Kubernetes · 2 min read · Nov 03, 2025
Kubernetesクラスターのコアコンポーネント

Kubernetesは、宣言型の構成と自動化を促進するコンテナ化されたワークロードとサービスを管理するためのオープンソースプラットフォームです。Kubernetesという名前は、ギリシャ語に由来し、舵取り手またはパイロットを意味します。Kubernetesはポータブルで拡張可能であり、急速に成長しているエコシステムを持っています。Kubernetesのサービスとツールは広く利用可能です。
この記事では、各コンテナが何で構成されているかから、ポッド内のコンテナがどのようにデプロイされ、各ワーカーにスケジュールされるかまで、Kubernetesの主要コンポーネントの10,000フィートのビューを通じて説明します。Kubernetesをコンテナ化されたアプリケーションのオーケストレーターとして使用してソリューションをデプロイおよび設計できるようにするためには、Kubernetesクラスターの詳細を理解することが重要です。
この記事でカバーする内容の概要は以下の通りです:
- コントロールプレーンコンポーネント
- Kubernetesワーカーのコンポーネント
- 基本的なビルディングブロックとしてのポッド
- Kubernetesサービス、ロードバランサー、およびIngressコントローラー
- Kubernetesデプロイメントとデーモンセット
- Kubernetesにおける永続ストレージ
Kubernetesコントロールプレーン
Kubernetesマスターノードは、コアコントロールプレーンサービスが存在する場所です。すべてのサービスが同じノードに存在する必要はありませんが、中央集権化と実用性のために、通常はこのようにデプロイされます。これは明らかにサービスの可用性に関する問題を引き起こしますが、複数のノードを持ち、負荷分散リクエストを提供することで、高可用性のマスターノードセットを実現することができます。
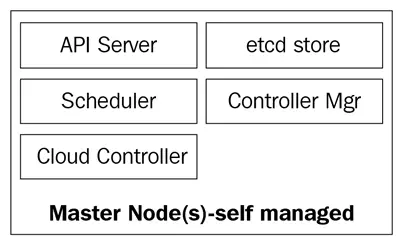
マスターノードは、次の4つの基本サービスで構成されています:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- etcdデータベース
マスターノードは、ベアメタルサーバー、仮想マシン、またはプライベートまたはパブリッククラウド上で実行できますが、コンテナワークロードを実行することは推奨されません。これについては後で詳しく見ていきます。
以下の図は、Kubernetesマスターノードのコンポーネントを示しています:
kube-apiserver
APIサーバーは、すべてを結びつけるものです。これは、サービス、ポッド、IngressなどのAPIオブジェクトを作成、更新、削除するためのマニフェストを受け取るクラスターのフロントエンドREST APIです。
kube-apiserverは、私たちが話すべき唯一のサービスであり、クラスターの状態を登録するためにetcdデータベースに書き込み、話す唯一のサービスでもあります。kubectlコマンドを使用して、これと対話するためのコマンドを送信します。これはKubernetesに関して私たちのスイスアーミーナイフになります。
kube-controller-manager
kube-controller-managerデーモンは、要するに、単一のバイナリに簡素化のために出荷された無限の制御ループのセットです。これは、クラスターの定義された望ましい状態を監視し、それを達成し満たすために必要なすべてのビットとピースを移動させることを確認します。kube-controller-managerは単一のコントローラーではなく、クラスター内の異なるコンポーネントを監視するいくつかの異なるループを含んでいます。その中には、サービスコントローラー、ネームスペースコントローラー、サービスアカウントコントローラーなどが含まれます。各コントローラーとその定義は、Kubernetes GitHubリポジトリで見つけることができます: https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
kube-scheduler
kube-schedulerは、新しく作成されたポッドを、ポッドのリソースニーズを満たすために十分なスペースを持つノードにスケジュールします。基本的に、kube-apiserverとkube-controller-managerから新しく作成されたポッドをキューに入れ、スケジューラーによって利用可能なノードにスケジュールします。kube-schedulerの定義はここにあります: https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
計算リソースに加えて、kube-schedulerはノードのアフィニティおよびアンチアフィニティルールを読み取り、ノードがそのポッドを実行できるかどうかを判断します。
etcdデータベース
etcdデータベースは、Kubernetesクラスターの状態を保存するために使用される非常に信頼性の高い一貫したキー・バリューストアです。これは、ノードが実行しているポッドの現在の状態、クラスターに現在存在するノードの数、これらのノードの状態、実行中のデプロイメントのレプリカの数、サービス名などを含んでいます。
前述のように、kube-apiserverのみがetcdデータベースと対話します。kube-controller-managerがクラスターの状態を確認する必要がある場合、etcdストアに直接クエリを送るのではなく、APIサーバーを介してetcdデータベースから状態を取得します。スケジューラーがポッドが停止したり別のノードに割り当てられたことを知らせる必要がある場合も同様で、APIサーバーに通知し、APIサーバーが現在の状態をetcdデータベースに保存します。
etcdを使用することで、Kubernetesマスターノードの主要コンポーネントをすべてカバーし、クラスターを管理する準備が整いました。しかし、クラスターはマスターだけで構成されるわけではなく、アプリケーションを実行するために重労働を行うノードが必要です。
Kubernetesワーカーノード
Kubernetesでこのタスクを実行するワーカーノードは、単にノードと呼ばれます。以前は2014年頃、彼らはミニオンと呼ばれていましたが、この用語は後にノードという名前に置き換えられました。これは、Saltの用語と混同され、人々がSaltがKubernetesで重要な役割を果たしていると考えるようになったためです。
これらのノードは、ワークロードを実行する唯一の場所であり、マスターノードにコンテナや負荷を持たせることは推奨されません。マスターノードはクラスター全体を管理するために利用可能である必要があります。ノードはコンポーネントの観点から非常にシンプルであり、タスクを実行するために必要なサービスは3つだけです:
- Kubelet
- Kube-proxy
- コンテナランタイム
