’adresse IP du serveur suivie du port 9870 (c’est-à-dire : http://192.168.5.100:9870/).
Vous devriez maintenant obtenir la page comme la capture d’écran suivante - Le NameNode est actuellement actif.
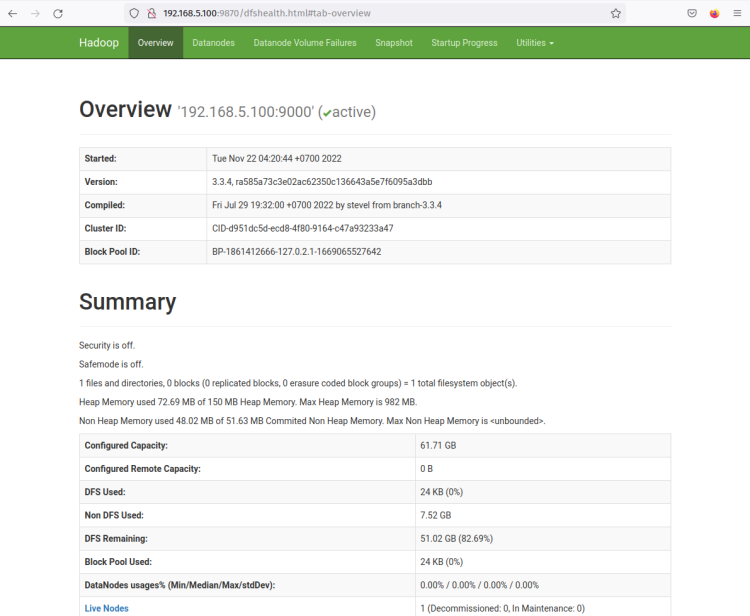
Maintenant, cliquez sur le menu ‘Datanodes’ et vous devriez obtenir le DataNode actuel qui est actif sur le cluster Hadoop. La capture d’écran suivante confirme que le DataNode fonctionne sur le port ‘9864‘ sur le cluster Hadoop.
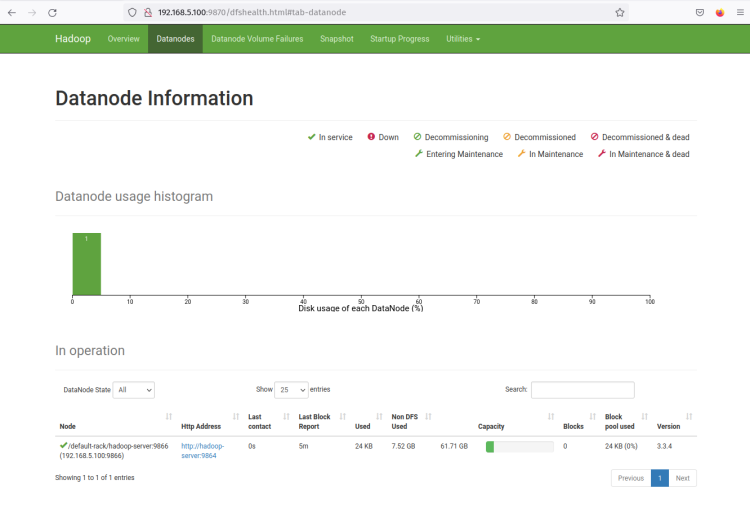
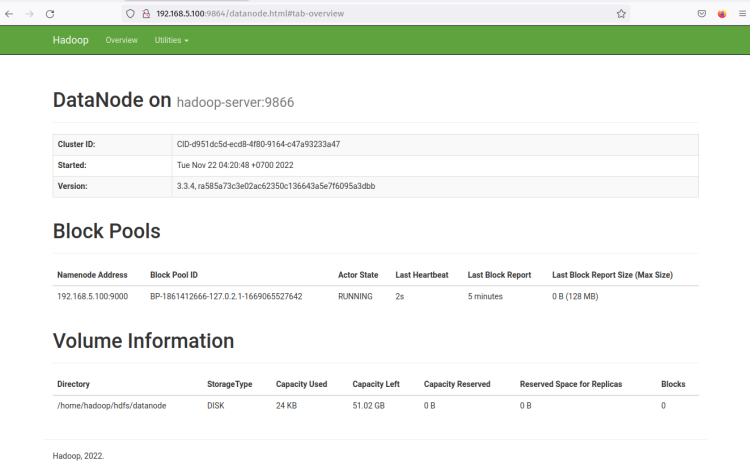
Cliquez sur l’Adresse Http du DataNode et vous devriez obtenir une nouvelle page avec des informations détaillées sur le DataNode. La capture d’écran suivante confirme que le DataNode fonctionne avec le répertoire de volume ‘/home/hadoop/hdfs/datanode‘.
