Linux Command · 7 min read · Sep 19, 2025
Tutoriel sur la commande Linux Uniq pour les débutants (10 exemples)
Si vous êtes un utilisateur de la ligne de commande Linux, et que votre travail implique de jouer avec des fichiers texte, vous devriez savoir (si ce n’est pas déjà fait) qu’il existe de nombreux utilitaires en ligne de commande qui peuvent vous être d’une grande aide dans différentes situations. Par exemple, il existe un outil appelé ‘uniq’ qui signale ou même supprime les lignes répétées dans un fichier.
Dans cet article, nous allons discuter de ‘uniq’ à travers des exemples faciles à comprendre. Mais avant cela, il convient de mentionner que tous les exemples et instructions mentionnés dans ce tutoriel ont été testés sur Ubuntu 16.04LTS.
Commande Linux Uniq
Comme déjà mentionné au début, la commande uniq signale ou omet les lignes répétées. Voici la syntaxe générale de cette commande :
uniq [OPTION]… [ENTRÉE [SORTIE]]
Selon la page de manuel de l’utilitaire : “Filtrer les lignes adjacentes correspondantes de l’ENTRÉE (ou de l’entrée standard), en écrivant dans la SORTIE (ou la sortie standard). Sans options, les lignes correspondantes sont fusionnées avec la première occurrence.”
Voici quelques exemples qui vous aideront à mieux comprendre l’outil.
1. Comment supprimer les lignes répétées en utilisant la commande uniq
Supposons que le fichier contienne les lignes suivantes :
Clairement, chaque ligne est répétée. Maintenant, exécutons Uniq sur ce fichier et voyons ce qui se passe.
uniq file1Comme vous pouvez le voir, la sortie produite par la commande ne contient pas de lignes répétées. Veuillez noter que le fichier original - ‘file1’ dans notre cas - reste inchangé. Vous pouvez rediriger la sortie de l’outil vers un autre fichier si vous souhaitez l’enregistrer et y travailler.
2. Comment afficher le nombre de répétitions pour chaque ligne
Si vous le souhaitez, vous pouvez également faire en sorte que uniq affiche en sortie le nombre de fois qu’une ligne est répétée. Cela peut être fait en utilisant l’option de ligne de commande -c. Par exemple, la commande suivante :
uniq -c file1produit la sortie suivante :
Comme vous pouvez le voir, le nombre de répétitions pour chaque ligne est préfixé avant elle dans la sortie.
3. Comment imprimer uniquement les lignes dupliquées en utilisant uniq
Pour faire en sorte que uniq n’imprime que les lignes dupliquées, utilisez l’option de ligne de commande -D. Par exemple, supposons que file1 contient maintenant une ligne supplémentaire en bas (notez que cette ligne n’est pas répétée).
Maintenant, lorsque j’exécute la commande suivante :
uniq -D file1La sortie suivante est produite :
Comme vous pouvez le voir, l’option -D fait en sorte que uniq affiche toutes les lignes répétées dans la sortie, y compris toutes leurs répétitions. Pour mieux séparer, vous pouvez avoir une ligne vide après chaque groupe de lignes répétées, ce qui peut être fait en utilisant l’option –all-repeated.
uniq –all-repeated[=MÉTHODE] file1
Cette option nécessite qu’un nom de méthode soit saisi par l’utilisateur. Les valeurs pourraient être prepend (pour ajouter une ligne vide) ou separate (pour ajouter une ligne vide). Par exemple, voici cette option en action avec la méthode prepend.

En continuant, si vous souhaitez que l’outil n’affiche qu’une seule ligne dupliquée par groupe, vous pouvez opter pour l’option -d. Voici un exemple de cela :
Clairement, une seule ligne répétée de chaque groupe a été affichée dans la sortie.
4. Comment faire en sorte que uniq évite de comparer les premiers champs
Parfois, selon la situation, la similarité de deux lignes est définie par une petite partie de ces lignes. Par exemple, considérez le contenu du fichier suivant :
Maintenant, supposons que les lignes soient considérées comme similaires ou différentes en fonction de leur deuxième champ (HTF ou FF), et que vous souhaitiez le faire savoir à uniq, cela peut être fait en utilisant l’option de ligne de commande -f.
uniq -f [nombre-de-champs-à-sauter] [nom-de-fichier]L’option -f nécessite que vous passiez un nombre qui représente le nombre de champs que vous souhaitez que la commande ignore. Par exemple, dans notre cas, nous pouvons passer ‘1’ comme argument à -f car c’est seulement le premier champ que nous voulons que uniq ignore.
uniq -f 1 file1La sortie montre clairement que uniq a considéré les première et troisième lignes comme répétées en fonction de leurs champs respectifs.
