Hadoop Installazione · 11 min read · Dec 21, 2025
Come installare Apache Hadoop su Ubuntu 22.04

Apache Hadoop è un framework open-source per l’elaborazione e l’archiviazione di big data. Nelle industrie di oggi, Hadoop è diventato il framework standard per i big data. Hadoop è progettato per essere eseguito su sistemi distribuiti con centinaia o addirittura migliaia di computer clusterizzati o server dedicati. Tenendo presente questo, Hadoop può gestire grandi set di dati con alto volume e complessità sia per dati strutturati che non strutturati.
Ogni distribuzione di Hadoop contiene i seguenti componenti:
- Hadoop Common: Le utilità comuni che supportano gli altri moduli di Hadoop.
- Hadoop Distributed File System (HDFS): Un file system distribuito che fornisce accesso ad alta capacità ai dati delle applicazioni.
- Hadoop YARN: Un framework per la pianificazione dei lavori e la gestione delle risorse del cluster.
- Hadoop MapReduce: Un sistema basato su YARN per l’elaborazione parallela di grandi set di dati.
In questo tutorial, installeremo l’ultima versione di Apache Hadoop su un server Ubuntu 22.04. Hadoop viene installato su un server a nodo singolo e creiamo una modalità pseudo-distribuita di distribuzione di Hadoop.
Prerequisiti
Per completare questa guida, avrai bisogno dei seguenti requisiti:
- Un server Ubuntu 22.04 - Questo esempio utilizza un server Ubuntu con hostname ‘hadoop’ e indirizzo IP ‘192.168.5.100’.
- Un utente non root con privilegi di amministratore sudo/root.
Installazione di Java OpenJDK
Hadoop è un grande progetto sotto la Apache Software Foundation, è principalmente scritto in Java. Al momento della scrittura, l’ultima versione di Hadoop è v3.3.4, che è completamente compatibile con Java v11.
Il Java OpenJDK 11 è disponibile per impostazione predefinita nel repository di Ubuntu, e lo installerai tramite APT.
Per iniziare, esegui il comando apt qui sotto per aggiornare e aggiornare le liste/repository dei pacchetti sul tuo sistema Ubuntu.
sudo apt updateOra installa il Java OpenJDK 11 tramite il comando apt qui sotto. Nel repository di Ubuntu 22.04, il pacchetto ‘default-jdk’ si riferisce al Java OpenJDK v11.
sudo apt install default-jdkQuando richiesto, inserisci y per confermare e premi INVIO per procedere. E l’installazione di Java OpenJDK inizierà.
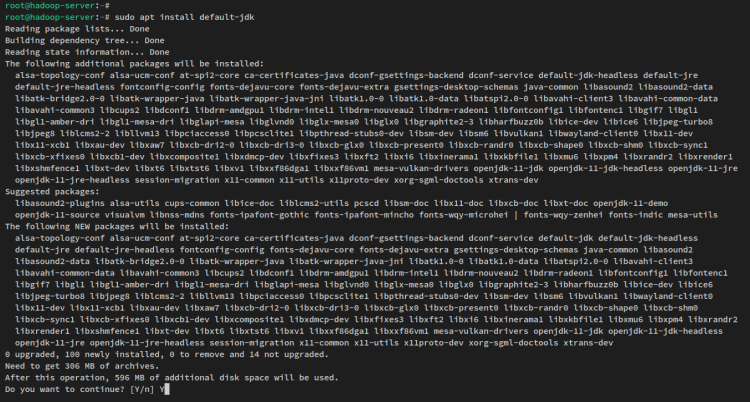
Dopo che Java è stato installato, esegui il comando qui sotto per verificare la versione di Java. Dovresti ottenere il Java OpenJDK 11 installato sul tuo sistema Ubuntu.
java -versionOra che il Java OpenJDK è installato, configurerai un nuovo utente con autenticazione SSH senza password che verrà utilizzato per eseguire i processi e i servizi di Hadoop.
Configurazione dell’utente e dell’autenticazione SSH senza password
Apache Hadoop richiede che il servizio SSH sia in esecuzione sul sistema. Questo sarà utilizzato dagli script di Hadoop per gestire il demone Hadoop remoto sul server remoto. In questo passaggio, creerai un nuovo utente che verrà utilizzato per eseguire i processi e i servizi di Hadoop e poi configurerai l’autenticazione SSH senza password.
