Stable Diffusion · 12 min read · Sep 12, 2025
Come addestrare l'IA di Stable Diffusion con il tuo volto per creare arte utilizzando DreamBooth
Post ospite di Tarunabh Dutta.
Se il 2021 è stato l’anno dei modelli linguistici basati su parole, il 2022 ha fatto un salto nei modelli di IA da testo a immagine. Oggi ci sono molti modelli di IA da testo a immagine disponibili che possono produrre immagini di alta qualità. Stable Diffusion è una delle opzioni più popolari e conosciute. È un modello veloce e stabile che produce risultati coerenti.

Il processo di generazione delle immagini è ancora in parte misterioso, ma è chiaro che Stable Diffusion produce risultati eccellenti. Può essere utilizzato per generare immagini da testo o per alterare immagini esistenti. Le opzioni e i parametri disponibili consentono molta personalizzazione e controllo sull’immagine finale.
Sebbene sia relativamente più facile lavorare su immagini di celebrità e figure popolari, semplicemente perché ci sono già immagini disponibili, non è così facile far funzionare l’IA sul tuo volto. La logica dice di fornire al modello di IA le tue immagini e poi lasciarlo fare la sua magia, ma come si può fare esattamente?
In questo articolo, cercheremo di dimostrare come addestrare un modello di Stable Diffusion utilizzando l’inversione testuale di DreamBooth su un’immagine di riferimento per costruire rappresentazioni AI del tuo volto o di qualsiasi altro oggetto e generare foto di risultati incredibili, precisione e coerenza. Se sembra troppo tecnico, resta con noi e cercheremo di renderlo il più amichevole possibile per i principianti.
Cos’è Stable Diffusion?
Iniziamo con le basi. Il modello Stable Diffusion è un modello di machine learning all’avanguardia da testo a immagine addestrato su un ampio set di immagini. È costoso da addestrare, con un costo di circa $660.000. Tuttavia, il modello Stable Diffusion può essere utilizzato per generare arte utilizzando il linguaggio naturale.
I modelli di IA da testo a immagine basati su deep learning stanno diventando sempre più popolari grazie alla loro capacità di tradurre il testo in immagini in modo accurato. Questo modello è gratuito da utilizzare e può essere trovato su Hugging Face Spaces e DreamStudio. I pesi del modello possono anche essere scaricati e utilizzati localmente.
Stable Diffusion utilizza un processo chiamato “diffusione” per generare immagini che assomigliano al prompt testuale.
In breve, l’algoritmo di Stable Diffusion prende una descrizione testuale e genera un’immagine basata su quella descrizione. L’immagine generata assomiglierà al testo ma non sarà una replica esatta. Le alternative a Stable Diffusion includono i modelli Dall-E di OpenAI e Imagen di Google.
Lettura correlata: 9 migliori app generatore di arte AI per iPhone e Android
Guida per addestrare l’IA di Stable Diffusion con il tuo volto per creare immagini utilizzando DreamBooth
Oggi, dimostrerò come addestrare un modello di Stable Diffusion utilizzando il mio volto come riferimento iniziale per generare immagini con uno stile altamente coerente e preciso che è sia originale che fresco.
Quindi, per questo scopo, utilizzeremo un Google Colab chiamato DreamBooth per addestrare Stable Diffusion.
Prima di avviare questo Google Colab, dobbiamo preparare alcuni asset di contenuto.
Fase 1: Google Drive con spazio libero sufficiente
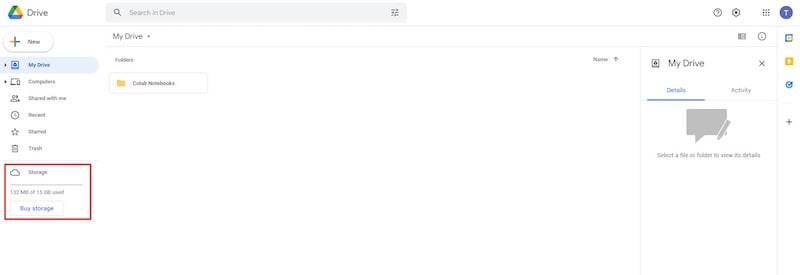
Per questo, hai bisogno di un account Google Drive con almeno 9 GB di spazio libero.
Un account Google Drive gratuito offre 15 GB di spazio di archiviazione gratuito, che è sufficiente per questo compito. Quindi puoi creare un nuovo account Gmail (usa e getta) solo per questo scopo.
Fase 2: Immagini di riferimento per addestrare l’IA
In secondo luogo, devi avere almeno una dozzina di ritratti del tuo volto o di qualsiasi oggetto target pronti per essere utilizzati come riferimenti.
- Assicurati che le caratteristiche facciali siano visibili e adeguatamente illuminate nelle immagini catturate. Evita di utilizzare ombre dure, in particolare sul volto.
- Inoltre, il soggetto dovrebbe affrontare la fotocamera o avere un profilo laterale in cui entrambi gli occhi e tutte le caratteristiche facciali siano chiaramente visibili.
- La fotocamera dovrebbe essere in grado di catturare caratteristiche facciali di alta qualità. L’opzione migliore è una fotocamera DSLR o mirrorless di livello professionale. Anche una fotocamera per smartphone di ottima qualità può andare bene.
- La composizione dovrebbe essere posizionata al centro dell’inquadratura con un po’ di spazio sopra la testa.
- Come immagini di input, un minimo di dodici foto ravvicinate del volto, cinque foto a mezzo busto che coprono dalla testa fino sopra la vita e circa tre foto a figura intera dovrebbero essere adeguate.