これらの3つのコンポーネントをもう少し深く探ってみましょう。
kubelet
kubeletは、低レベルのKubernetesコンポーネントであり、kube-apiserverの後で最も重要なものの1つです。これらのコンポーネントは、クラスター内のポッド/コンテナのプロビジョニングに不可欠です。kubeletはKubernetesノード上で実行され、ポッドの作成のためにAPIサーバーを監視します。kubeletは、ポッド内のコンテナを開始/停止し、それらが健康であることを確認する責任があります。kubeletは、自身によって作成されていないコンテナを管理することはできません。
kubeletは、コンテナランタイムインターフェース(CRI)を介してコンテナランタイムと対話することで目標を達成します。CRIは、gRPCクライアントを介してkubeletにプラグイン可能性を提供し、異なるコンテナランタイムと対話できるようにします。前述のように、Kubernetesはコンテナをデプロイするために複数のコンテナランタイムをサポートしており、これによりさまざまなエンジンに対する多様なサポートを実現しています。
kubeletのソースコードは、https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet で確認できます。
kube-proxy
kube-proxyは、クラスターの各ノードに存在するサービスであり、ポッド、コンテナ、およびノード間の通信を可能にします。このサービスは、定義されたサービスの変更を監視するためにkube-apiserverを監視し、iptablesルールを介して正しいエンドポイントにトラフィックを転送することでネットワークを最新の状態に保ちます。kube-proxyは、サービスの背後にあるポッド間でランダムな負荷分散を行うiptablesのルールも設定します。
以下は、kube-proxyによって作成されたiptablesルールの例です:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment –comment “default/example: has no endpoints” -m tcp –dport 80 -j REJECT –reject-with icmp-port-unreachable
これはエンドポイントがないサービス(背後にポッドがない)であることに注意してください。
コンテナランタイム
コンテナを起動するためには、コンテナランタイムが必要です。これは、ノードのカーネル内でポッドを実行するためにコンテナを作成する基本的なエンジンです。kubeletはこのランタイムと対話し、必要に応じてコンテナを起動または停止します。
現在、KubernetesはDocker、rkt、runc、runscなどのOCI準拠のコンテナランタイムをサポートしています。
詳細については、https://github.com/opencontainers/runtime-spec を参照してください。
すべてのコアコンポーネントを探求したので、次にそれらを使用して何ができるか、Kubernetesがどのように私たちのコンテナ化されたアプリケーションをオーケストレーションおよび管理するのかを見ていきましょう。
Kubernetesオブジェクト
Kubernetesオブジェクトは、まさにそれです:それは論理的な永続オブジェクトまたは抽象であり、クラスターの状態を表します。あなたが望むオブジェクトの状態をKubernetesに伝える責任があります。そうすれば、Kubernetesはそれを維持し、そのオブジェクトが存在することを確認するために作業します。
オブジェクトを作成するには、2つのものが必要です:状態とその仕様。状態はKubernetesによって提供され、オブジェクトの現在の状態です。Kubernetesは、望ましい状態に従ってその状態を管理および更新します。一方、仕様フィールドは、あなたがKubernetesに提供するものであり、望むオブジェクトを説明するために伝えるものです。たとえば、コンテナが実行するイメージ、実行したいそのイメージのコンテナの数などです。
各オブジェクトには、実行するタスクのタイプに特有の仕様フィールドがあり、これらの仕様を含むYAMLファイルをkube-apiserverに送信し、kube-apiserverがそれをJSONに変換してAPIリクエストとして送信します。後でこの記事で各オブジェクトとその仕様フィールドについて詳しく見ていきます。
以下は、kubectlに送信されたYAMLの例です:
cat << EOF | kubectl create -f -kind: ServiceapiVersion: v1metadata: Name: frontend-servicespec: selector: web: frontend ports: - protocol: TCP port: 80 targetPort: 9256EOF
オブジェクト定義の基本フィールドは最初のものであり、これらはオブジェクトごとに変わることはなく、非常に自己説明的です。これらを簡単に見てみましょう:
- kind: kindフィールドは、Kubernetesにあなたが定義しているオブジェクトのタイプ(ポッド、サービス、デプロイメントなど)を伝えます。
- apiVersion: Kubernetesは複数のAPIバージョンをサポートしているため、定義を送信したいREST APIパスを指定する必要があります。
- metadata: これはネストされたフィールドであり、オブジェクトの名前を記述したり、特定のネームスペースに割り当てたり、他のKubernetesオブジェクトに関連付けるためのラベルをタグ付けしたりする基本的な定義を記述するためのサブフィールドがいくつかあります。
これで、最も使用されるフィールドとその内容を見てきました。Kubernetes APIの規約については、https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md でさらに学ぶことができます。
オブジェクトのいくつかのフィールドは、オブジェクトが作成された後に変更される可能性がありますが、それはオブジェクトと変更したいフィールドによります。
以下は、作成できるさまざまなKubernetesオブジェクトの短いリストです:
- ポッド
- ボリューム
- サービス
- デプロイメント
- Ingress
- シークレット
- ConfigMap
他にもたくさんあります。
これらの項目のそれぞれを詳しく見てみましょう。
ポッド – Kubernetesの基礎
ポッドはKubernetesで最も基本的なオブジェクトであり、最も重要なものでもあります。すべてはそれらの周りに回っています。Kubernetesはポッドのために存在すると言えます!他のすべてのオブジェクトはそれらに仕えるために存在し、彼らが行うすべてのタスクはポッドが望む状態を達成するためのものです。
では、ポッドとは何であり、なぜポッドがそれほど重要なのでしょうか?