Nel caso in cui non hai SSH installato sul tuo sistema, esegui il comando apt qui sotto per installare SSH. Il pacchetto ‘pdsh‘ è un client shell remoto multithread che ti consente di eseguire comandi su più host in modalità parallela.
sudo apt install openssh-server openssh-client pdshOra esegui il comando qui sotto per creare un nuovo utente ‘hadoop’ e impostare la password per l’utente ‘hadoop’.
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoopInserisci la nuova password per l’utente ‘hadoop‘ e ripeti la password.
Successivamente, aggiungi l’utente ‘hadoop’ al gruppo ‘sudo‘ tramite il comando usermod qui sotto. Questo consente all’utente ‘hadoop’ di eseguire il comando ‘sudo’.
sudo usermod -aG sudo hadoopOra che l’utente ‘hadoop’ è stato creato, accedi all’utente ‘hadoop‘ tramite il comando qui sotto.
su - hadoopDopo aver effettuato l’accesso, il tuo prompt diventerà simile a questo: “hadoop@hostname..“.
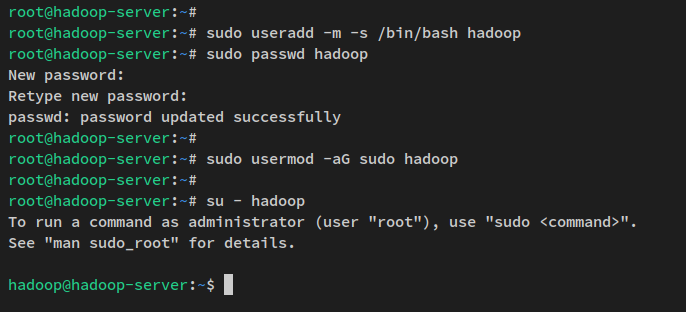
Successivamente, esegui il comando qui sotto per generare la chiave pubblica e privata SSH. Quando richiesto di impostare la password per la chiave, premi INVIO per saltare.
ssh-keygen -t rsaLa chiave SSH è ora generata nella directory ~/.ssh. L’id_rsa.pub è la chiave pubblica SSH e il file ‘id_rsa’ è la chiave privata.
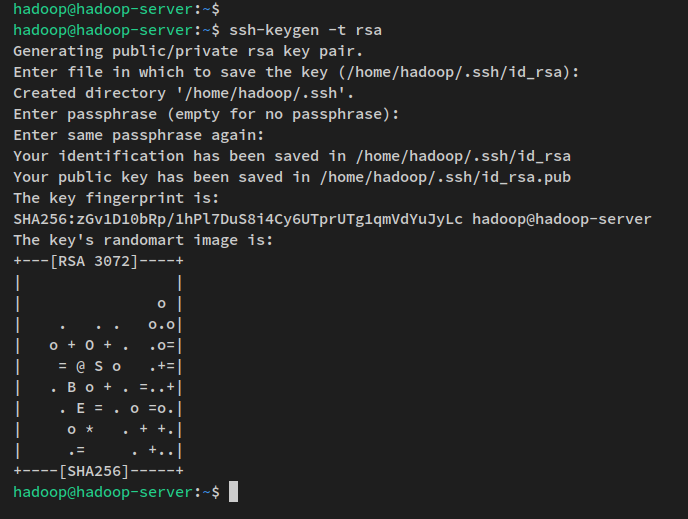
Puoi verificare la chiave SSH generata tramite il seguente comando.
ls ~/.ssh/Successivamente, esegui il comando qui sotto per copiare la chiave pubblica SSH ‘id_rsa.pub‘ nel file ‘authorized_keys‘ e cambiare i permessi predefiniti a 600.
In SSH, il file ‘authorized_keys‘ è dove hai memorizzato la chiave pubblica SSH, che può essere più chiavi pubbliche. Chiunque abbia la chiave pubblica memorizzata nel file ‘authorized_keys‘ e abbia la giusta chiave privata sarà in grado di connettersi al server come utente ‘hadoop‘ senza una password.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys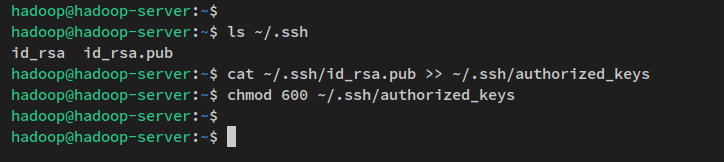
Con la configurazione SSH senza password completata, puoi verificare collegandoti alla macchina locale tramite il comando ssh qui sotto.
ssh localhostInserisci yes per confermare e aggiungere l’impronta digitale SSH e sarai connesso al server senza autenticazione tramite password.