- Un minimo di venti fotografie di riferimento dovrebbe essere sufficiente per questo scopo.
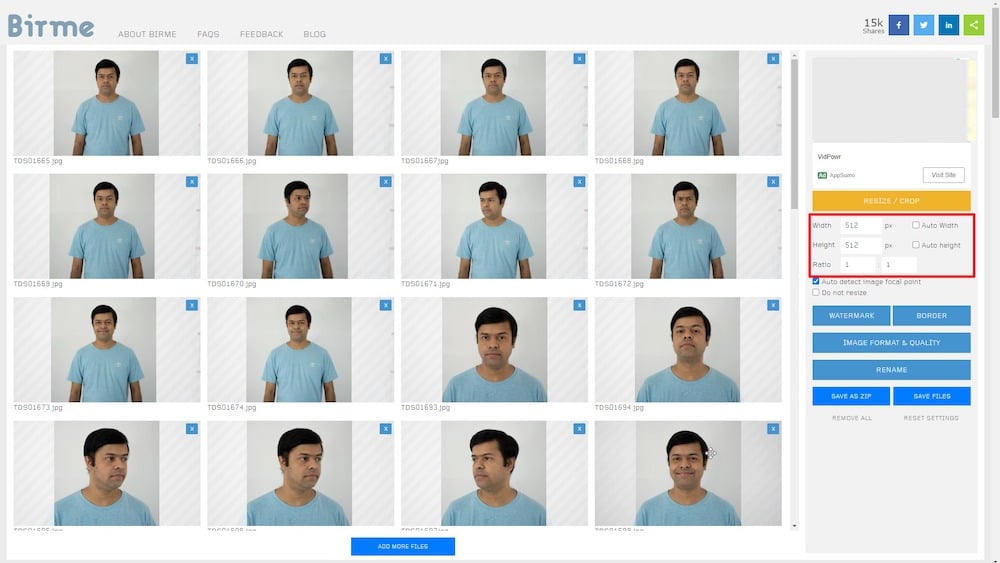
Nel mio caso, ho scattato e raccolto una collezione di circa 50 autoritratti, che ho ritagliato a 512 x 512 pixel utilizzando lo strumento online – Birme. Puoi anche utilizzare qualsiasi editor di immagini alternativo per questo scopo.
Si prega di tenere presente che l’immagine finale deve essere ottimizzata per il web e ridotta in dimensione del file con una perdita minima di qualità.
Fase 3: Google Colab
Il runtime di Google Colab può ora essere eseguito.
Ci sono sia versioni gratuite che a pagamento della piattaforma Google Colab. Dreambooth può funzionare sulla versione gratuita, ma le prestazioni sono significativamente più veloci e più coerenti sulla versione Colab Pro (a pagamento), che dà priorità all’uso di una GPU ad alta velocità e assegna almeno 15 GB di VRAM al compito in questione.
Se non ti dispiace spendere qualche dollaro, un abbonamento Colab Pro da $10 che include 100 unità di calcolo ogni mese è più che adeguato per questa sessione.
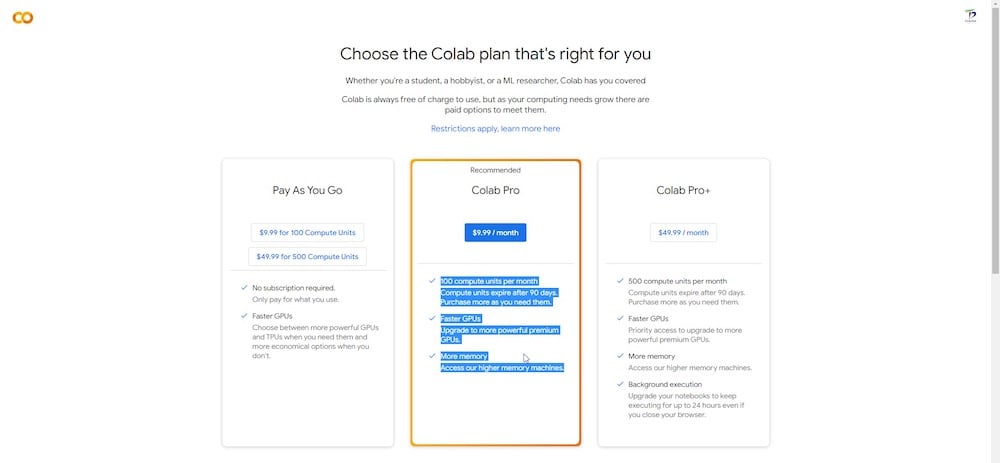
Avrai anche accesso a memoria RAM extra e GPU che sono relativamente più potenti e veloci.
Lasciami ribadire questo: NON è necessario essere uno specialista tecnico per eseguire questo Colab. Non è necessaria alcuna esperienza di codifica precedente.
Una volta registrato su Google Colab (versione gratuita o a pagamento), accedi con le tue credenziali e vai a questo link per aprire DreamBooth Stable Diffusion.
Un Google Colab ha sezioni o celle di “runtime” con pulsanti di riproduzione cliccabili sul lato sinistro, disposti in sequenza. Per avviare il runtime dall’alto, basta cliccare sui pulsanti di riproduzione uno per uno. Ogni segmento consiste in un runtime che deve essere eseguito. Quando clicchi su un pulsante di riproduzione, la sezione corrispondente viene eseguita come runtime. Dopo un po’, apparirà un segno di spunta verde a sinistra del pulsante di riproduzione per indicare che il runtime è stato eseguito con successo.
Assicurati di eseguire manualmente solo un runtime alla volta e di passare alla successiva sezione “runtime” solo quando il runtime corrente è terminato.