Avec le NameNode et le DataNode en cours d’exécution, vous allez ensuite configurer et exécuter MapReduce sur le gestionnaire Yarn (Yet Another ResourceManager et NodeManager).
Gestionnaire Yarn
Pour exécuter un MapReduce sur Yarn en mode pseudo-distribué, vous devez apporter quelques modifications aux fichiers de configuration.
Ouvrez le fichier ‘$HADOOP_HOME/etc/hadoop/mapred-site.xml‘ en utilisant la commande de l’éditeur nano suivante.
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlAjoutez les lignes ci-dessous au fichier. Assurez-vous de changer le mapreduce.framework.name à ‘yarn’.
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
Enregistrez le fichier et quittez l’éditeur lorsque vous avez terminé.
Ensuite, ouvrez la configuration Yarn ‘$HADOOP_HOME/etc/hadoop/yarn-site.xml‘ en utilisant la commande de l’éditeur nano suivante.
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlChangez la configuration par défaut avec les paramètres suivants.
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
Enregistrez le fichier et quittez l’éditeur lorsque vous avez terminé.
Maintenant, exécutez la commande ci-dessous pour démarrer les démons Yarn. Et vous devriez voir à la fois ResourceManager et NodeManager démarrer.
start-yarn.shLe ResourceManager devrait fonctionner sur le port par défaut 8088. Retournez à votre navigateur web et visitez l’adresse IP du serveur suivie du port ResourceManager ‘8088’ (c’est-à-dire : http://192.168.5.100:8088/).
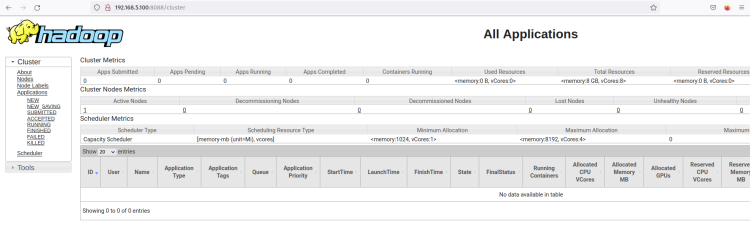
Vous devriez voir l’interface web du ResourceManager Hadoop. À partir de là, vous pouvez surveiller tous les processus en cours d’exécution à l’intérieur du cluster Hadoop.
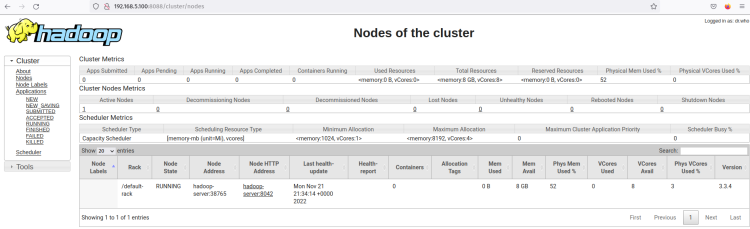
Cliquez sur le menu Nodes et vous devriez obtenir le nœud en cours d’exécution actuel sur le cluster Hadoop.
Maintenant, le cluster Hadoop fonctionne en mode pseudo-distribué. Cela signifie que chaque processus Hadoop fonctionne comme un seul processus sur un serveur Ubuntu 22.04 à nœud unique, ce qui inclut le NameNode, le DataNode, MapReduce et Yarn.
Conclusion
Dans ce guide, vous avez installé Apache Hadoop sur un serveur Ubuntu 22.04 à machine unique. Vous avez installé Hadoop avec le mode Pseudo-Distribué activé, ce qui signifie que chaque composant Hadoop fonctionne comme un seul processus Java sur le système. Dans ce guide, vous avez également appris à configurer Java, à configurer les variables d’environnement système et à configurer l’authentification SSH sans mot de passe via une clé publique-privée SSH.
Ce type de déploiement Hadoop, le mode Pseudo-Distribué, est recommandé uniquement pour les tests. Si vous souhaitez un système distribué capable de gérer des ensembles de données moyens ou importants, vous pouvez déployer Hadoop en mode Cluster, ce qui nécessite plus de systèmes informatiques et offre une haute disponibilité pour votre application.
Recevez de nouveaux articles dans votre boîte de réception.
Aucun spam. Désabonnez-vous à tout moment.