Ora che l’utente ‘hadoop‘ è stato creato e l’autenticazione SSH senza password configurata, passerai quindi all’installazione di Hadoop scaricando il pacchetto binario di Hadoop.
Download di Hadoop
Dopo aver creato un nuovo utente e configurato l’autenticazione SSH senza password, puoi ora scaricare il pacchetto binario di Apache Hadoop e impostare la directory di installazione per esso. In questo esempio, scaricherai Hadoop v3.3.4 e la directory di installazione target sarà la directory ‘/usr/local/hadoop‘.
Esegui il comando wget qui sotto per scaricare il pacchetto binario di Apache Hadoop nella directory di lavoro corrente. Dovresti ottenere il file ‘hadoop-3.3.4.tar.gz‘ nella tua directory di lavoro corrente.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gzSuccessivamente, estrai il pacchetto Apache Hadoop ‘hadoop-3.3.4.tar.gz’ tramite il comando tar qui sotto. Quindi, sposta la directory estratta in ‘/usr/local/hadoop‘.
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoopInfine, cambia la proprietà della directory di installazione di Hadoop ‘/usr/local/hadoop’ all’utente ‘hadoop‘ e al gruppo ‘hadoop‘.
sudo chown -R hadoop:hadoop /usr/local/hadoop
In questo passaggio, hai scaricato il pacchetto binario di Apache Hadoop e configurato la directory di installazione di Hadoop. Tenendo presente ciò, ora puoi iniziare a configurare l’installazione di Hadoop.
Configurazione delle variabili d’ambiente di Hadoop
Apri il file di configurazione ‘~/.bashrc‘ tramite il comando dell’editor nano qui sotto.
nano ~/.bashrcAggiungi le seguenti righe al file. Assicurati di posizionare le seguenti righe alla fine del file.
# Variabili d'ambiente di Hadoop
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Salva il file ed esci dall’editor quando hai finito.
Successivamente, esegui il comando qui sotto per applicare le nuove modifiche all’interno del file ‘~/.bashrc‘.
source ~/.bashrcDopo che il comando è stato eseguito, le nuove variabili d’ambiente saranno applicate. Puoi verificare controllando ciascuna variabile d’ambiente tramite il comando qui sotto. E dovresti ottenere l’output di ciascuna variabile d’ambiente.
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTSSuccessivamente, configurerai anche la variabile d’ambiente JAVA_HOME nello script ‘hadoop-env.sh‘.
Apri il file ‘hadoop-env.sh’ utilizzando il seguente comando dell’editor nano. Il file ‘hadoop-env.sh’ è disponibile nella directory ‘$HADOOP_HOME‘, che si riferisce alla directory di installazione di Hadoop ‘/usr/local/hadoop‘.
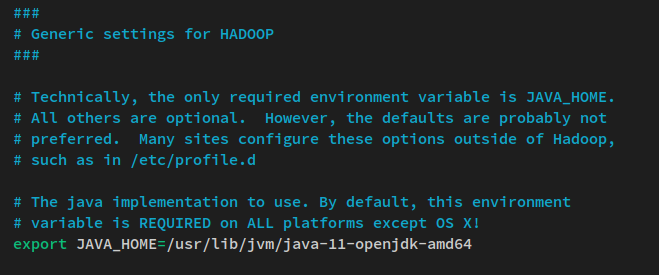
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shDecommenta la riga dell’ambiente JAVA_HOME e cambia il valore nella directory di installazione di Java OpenJDK ‘/usr/lib/jvm/java-11-openjdk-amd64‘.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64Salva il file ed esci dall’editor quando hai finito.
Con la configurazione delle variabili d’ambiente, esegui il comando qui sotto per verificare la versione di Hadoop sul tuo sistema. Dovresti vedere Apache Hadoop 3.3.4 installato sul tuo sistema.
hadoop version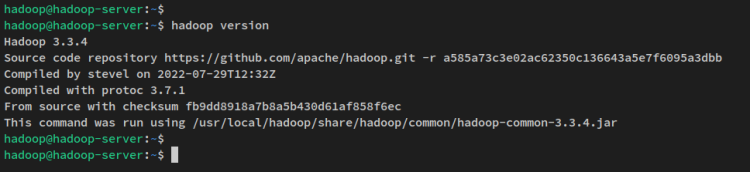
A questo punto, sei pronto per configurare e impostare il cluster Hadoop, che può essere distribuito in più modalità.