Nella parte superiore della barra del menu del runtime, hai l’opzione di eseguire tutti i runtime contemporaneamente. Tuttavia, questo non è raccomandato.

Sotto c’è un’opzione etichettata “Cambia tipo di runtime”. Se sei abbonato a un abbonamento pro, puoi scegliere e salvare una GPU “premium” e alta RAM per la tua esecuzione.
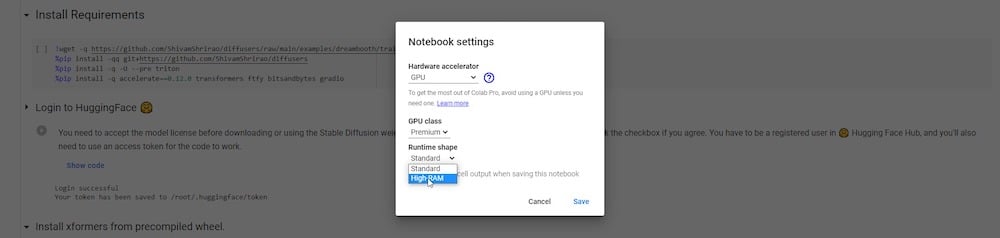
Ora sei pronto per avviare il Colab di DreamBooth.

10 Passi per completare con successo un modello AI addestrato su DreamBooth
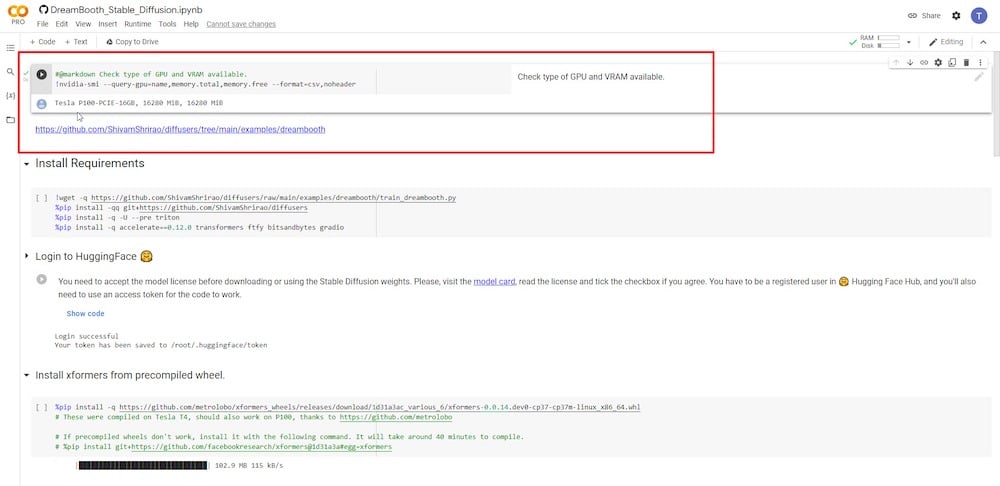
PASSO 1: Decidi su GPU e VRAM
Il primo passo è determinare il tipo di GPU e VRAM disponibili. Gli utenti pro avranno accesso a GPU veloci e VRAM migliorata che è più stabile.
Una volta cliccato sul pulsante di riproduzione, verrà visualizzato un avviso perché si sta accedendo al sito web di origine dello sviluppatore, GitHub. Devi solo cliccare su “ Esegui comunque ” per continuare.
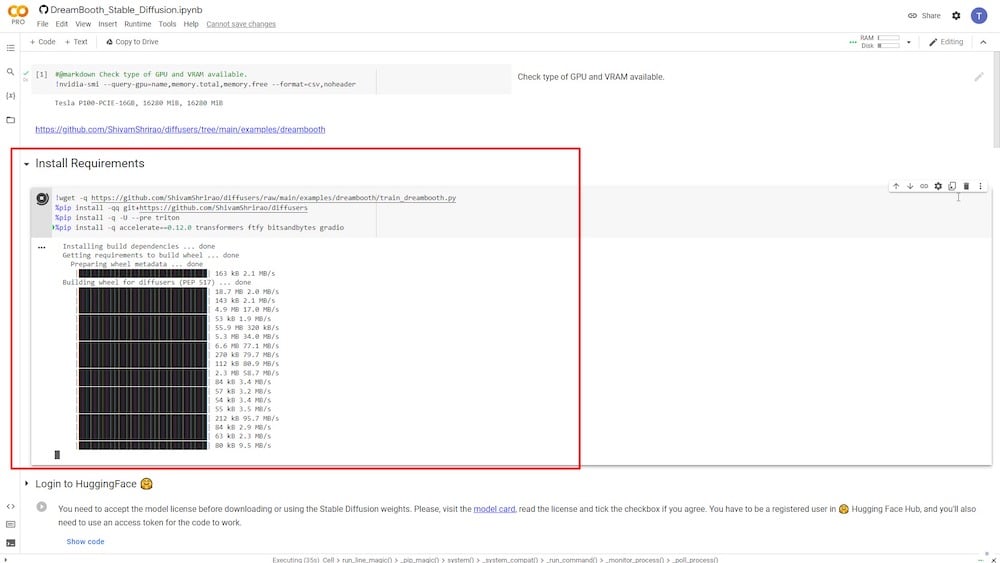
PASSO 2: Esegui DreamBooth
Nel passo successivo, devi installare alcuni requisiti e dipendenze. Devi solo cliccare sul pulsante di riproduzione e lasciarlo eseguire.