5. Comment faire en sorte que uniq affiche toutes les lignes, tout en séparant les groupes répétitifs par une ligne vide
Dans le cas où l’exigence est d’afficher toutes les lignes, tout en séparant les groupes répétitifs de lignes par une ligne vide, vous pouvez utiliser l’option –group. Comme l’option –all-repeated dont nous avons discuté précédemment, –group nécessite également que vous indiquiez la position de la ligne vide (prepend, append, ou both).
Voici un exemple :
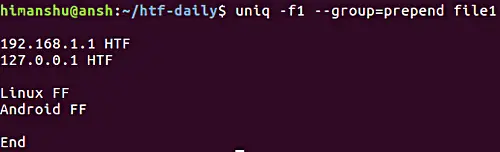
Notez que l’option -f que nous avons déjà discutée dans la section précédente.
6. Comment faire en sorte que uniq n’imprime que les lignes non répétées
Comme vous l’avez compris jusqu’à présent, par défaut, la commande uniq n’affiche que les lignes répétées dans la sortie. Mais si vous le souhaitez, vous pouvez plutôt faire en sorte qu’elle n’affiche que les lignes non répétées ou uniques. Cela peut être fait en utilisant l’option de ligne de commande -u.
uniq -u [nom-de-fichier]Donc, dans notre cas :
uniq -u file1
Voici un exemple :
Notez que l’option -f que nous avons déjà discutée dans la section/point numéro 4.
7. Comment faire en sorte que uniq évite de comparer un nombre fixe de caractères initiaux
Dans l’un de nos exemples précédents, nous avons discuté de la façon dont vous pouvez faire en sorte que uniq ignore des champs. Cependant, si vous le souhaitez, vous pouvez également forcer l’outil à ignorer un nombre fixe de caractères initiaux. Cette fonctionnalité peut être accessible en utilisant l’option de ligne de commande -s.
uniq -s [nombre-de-caractères] nom_fichier
Par exemple, supposons que le fichier contienne les lignes suivantes :
Maintenant, si vous souhaitez que uniq ignore les 4 premiers caractères de chaque ligne avant de comparer, cela peut être fait de la manière suivante :
uniq -s 4 file1
Voici la commande ci-dessus en action :
Ainsi, vous pouvez voir que la quatrième ligne (faq_forge) qui était à l’origine présente a été ignorée dans la sortie. Cela est dû au fait qu’après avoir ignoré les quatre premiers caractères, la troisième et la quatrième ligne étaient identiques, et donc considérées comme répétées par uniq.
8. Comment limiter la comparaison à un nombre fixe de caractères
De la même manière que vous ignorez des caractères, vous pouvez également demander à uniq de limiter la comparaison à un nombre fixe de caractères. Pour cela, vous devrez utiliser l’option de ligne de commande -w.
uniq -w [numéro-de-caractères] [nom-de-fichier]
Par exemple, supposons que le fichier contienne les lignes suivantes :
Maintenant, si l’exigence est de limiter la comparaison aux 3 premiers caractères, cela peut être fait de la manière suivante :
uniq -w 3 file1
Voici la commande ci-dessus en action :
Puisque les 3 premiers caractères des troisième et quatrième lignes sont identiques, ces lignes ont été considérées comme répétées. Par conséquent, seule la troisième est affichée dans la sortie.
9. Comment faire en sorte que la comparaison uniq soit insensible à la casse
Par défaut, la comparaison effectuée par uniq est de nature sensible à la casse. Cependant, vous pouvez rendre le processus insensible à la casse en utilisant l’option de ligne de commande -i.
Par exemple, considérez le même cas que nous avons discuté dans la section précédente, juste que la quatrième ligne commence par un H, O, et W majuscules.
Maintenant, si vous essayez d’exécuter la même commande que nous avons utilisée dans la section précédente, vous verrez que la sortie est différente :
C’est parce que les trois premiers caractères des troisième et quatrième lignes sont différents pour uniq en raison de leur casse. Dans des situations comme celles-ci, vous pouvez rendre la comparaison insensible à la casse en utilisant l’option de commande -i.
10. Comment faire en sorte que la sortie uniq soit terminée par NUL
Par défaut, la sortie produite par uniq est terminée par une nouvelle ligne. Cependant, si vous le souhaitez, vous pouvez avoir une sortie terminée par NUL à la place (utile lors de l’utilisation de uniq dans des scripts). Cela peut être rendu possible en utilisant l’option de ligne de commande -z.
uniq -z [nom-de-fichier]
Conclusion
Nous avons couvert presque toutes les options de ligne de commande que la commande uniq offre, alors pratiquez tout ce que nous avons discuté ici, et vous devriez avoir une idée solide de la façon dont uniq fonctionne et des fonctionnalités qu’il fournit. Comme toujours, en cas de question ou de doute, consultez d’abord la page de manuel de la commande.
Recevez de nouveaux articles dans votre boîte de réception.
Aucun spam. Désabonnez-vous à tout moment.