Configurazione del cluster Apache Hadoop: Modalità Pseudo-Distribuita
In Hadoop, puoi creare un cluster in tre modalità diverse:
- Modalità Locale (Standalone) - installazione predefinita di Hadoop, che viene eseguita come un singolo processo Java e in modalità non distribuita. Con questo, puoi facilmente eseguire il debug del processo Hadoop.
- Modalità Pseudo-Distribuita - Questo ti consente di eseguire un cluster Hadoop in modalità distribuita anche con un solo nodo/server. In questa modalità, i processi Hadoop verranno eseguiti in processi Java separati.
- Modalità Completamente Distribuita - grande distribuzione di Hadoop con più o addirittura migliaia di nodi/server. Se desideri eseguire Hadoop in produzione, dovresti utilizzare Hadoop in modalità completamente distribuita.
In questo esempio, configurerai un cluster Apache Hadoop con modalità Pseudo-Distribuita su un singolo server Ubuntu. Per fare ciò, apporterai modifiche ad alcune delle configurazioni di Hadoop:
- core-site.xml - Questo sarà utilizzato per definire il NameNode per il cluster Hadoop.
- hdfs-site.xml - Questa configurazione sarà utilizzata per definire il DataNode sul cluster Hadoop.
- mapred-site.xml - La configurazione MapReduce per il cluster Hadoop.
- yarn-site.xml - Configurazione ResourceManager e NodeManager per il cluster Hadoop.
Configurazione di NameNode e DataNode
Per prima cosa, configurerai il NameNode e il DataNode per il cluster Hadoop.
Apri il file ‘$HADOOP_HOME/etc/hadoop/core-site.xml‘ utilizzando il seguente editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlAggiungi le righe qui sotto al file. Assicurati di cambiare l’indirizzo IP del NameNode, oppure puoi sostituirlo con ‘0.0.0.0’ in modo che il NameNode venga eseguito su tutte le interfacce e indirizzi IP.
fs.defaultFS
hdfs://192.168.5.100:9000
Salva il file ed esci dall’editor quando hai finito.
Successivamente, esegui il comando seguente per creare nuove directory che saranno utilizzate per il DataNode sul cluster Hadoop. Quindi, cambia la proprietà delle directory DataNode all’utente ‘hadoop‘.
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsDopo di che, apri il file ‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’ utilizzando il comando dell’editor nano qui sotto.
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlAggiungi la seguente configurazione al file. In questo esempio, configurerai il cluster Hadoop in un nodo singolo, quindi devi cambiare il valore ‘dfs.replication’ a ‘1’. Inoltre, devi specificare la directory che sarà utilizzata per il DataNode.
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
Salva il file ed esci dall’editor quando hai finito.
Con il NameNode e il DataNode configurati, esegui il comando qui sotto per formattare il filesystem di Hadoop.
hdfs namenode -formatRiceverai un output simile a questo:
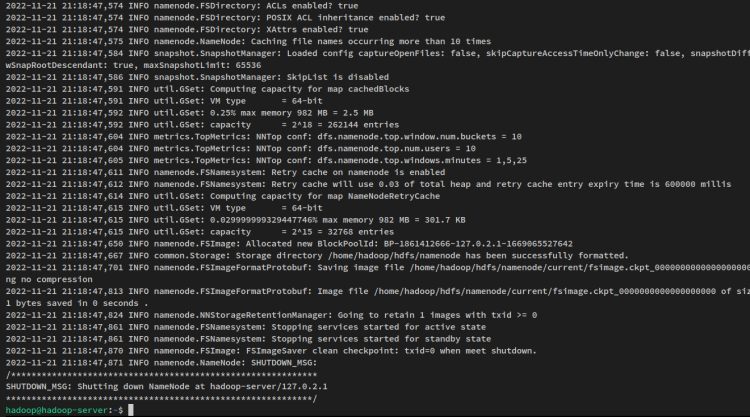
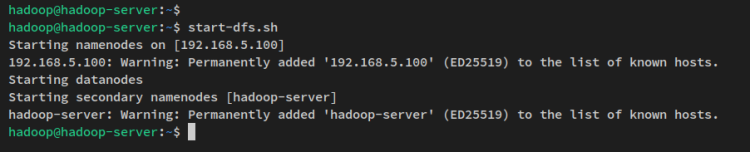
Successivamente, avvia il NameNode e il DataNode tramite il seguente comando. Il NameNode verrà eseguito sull’indirizzo IP del server che hai configurato nel file ‘core-site.xml’.
start-dfs.shVedrai un output simile a questo:
Ora che il NameNode e il DataNode sono in esecuzione, verificherai entrambi i processi tramite l’interfaccia web.