PASSO 3: Accedi a Hugging Face
Dopo aver cliccato sul pulsante di riproduzione, il passo successivo richiederà di accedere al tuo account Hugging Face. Puoi creare un account gratuito se non ne hai già uno. Una volta effettuato l’accesso, vai alla tua pagina delle impostazioni dall’angolo in alto a destra.
Quindi, clicca sulla sezione ‘ Token di accesso ‘ e sul pulsante ‘ Crea nuovo ‘ per generare un nuovo “token di accesso” e rinominarlo come desideri.
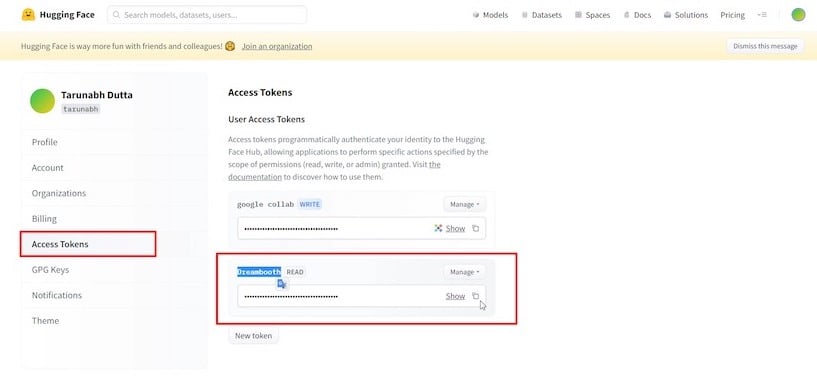
Copia il token di accesso, poi torna alla scheda Colab e inseriscilo nel campo fornito, quindi clicca su “ Accedi.”
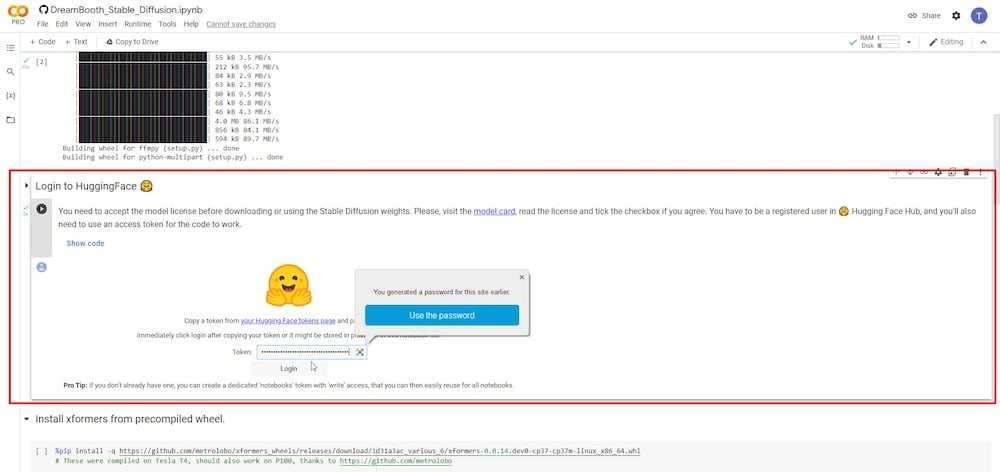
PASSO 4: Installa xformers
In questo passo, puoi cliccare sul runtime per installare xformers semplicemente premendo il pulsante di riproduzione.
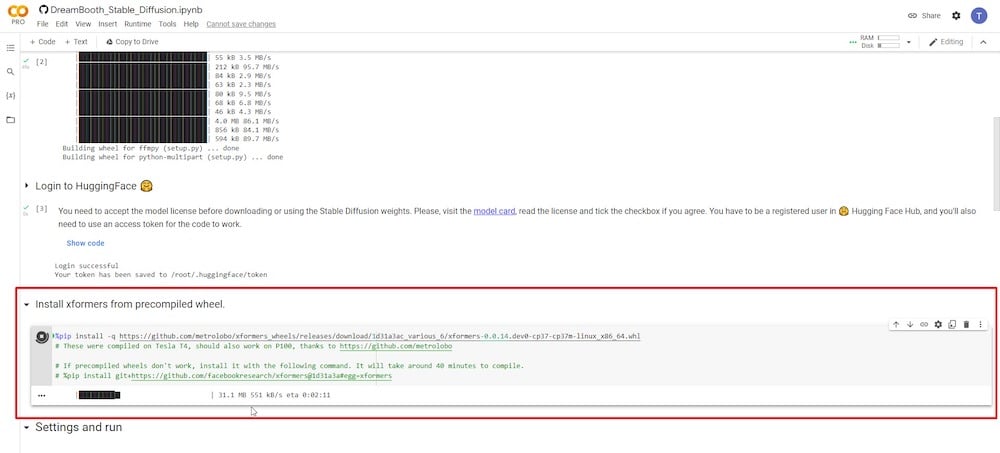
PASSO 5: Collega Google Drive
Dopo aver cliccato sul pulsante di riproduzione, ti verrà chiesto in una nuova finestra pop-up di concedere il permesso di accedere al tuo account Google Drive. Clicca su “Consenti” quando ti viene chiesto il permesso.
