Intégration système · 9 min read · Oct 18, 2025
Intégration d'Ubuntu Landscape avec Opsview Enterprise
Intégration d’Ubuntu Landscape avec Opsview Enterprise
Récemment, nous avons examiné l’ensemble d’outils Ubuntu décrit dans le discours d’ouverture d’Openstack cette année par Mark Shuttleworth – d’un intérêt particulier était Ubuntu Landscape ; leur outil de gestion des systèmes et des serveurs qui permet de patcher et de gérer des milliers de serveurs Ubuntu depuis une seule console.
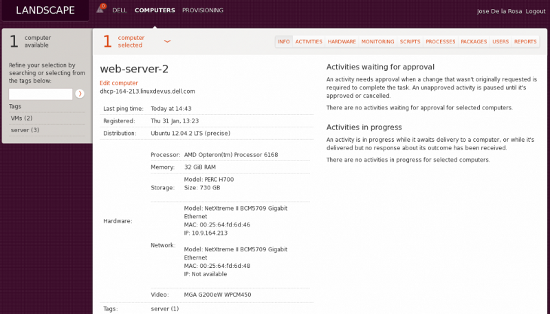
La beauté de Landscape est que si vous avez 1000 serveurs Ubuntu, vous pouvez mettre à jour le logiciel et les patcher en cours de route depuis une seule vue, vous pouvez même cliquer sur chaque serveur pour obtenir les inventaires matériels et logiciels, voir les rapports sur les processus utilisant le CPU, etc., tout cela depuis un seul outil.
Un élément intéressant du point de vue d’Opsview est qu’il contient un onglet “monitoring” par appareil. Cet onglet est rudimentaire en ce sens qu’il ne montre que les bases de la surveillance (utilisation des ressources, débit réseau, etc.) comme ci-dessous :
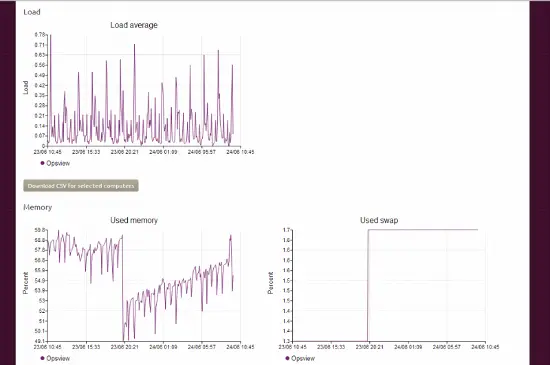
Cela est probablement récupéré / interrogé via le client Landscape fonctionnant sur le serveur Ubuntu et utilisant les sorties habituelles “load” etc qui sont analysées et modifiées. Ce détail est assez basique cependant, donc il est peu probable que beaucoup de gens l’utilisent comme leur seul outil de surveillance par rapport à Opsview – c’est plutôt un ajout utile vous permettant de vérifier la santé de ‘X’ pendant que vous êtes dans le tableau de bord de Landscape.
Cependant, cela nous a fait réfléchir – que se passerait-il si nous pouvions toujours utiliser Opsview comme notre principal outil de surveillance, qui permet aux clients de se connecter pour voir leurs systèmes via un tableau de bord, d’envoyer des rapports par e-mail, d’envoyer des alertes SMS, etc., mais d’intégrer ces données Opsview dans le tableau de bord Landscape – il serait donc possible de cliquer sur “Server100” dans Opsview, et “Server100” dans Landscape, et de voir les mêmes graphiques. Cela pourrait nous permettre de voir la santé du serveur, peu importe quel outil nous utilisons.