L’interfaccia web del NameNode di Hadoop è in esecuzione sulla porta ‘9870‘. Quindi, apri il tuo browser web e visita l’indirizzo IP del server seguito dalla porta 9870 (es: http://192.168.5.100:9870/).
Dovresti ora ottenere la pagina come nello screenshot seguente - Il NameNode è attualmente attivo.
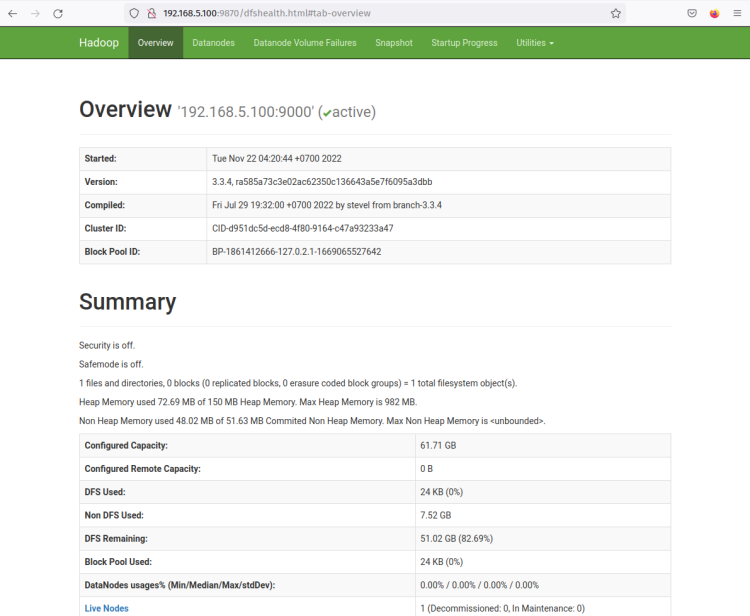
Ora fai clic sul menu ‘Datanodes’ e dovresti ottenere il DataNode attualmente attivo sul cluster Hadoop. Lo screenshot seguente conferma che il DataNode è in esecuzione sulla porta ‘9864‘ sul cluster Hadoop.
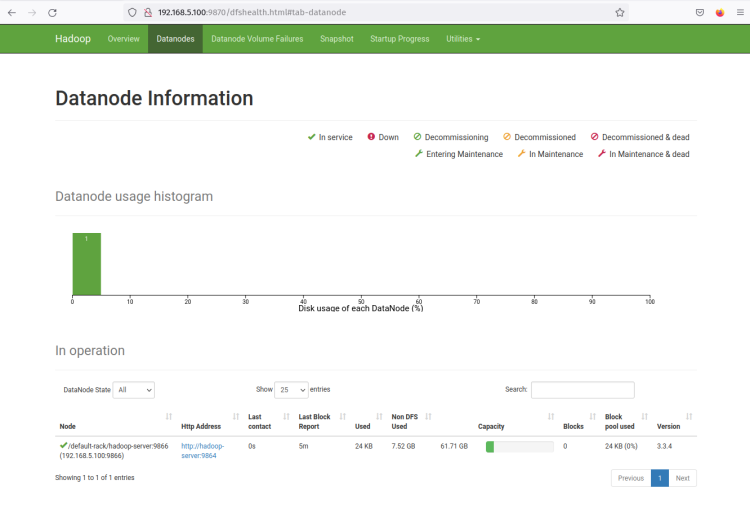
Fai clic su ‘ Http Address ‘ del DataNode e dovresti ottenere una nuova pagina con dettagli informazioni sul DataNode. Lo screenshot seguente conferma che il DataNode è in esecuzione con la directory volume ‘/home/hadoop/hdfs/datanode‘.
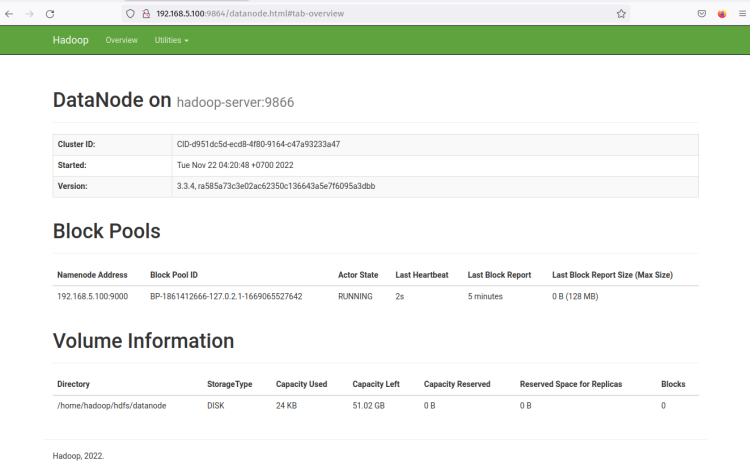
Con il NameNode e il DataNode in esecuzione, configurerai e avvierai MapReduce sul gestore Yarn (Yet Another ResourceManager e NodeManager).