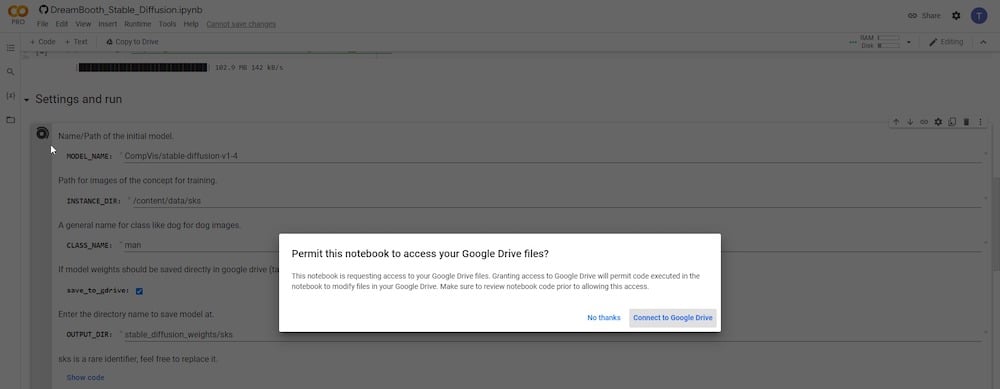
Dopo aver concesso i permessi, devi confermare che “ salva su Google Drive ” sia selezionato. Devi anche impostare un nuovo nome per la variabile ‘ NOME CLASSE ‘. Se desideri inviare immagini di riferimento di una persona, inserisci semplicemente ‘persona’, ‘uomo’ o ‘donna’. Se le tue immagini di riferimento sono di un cane, digita ‘cane’ e così via. Puoi mantenere i restanti campi invariati. In alternativa, puoi rinominare la directory di input—’INSTANCE DIR’ o la directory di output—’OUTPUT DIR.’
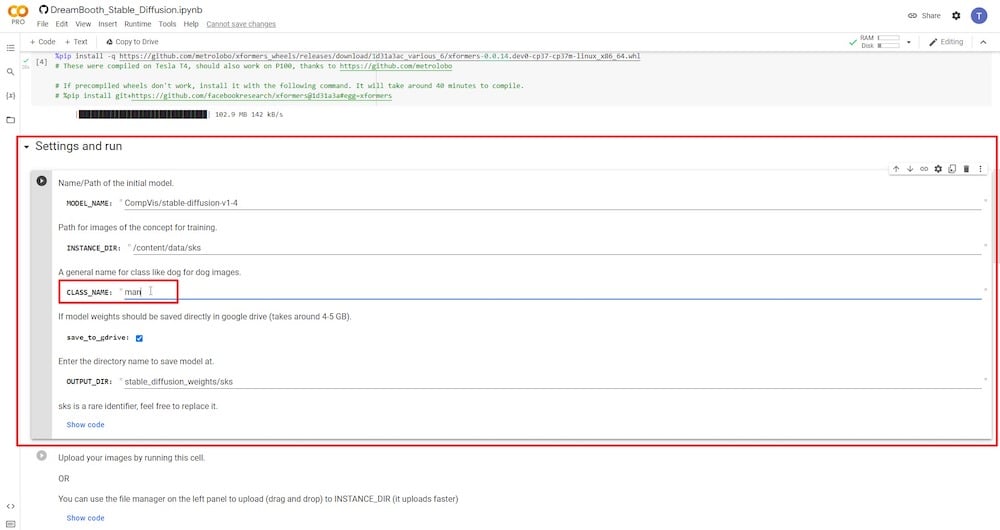
PASSO 6: Carica foto di riferimento
Dopo aver cliccato sul pulsante di riproduzione nel passo precedente, vedrai l’opzione per caricare e aggiungere tutte le tue foto di riferimento.
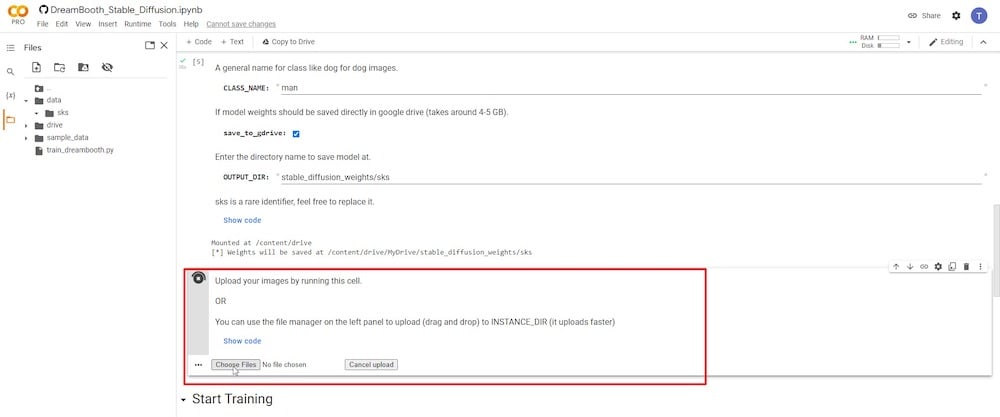
Ti consiglio un minimo di 6 e un massimo di 20 fotografie. Fai riferimento a “FASE 2” sopra per una spiegazione concisa su come selezionare la migliore immagine di riferimento in base a come è stato catturato il soggetto.