Pour ce faire dans Landscape, c’est en fait assez simple (une fois que vous vous êtes habitué aux nuances du système). Tout d’abord, depuis notre console principale, nous devons naviguer vers “Graphiques personnalisés” comme ci-dessous :
Ensuite, nous devons cliquer sur “Ajouter un graphique personnalisé” ce qui fait apparaître une page comme ci-dessous (nous avons gagné du temps en remplissant déjà le champ) :
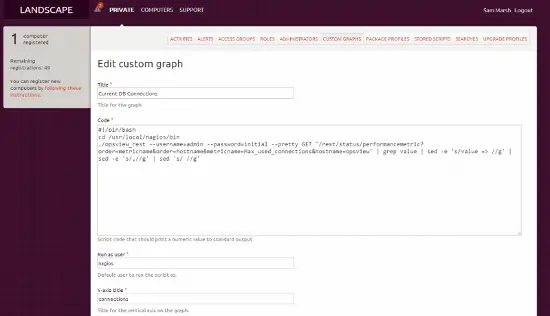
Comme il peut être difficile de lire sur l’image, le “code” est collé ci-dessous :
#!/bin/bash
cd /usr/local/nagios/bin
./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview' | grep value | sed -e 's/value => //g' | sed -e 's/,//g' | sed 's/ //g' Cela utilise essentiellement la commande opsview_rest pour se connecter au système de surveillance Opsview et obtenir la métrique “max_used_connections” de l’hôte “opsview” et effectue ensuite quelques modifications pour nous donner une valeur graphique, c’est-à-dire “28”, plutôt que “value=>28;21;s…” que Ubuntu n’aime pas :)
Ce que cela nous permet de faire, c’est d’ajouter notre système de surveillance Opsview en tant qu’hôte Landscape et de nous permettre de surveiller la santé du système de surveillance via Landscape, ainsi que la santé de tout autre hôte surveillé par le système Opsview – et tout contrôle de service en cours. Nous pouvons obtenir ces informations en exécutant la commande :
opsview_rest --username=admin --password=initial --pretty GET /rest/status/performancemetric/?hostname=opsviewOù “?hostname” est l’hôte dont nous essayons de voir les données de performance. Une fois cela configuré et enregistré comme sur la capture d’écran précédente, nous devons définir notre “exécuter en tant qu’utilisateur:” (soit root ou un autre utilisateur) et “Titre de l’axe Y” (secondes, connexions db, température, etc.). Une fois terminé, nous cliquons sur “Enregistrer” et cela sera appliqué à tous les hôtes (si vous avez coché la case).
Ensuite, après un jour ou deux, nous pouvons aller à l’hôte et voir l’onglet “monitoring” et voir nos graphiques personnalisés :
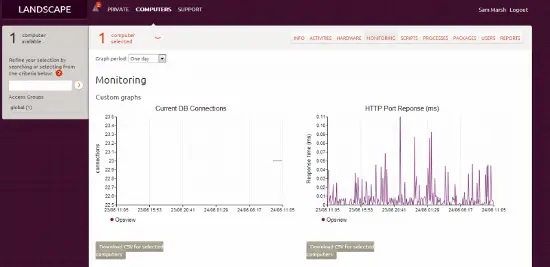
… et c’est ainsi que nous pouvons intégrer Opsview avec Ubuntu Landscape.
Le défi
Le défi suivant était que l’appareil géré par Landscape exécute la commande :
./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'..qui utilise “opsview_rest” via bash et s’exécute localement. Ce qui serait idéal, c’est de l’exécuter de n’importe où (c’est-à-dire le serveur que nous gérons dans Landscape) mais toujours contre notre système Opsview. Ce dernier est facile ; nous pouvons ajouter un préfixe comme ci-dessous :
./opsview_rest *--url-prefix=monitoringtool.company.com* --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'… mais cela dépend toujours de la commande “opsview_rest”, qui doit évidemment être disponible sur la machine locale car les graphiques personnalisés exécutent le script localement sur le système géré par Ubuntu Landscape. Et cela expose également le nom d’utilisateur et le mot de passe au serveur hôte, c’est-à-dire que votre serveur web a maintenant les détails de connexion à Opsview. Cependant, nous pouvons restreindre ce dernier problème en permettant à ce rôle un accès très spécifique en lecture seule, et juste en lecture seule à quelques éléments spécifiques.
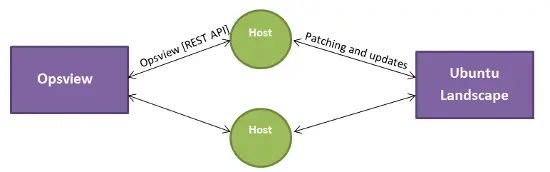
Ce dont nous avons besoin, c’est de la capacité d’avoir l’hôte qui est surveillé par Opsview et géré par Ubuntu Landscape, pour avoir la capacité d’interroger Opsview via l’API REST sur sa propre santé - afin qu’il puisse fournir ces informations à Landscape pour le graphisme. Cependant, nous ne pouvons pas distribuer opsview_rest en raison de problèmes Perl, de dépendances, etc., alors que pouvons-nous faire ?
Le seul élément qui semble fonctionner ou satisfaire nos critères est d’utiliser check_nrpe de manière “non traditionnelle”. Ce que je veux dire par là, c’est que traditionnellement NRPE est un programme côté client qui est interrogé par Opsview pour obtenir des informations – c’est-à-dire “Quelle est l’occupation de votre CPU ? Quelle est la capacité de vos disques ?”. Ces valeurs sont ensuite renvoyées à Opsview, et stockées pour des rapports, des tableaux de bord et autres et utilisées pour l’alerte.
Ce que nous avons trouvé dans cet exemple, c’est que nous pourrions installer le client NRPE (Agent Opsview) sur l’hôte surveillé/géré et l’utiliser pour interroger NRPE fonctionnant sur le maître Opsview.