Gestore Yarn
Per eseguire un MapReduce su Yarn in modalità pseudo-distribuita, devi apportare alcune modifiche ai file di configurazione.
Apri il file ‘$HADOOP_HOME/etc/hadoop/mapred-site.xml‘ utilizzando il seguente comando dell’editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlAggiungi le righe qui sotto al file. Assicurati di cambiare il mapreduce.framework.name in ‘yarn’.
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
Salva il file ed esci dall’editor quando hai finito.
Successivamente, apri la configurazione di Yarn ‘$HADOOP_HOME/etc/hadoop/yarn-site.xml‘ utilizzando il seguente comando dell’editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlCambia la configurazione predefinita con le seguenti impostazioni.
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
Salva il file ed esci dall’editor quando hai finito.
Ora esegui il comando qui sotto per avviare i demoni Yarn. E dovresti vedere sia ResourceManager che NodeManager che si avviano.
start-yarn.shIl ResourceManager dovrebbe essere in esecuzione sulla porta predefinita 8088. Torna al tuo browser web e visita l’indirizzo IP del server seguito dalla porta ResourceManager ‘8088’ (es: http://192.168.5.100:8088/).
Dovresti vedere l’interfaccia web del ResourceManager di Hadoop. Da qui, puoi monitorare tutti i processi in esecuzione all’interno del cluster Hadoop.
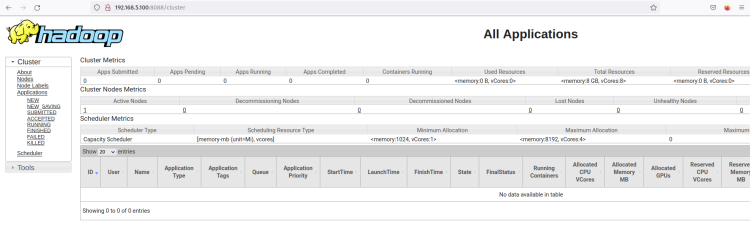
Fai clic sul menu Nodes e dovresti ottenere il nodo attualmente in esecuzione sul cluster Hadoop.
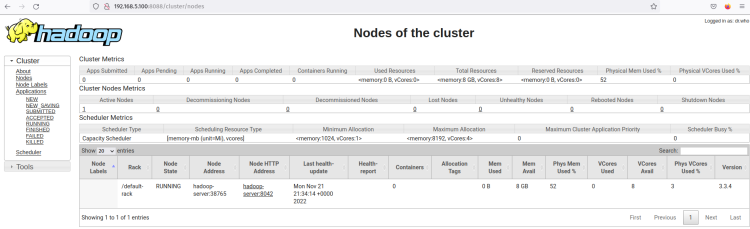
Ora il cluster Hadoop è in esecuzione in modalità pseudo-distribuita. Questo significa che ogni processo Hadoop è in esecuzione come un singolo processo su un singolo server Ubuntu 22.04, che include il NameNode, il DataNode, MapReduce e Yarn.
Conclusione
In questa guida, hai installato Apache Hadoop su un server Ubuntu 22.04 a macchina singola. Hai installato Hadoop con la modalità Pseudo-Distribuita abilitata, il che significa che ogni componente di Hadoop è in esecuzione come un singolo processo Java sul sistema. In questa guida, hai anche imparato come configurare Java, impostare le variabili d’ambiente di sistema e configurare l’autenticazione SSH senza password tramite chiave pubblica-privata SSH.
Questo tipo di distribuzione di Hadoop, modalità Pseudo-Distribuita, è raccomandato solo per test. Se desideri un sistema distribuito che possa gestire set di dati medi o grandi, puoi distribuire Hadoop in modalità Clusterizzata, che richiede più sistemi di calcolo e fornisce alta disponibilità per la tua applicazione.
Ricevi i nuovi post nella tua casella di posta.
Nessuno spam. Disiscriviti in qualsiasi momento.