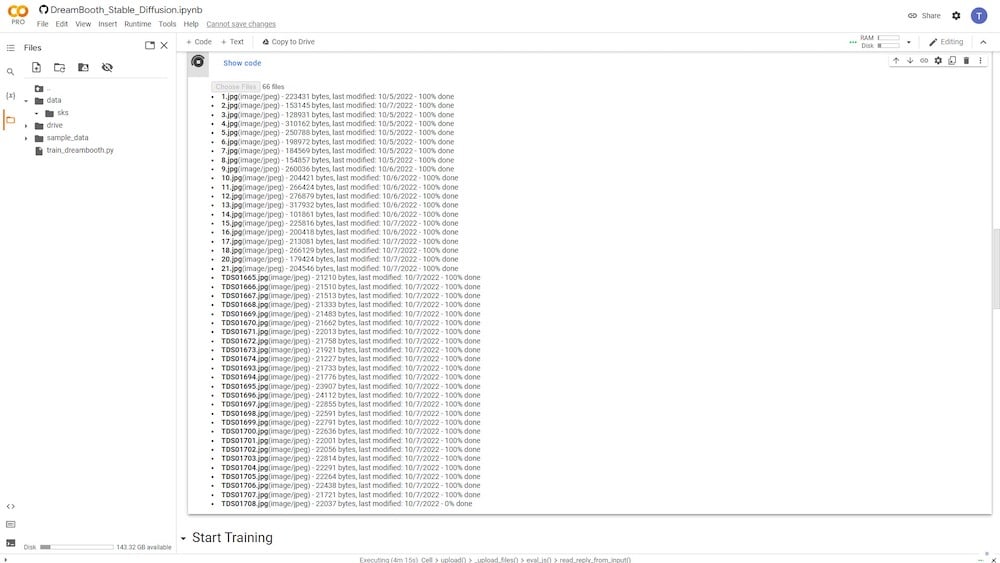
Una volta caricate tutte le tue immagini, puoi visualizzarle nella colonna di sinistra. C’è un’icona a cartella. Una volta cliccato su di essa, potrai visualizzare le cartelle e le sottocartelle in cui i tuoi dati sono attualmente memorizzati.
Sotto la directory dei dati, puoi visualizzare la tua directory di input, dove sono memorizzate tutte le tue foto caricate. Nel mio caso, è conosciuta come “sks” (nome predefinito).
Inoltre, si prega di notare che questo contenuto è memorizzato solo temporaneamente nel tuo spazio di archiviazione Google Colab e non su Google Drive.
PASSO 7: Addestra il modello AI con DreamBooth
Questo è il passo più cruciale, poiché stai addestrando un nuovo modello di IA basato su tutte le tue foto di riferimento caricate utilizzando DreamBooth.
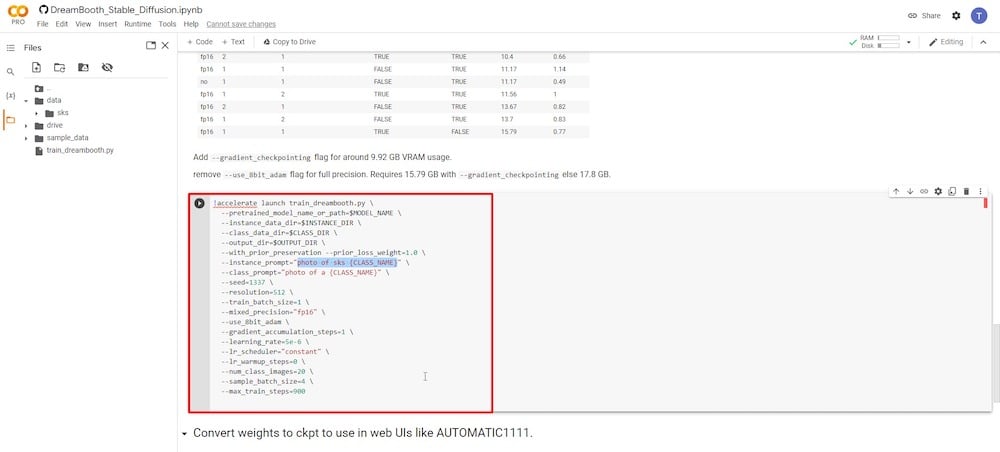
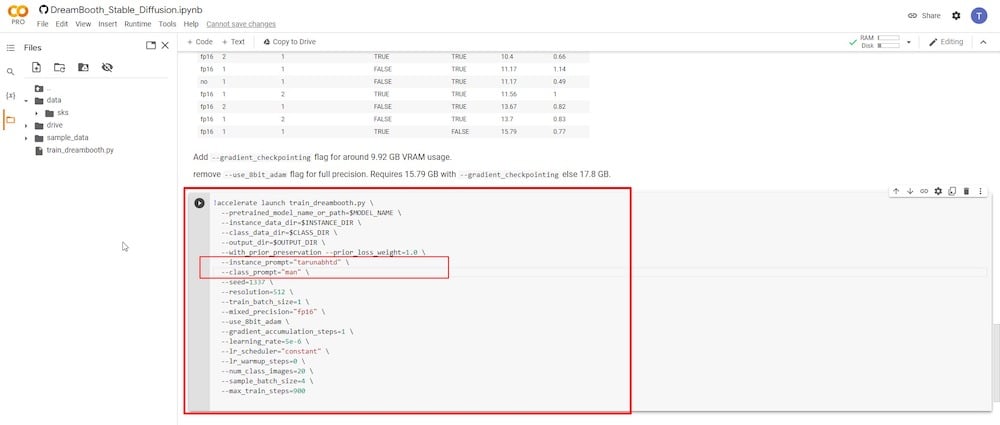
Devi concentrarti solo su due campi di input. Il primo parametro è “—instance prompt.” Qui, devi inserire un nome molto unico. Nel mio caso, userò il mio nome seguito dalle mie iniziali. L’idea è mantenere il nome completo unico e preciso.
Il secondo campo di input cruciale è il parametro ‘—class prompt’. Devi rinominarlo per corrispondere a quello che hai usato in ‘PASSO 4’. Nel mio caso, ho usato il termine “uomo.” Quindi lo riscriverò in questo campo e sovrascriverò qualsiasi voce precedente.