Sur ce maître Opsview, nous spécifierions nos commandes NRPE dans “ /usr/local/nagios/etc/nrpe_local/overrides.cfg” (ce fichier n’existe pas, vous devez le créer) et ajouter les lignes comme ci-dessous :
############################################################################
# Fichier de configuration NRPE supplémentaire pour Opsview
############################################################################
check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl $ARG1$ $ARG2$Où “get_rest” est la commande que nous appellerons à distance, et tout ce qui est “à l’est du signe égal” est la commande réelle qui est exécutée localement.
Vous pouvez voir ci-dessus que nous exécutons quelque chose appelé “landscape_monitor.pl” – un script Perl que nous avons écrit pour prendre l’argument hôte (c’est-à-dire que $ARG1$ pourrait être “server00156” ou “networkswitch-X624” dans Opsview (le ‘nom d’hôte’)). Cela signifie qu’au lieu de devoir créer une check_command pour chacun, c’est-à-dire :
check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl server1
check_command[get_rest2]=/usr/local/nagios/bin/landscape_monitor.pl server2
check_command[get_rest3]=/usr/local/nagios/bin/landscape_monitor.pl server3 Nous pouvons simplement utiliser $ARG1$ et faire en sorte que notre script Perl l’attende. Ensuite, nous avons le script réel (celui-ci utilise JSON et IPC donc nous avons besoin des packages suivants installés sur le système Opsview : libipc-run-perl libjson-any-perl)
#!/usr/bin/perl Shell
use strict;
use warnings;
use IPC::Run qw(run);
use JSON;
my $hostname = $ARGV[0] || '';
my $perf_metric = $ARGV[1] || '';
my @cmd = qw(/usr/local/nagios/bin/opsview_rest --username admin --password initial --data-format json GET);
push @cmd, '/rest/status/performancemetric?order=metricname&order=hostname&metricname='. $perf_metric .'&hostname='. $hostname;
run \\@cmd, \\undef, \\my $out;
my $data = decode_json($out);
print $data->{list}->[0]->{value};Comme nous pouvons le voir ci-dessus, nous prenons une variable (le nom d’hôte) et l’ajoutons à la commande opsview_rest que nous construisons. Nous prenons également la métrique de performance et après avoir exécuté la commande construite, nous imprimons la sortie de la commande au format JSON – “23” dans notre exemple. Cela nous évite de devoir greper / sed à fond pour obtenir la valeur réelle que Landscape peut utiliser.
Donc, une fois que vous avez ajouté votre script “landscape_monitor.pl” à /usr/local/nagios/bin/, et que vous avez chmod / chown’d, vous pouvez aller de l’avant et créer le fichier overrides.cfg et ajouter la ligne comme ci-dessus.
Enfin, démarrez NRPE sur l’appareil surveillé/géré – et nous sommes prêts à reposer comme ci-dessous.
Scénario
Étape 1 : Nous avons l’environnement de surveillance standard ; Opsview surveille “Serveur A” et demande des informations telles que des statistiques de base de données, des statistiques apache, etc., et affiche ces informations dans des tableaux de bord pour les utilisateurs via l’interface graphique, envoie des alertes par e-mail/message texte, etc. lorsque des problèmes surviennent.
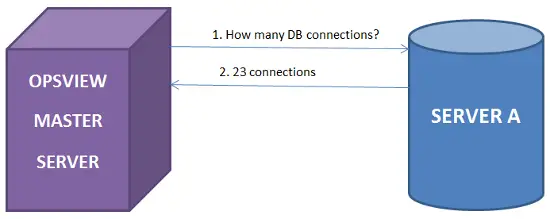
Étape 2 : Maintenant qu’Opsview collecte des milliers de métriques et de statistiques de nos serveurs, nous pouvons utiliser l’API REST pour interroger ces statistiques depuis le serveur surveillé, c’est-à-dire “Serveur A”, en utilisant le script perl ci-dessus. Pour ce faire, nous exécutons simplement les commandes comme ci-dessous :
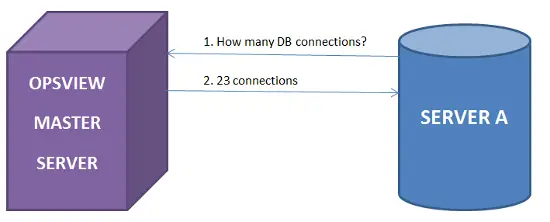
./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connectionsubuntuserver@serverA:/usr/local/nagios/libexec$ ./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connections
23
ubuntuserver@serverA:/usr/local/nagios/libexec$En utilisant check_nrpe sur ServerA et en passant notre nom d’hôte, c’est-à-dire “ServerA”, nous pouvons voir la valeur max_db_connections qu’Opsview a pour nous.
