Linux Command · 4 min read · Sep 17, 2025
Tutorial sul comando Join di Linux per principianti (5 esempi)
A volte, potresti voler combinare due file in un modo che l’output abbia ancora più senso. Ad esempio, potrebbe esserci un file contenente i nomi dei continenti e un altro file contenente i nomi dei paesi situati in questi continenti, e la richiesta è di combinare entrambi i file in modo che un continente e il paese corrispondente appaiano sulla stessa riga.
Questo è solo un esempio: potrebbero esserci centinaia di casi d’uso simili. Se sei su Linux e stai cercando uno strumento che possa aiutarti in situazioni come queste, potresti voler dare un’occhiata a join, che è un’utilità da riga di comando. In questo tutorial, discuteremo di questo comando utilizzando alcuni esempi facili da comprendere.
Si prega di notare che tutti gli esempi menzionati in questo articolo sono stati testati su Ubuntu 16.04, e la versione del comando join che abbiamo utilizzato è 8.25.
Comando join di Linux
Il comando join ti consente di combinare le righe di due file su un campo comune.
join [OPZIONE]... FILE1 FILE2Ecco cosa dice la pagina man su questo strumento:
Per ogni coppia di righe di input con campi di join identici, scrivi una riga su output standard. Il campo di join predefinito è il primo, delimitato da spazi. Quando FILE1 o FILE2 (non entrambi) è -, leggi l'input standard.I seguenti esempi dovrebbero darti una buona idea di come funziona il comando join.
1. Come combinare le righe dei file utilizzando il comando join?
Comprendiamo l’uso di base del comando join. Supponiamo che ci siano due file (file1 e file2) che contengono le seguenti righe:
1. Asia:
2. Africa:
3. Europa:
4. Nord America:e
1. India
2. Nigeria
3. Paesi Bassi
4. Stati UnitiOra, puoi combinare questi due file nel seguente modo:
join file1 file2Ecco l’output del comando sopra nel nostro caso:
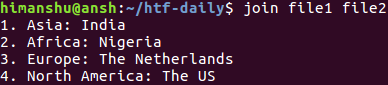
2. Come fare in modo che join stampi righe non accoppiabili?
Per impostazione predefinita, il comando join stampa solo righe accoppiabili. Ad esempio, anche se file1 contiene un campo extra (numero di riga 5):
1. Asia:
2. Africa:
3. Europa:
4. Nord America:
5. Sud America:unendo file1 e file2 non produrrà alcun output diverso:
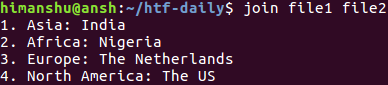
Questo perché le righe non accoppiabili vengono escluse dall’output. Tuttavia, se lo desideri, puoi comunque averle nell’output utilizzando l’opzione da riga di comando -a. Questa opzione richiede di passare un numero di file in modo che lo strumento sappia a quale file ti riferisci.
Ad esempio, nel nostro caso, il comando sarebbe:
join file1 file2 -a 1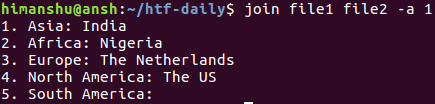
Quindi puoi vedere che la riga non accoppiata dal numero di file 1 (file1 nel nostro caso) è stata visualizzata anche nell’output.
Nota che nel caso in cui tu voglia solo stampare righe non accoppiate (significa, sopprimere le righe accoppiate nell’output), puoi farlo utilizzando l’opzione da riga di comando -v. Questa opzione funziona esattamente come funziona -a.
Ecco un esempio dell’opzione -v:

3. Come fornire campi di join personalizzati?
Come già sappiamo, join combina le righe dei file su un campo comune, che è il primo campo per impostazione predefinita. Tuttavia, se lo desideri, puoi specificare un campo diverso per ciascun file. Ad esempio, considera i seguenti contenuti in file1 e file2, rispettivamente.
* 1. Asia:
& 2. Africa:
@ 3. Europa:
# 4. Nord America:# 1. India
@ 2. Nigeria
& 3. Paesi Bassi
* 4. Stati UnitiOra, se desideri che il secondo campo di ciascuna riga sia il campo comune per join, puoi dirlo allo strumento utilizzando le opzioni da riga di comando -1 e -2. Mentre la prima rappresenta il primo file, la seconda si riferisce al secondo file. Queste opzioni richiedono un argomento numerico che si riferisce al campo di unione per il file corrispondente.
Ad esempio, nel nostro caso, il comando sarà:
join -1 2 -2 2 file1 file2Ed ecco l’output di questo comando:

Nota che nel caso in cui la posizione del campo comune sia la stessa in entrambi i file (come nell’esempio che abbiamo appena discusso, dove è 2), puoi sostituire la parte -1 [campo] -2 [campo] nel comando con -j [campo]. Quindi nel nostro caso, il comando diventerebbe:
join -j2 file1 file2
4. Come rendere l’operazione di join non sensibile al maiuscolo/minuscolo?
Per impostazione predefinita, l’operazione del comando join è sensibile al maiuscolo/minuscolo. Ad esempio, considera i seguenti file:
file1
A. Asia:
B. Africa:
C. Europa:
D. Nord America:file2
a. India
b. Nigeria
c. Paesi Bassi
d. Stati UnitiOra, se provi a unire questi due file, utilizzando il campo comune predefinito (primo), non succederà nulla. Questo perché il caso degli elementi del campo nei due file è diverso. Per far sì che join ignori questo problema di maiuscole/minuscole, usa l’opzione da riga di comando -i.
Ecco il comando per il nostro caso:
join -i file1 file2E il seguente screenshot mostra il comando in azione:
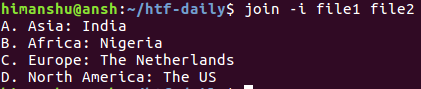
5. Come fare in modo che join non controlli l’input ordinato?
Per impostazione predefinita, il comando join controlla se l’input fornito è ordinato o meno, e segnala se non lo è. Ad esempio, considera il seguente output quando le informazioni in file1 non erano ordinate:
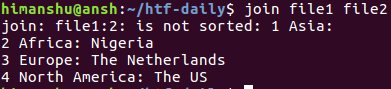
Ora, nel caso in cui tu voglia che questo errore/avviso scompaia, puoi farlo utilizzando l’opzione –nocheck-order. Ecco lo stesso comando, ma con questa opzione abilitata:

Quindi puoi vedere che il comando join non ha controllato l’input ordinato questa volta.
Conclusione
Join potrebbe non essere uno strumento molto semplice da comprendere, ma una volta che ti abitui, potrebbe rivelarsi un enorme risparmio di tempo per te in alcune situazioni. Abbiamo coperto la maggior parte delle opzioni della riga di comando qui. Prova queste, e una volta fatto, consulta la pagina man del comando per il resto.
Ricevi i nuovi post nella tua casella di posta.
Nessuno spam. Disiscriviti in qualsiasi momento.