Il resto dei campi può essere lasciato intatto. Ho osservato utenti che sperimentano modificando campi come ‘—num class images’ a 12 e ‘—max train steps’ a 1000, 2000 o anche di più. Tuttavia, si prega di ricordare che modificare questi campi potrebbe far esaurire la memoria del Colab e farlo arrestare, richiedendo di ricominciare da capo. Pertanto, è consigliabile non modificarli al primo tentativo. Potresti sperimentarli in futuro dopo aver acquisito sufficiente esperienza.
Una volta eseguito questo runtime cliccando sul pulsante di riproduzione, il Colab inizierà a scaricare i file eseguibili necessari e sarà quindi in grado di addestrare utilizzando le tue foto di riferimento.
L’addestramento del modello richiederà da 15 minuti a oltre un’ora. Devi avere pazienza e tenere traccia dei progressi fino al completamento del runtime. Se il tuo Google Colab è inattivo per troppo tempo, potrebbe resettarsi. Quindi continua a controllare i progressi e a cliccare sulla scheda occasionalmente.
PASSO 8: Converti il modello AI in formato ckpt
Dopo il completamento dell’addestramento, avrai l’opzione di convertire il modello addestrato in un file nel formato ckpt, che è direttamente compatibile con Stable Diffusion.
La conversione può essere eseguita in due fasi di runtime. La prima è “ Scarica script,” e la seconda è “ Esegui conversione,” dove hai l’opzione di ridurre la dimensione del download del modello addestrato. Tuttavia, farlo degraderà significativamente la qualità dell’immagine risultante.
Pertanto, per mantenere la dimensione originale, l’opzione ‘ fp16 ‘ deve rimanere deselezionata.
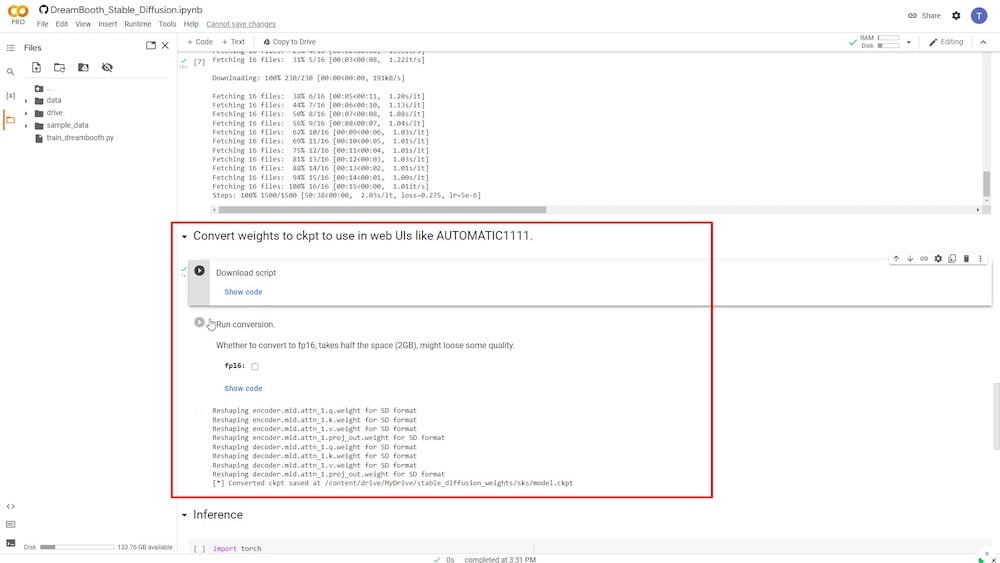
Alla fine di questo particolare runtime, un file chiamato “ model.ckpt ” sarà salvato nel tuo Google Drive connesso.
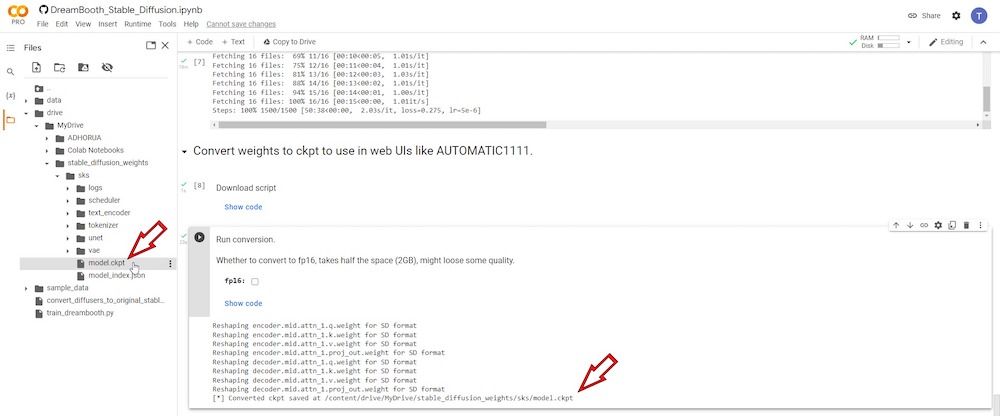
Possiamo salvare questo file per un uso futuro perché i tuoi runtime vengono immediatamente eliminati quando chiudi la scheda del browser di DreamBooth Colab. Quando riapri la versione Colab di DreamBooth in seguito, dovrai ricominciare da capo.
Supponiamo che tu salvi il file del modello addestrato nel tuo Google Drive. In tal caso, puoi recuperarlo in seguito per utilizzarlo con la tua GUI di Stable Diffusion installata localmente, DreamBooth, o qualsiasi notebook Colab di Stable Diffusion che richieda di caricare il file “model.ckpt” affinché il runtime funzioni correttamente. Puoi anche salvarlo sui tuoi dischi rigidi locali per un uso successivo.