Étape 3 : Parce que nous avons maintenant la capacité pour l’appareil surveillé, de connaître ses propres métriques – les possibilités de ce que nous pouvons faire sont infinies. Dans notre exemple, nous voulons simplement utiliser Landscape pour tracer nos métriques collectées par Opsview afin que nous puissions avoir accès aux graphiques “d’un coup d’œil” dans notre système Landscape tout en étant capables de plonger dans Opsview pour voir des rapports / tableaux de bord et les éléments plus spécifiques à la surveillance. Cependant, rien ne nous empêche d’utiliser cette technologie pour intégrer Opsview avec d’autres outils de graphisme, etc.
Pour intégrer cela avec Landscape, c’est très simple. Nous devons simplement créer un autre “Graphique personnalisé” comme nous l’avons décrit plus tôt dans le document, et dans la zone de texte ajouter :
#!/bin/bash
cd /usr/local/nagios/bin
./check_nrpe –H opsviewserver –c get_rest -a servername max_used_connections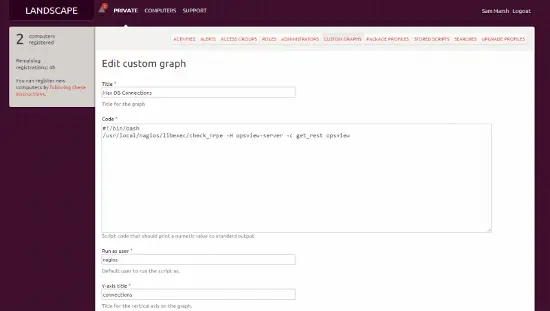
Enfin, nous appliquons ce graphique à l’hôte que nous voulons – et voilà, nous surveillons maintenant les “max DB connections” du serveur, via Landscape. Nous pouvons ensuite construire là-dessus, changer la métrique, etc., donc en essence, vous pouvez voir toutes les métriques collectées par Opsview, depuis Ubuntu Landscape, RH Satellite, etc.
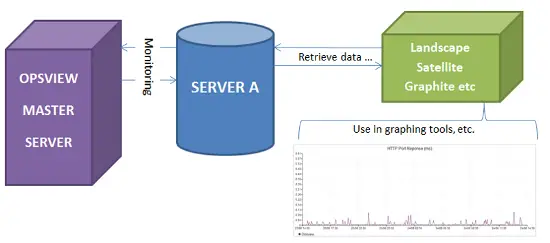
Un dernier regard
Donc en théorie, nous avons maintenant le scénario suivant :
- 100 serveurs Ubuntu étant gérés et patchés, etc. par Ubuntu Landscape.
- 100 serveurs Ubuntu étant surveillés et alertés, etc. par Opsview Enterprise.
Nous aurions les hôtes ajoutés à la fois à Landscape et Opsview, et nous utiliserions Opsview pour le niveau de surveillance plus granulaire, l’alerte, les rapports, les tableaux de bord, NetFlow, etc., puis intégrer les métriques particulièrement intéressantes “d’un coup d’œil” dans la page Landscape de ces hôtes.
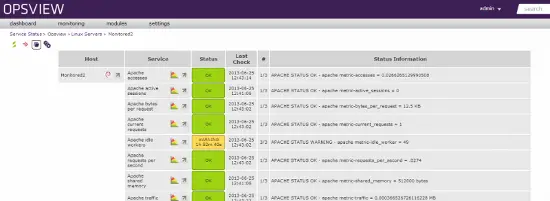
Hôte dans Opsview
L’hôte est ajouté dans Opsview comme ci-dessus – nous pouvons voir toutes les métriques, les tracer, contrôler quand ils sont surveillés, changer les métriques en fonction de la période, etc.
Hôte dans Landscape
Nous avons également l’hôte dans Landscape – de cette vue, nous pouvons voir l’actif (matériel, etc.), mettre à jour les paquets, voir des rapports sur la santé du système, etc. Nous pouvons également cliquer sur “Monitoring”, et voir nos informations collectées par Opsview “d’un coup d’œil”, depuis Landscape, comme ci-dessous :
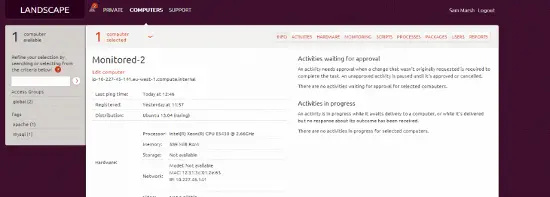
(bien que, un serveur Apache beaucoup sous-utilisé ! ^_^ ).
Essayez Opsview Enterprise ›
Essayez Ubuntu Landscape ›
Recevez de nouveaux articles dans votre boîte de réception.
Aucun spam. Désabonnez-vous à tout moment.