PASSO 9: Preparati per il prompt testuale
I successivi due processi di runtime sotto la categoria “Inferenza” preparano il nuovo modello addestrato per il prompt testuale utilizzato per la generazione delle immagini. Basta premere il pulsante di riproduzione per ogni runtime, e si completerà in pochi minuti.
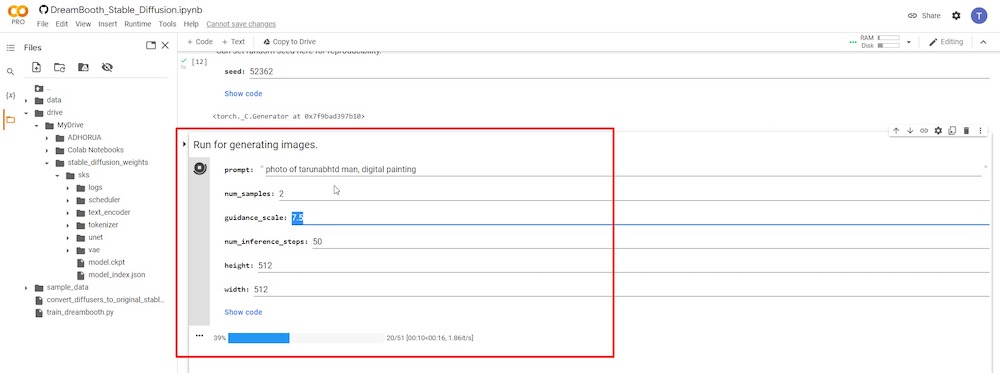
PASSO 10: Genera immagini AI
Questo è l’ultimo passo, dove puoi digitare i prompt testuali e le immagini AI verranno generate.
Devi utilizzare esattamente il nome di ‘instance_prompt’ e ‘–class_prompt’ insieme dal PASSO 6 all’inizio del prompt testuale. Ad esempio, nel mio caso, ho usato “un ritratto di tarunabhtd uomo, pittura digitale” per generare nuove immagini AI che assomigliano a me stesso.
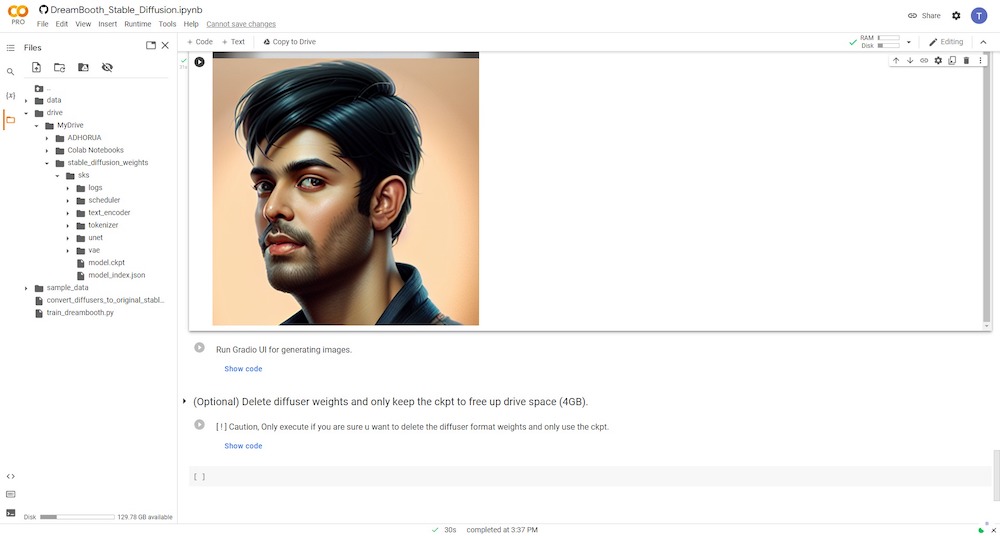
Di seguito puoi vedere alcuni risultati di immagini generate con il modello addestrato di DreamBooth.

Gioca con i prompt per ottenere i migliori output
Se segui attentamente i passaggi sopra descritti, sarai in grado di generare immagini AI che assomigliano strettamente alle caratteristiche facciali nelle tue immagini di riferimento. Questo metodo richiede solo la piattaforma online Google Colab per eseguire una versione aggiornata della tecnologia AI per l’inversione testuale.
Per idee migliori sui prompt testuali, puoi controllare siti come –
- OpenArt AI
- Krea AI
- Lexica art
Devi anche imparare l’arte di creare prompt testuali migliori e più efficaci utilizzando una varietà di stili artistici e diverse combinazioni. Un buon punto di partenza sarebbe il SubReddit di Stable Diffusion.
Reddit ha una grande comunità dedicata a Stable Diffusion. Ci sono anche diversi gruppi Facebook e comunità Discord che discutono attivamente, condividono ed esplorano nuove strade di Stable Diffusion.
Di seguito condivido anche link a alcuni video tutorial di DreamBooth che puoi guardare su Youtube –
Spero che tu trovi utile questa guida. Se hai domande, sentiti libero di commentare qui sotto e cercheremo di aiutarti.
Autore: Tarunabh Dutta è un regista premiato che ha completato più di 45 progetti negli ultimi 16 anni, tra cui lungometraggi, cortometraggi, video musicali, documentari e pubblicità commerciali, sotto il suo marchio indipendente ‘
TD Film Studio
‘.
Ricevi i nuovi post nella tua casella di posta.
Nessuno spam. Disiscriviti in qualsiasi momento.