ポッドは、同じネットワーク名前空間、同じプロセス間通信(IPC)、および場合によってはKubernetesのバージョンに応じて同じプロセスID(PID)名前空間で一緒に1つ以上のコンテナを実行する論理オブジェクトです。これは、コンテナを実行し、したがって注目の中心となるものです。Kubernetesの全体の目的はコンテナオーケストレーターであり、ポッドを使用することでオーケストレーションが可能になります。
前述のように、同じポッド内のコンテナは「バブル」に住んでおり、localhostを介して互いに話すことができます。これは、彼らが互いにローカルであるためです。ポッド内の1つのコンテナは、他のコンテナと同じIPアドレスを持っています。なぜなら、彼らはネットワーク名前空間を共有しているからです。しかし、ほとんどの場合、1対1の基準で実行されます。つまり、ポッドごとに単一のコンテナです。ポッドごとに複数のコンテナを使用するのは、データプッシャーやプロキシなど、主要なアプリケーションと迅速かつ堅牢に通信する必要があるヘルパーが必要な非常に特定のシナリオでのみ使用されます。
ポッドを定義する方法は、他のKubernetesオブジェクトを定義するのと同じ方法です:ポッドの仕様と定義を含むYAMLを介して:
kind: PodapiVersion: v1metadata:name: hello-podlabels: hello: podspec: containers: - name: hello-container image: alpine args: - echo - “Hello World”
ポッドを作成するために必要な基本的なポッド定義をspecフィールドの下で見てみましょう:
- Containers: コンテナは配列です。したがって、いくつかのサブフィールドのセットがあります。基本的には、ポッドで実行されるコンテナを定義するものです。コンテナの名前、スピンオフするイメージ、実行する必要がある引数やコマンドを指定できます。引数とコマンドの違いは、CMDとENTRYPOINTの違いと同じです。すべてのフィールドはコンテナ配列のものであり、ポッドのspecの直接の一部ではないことに注意してください。
- restartPolicy: このフィールドはまさにそれです。Kubernetesにコンテナに対して何をするべきかを伝え、ゼロまたは非ゼロの終了コードの場合、ポッド内のすべてのコンテナに適用されます。Never、OnFailure、Alwaysのいずれかを選択できます。restartPolicyが定義されていない場合、Alwaysがデフォルトになります。
これらはポッドで宣言する最も基本的な仕様です。他の仕様は、使用方法やさまざまなKubernetesオブジェクトとの相互作用についてもう少し背景知識が必要です。後でこの記事で再訪します。以下はその一部です:
- ボリューム
- 環境変数
- ポート
- dnsPolicy
- initContainers
- nodeSelector
- リソース制限とリクエスト
クラスター内で現在実行中のポッドを表示するには、kubectl get podsを実行できます:
dsala@MININT-IB3HUA8:~$ kubectl get podsNAME READY STATUS RESTARTS AGEbusybox 1/1 Running 120 5d
または、kubectl describe podsを指定せずに実行できます。これにより、クラスター内で実行中のすべてのポッドの説明が表示されます。この場合、現在実行中の唯一のポッドであるbusyboxポッドのみが表示されます:
dsala@MININT-IB3HUA8:~$ kubectl describe podsName: busyboxNamespace: defaultPriority: 0PriorityClassName:
ポッドは一時的です。一度死ぬか削除されると、回復することはできません。そのIPとその上で実行されていたコンテナは消えます。彼らは完全に儚いです。ボリュームとしてマウントされたポッドのデータは、設定によっては生き残ることもあれば、そうでないこともあります。ポッドが死んで失われた場合、すべてのマイクロサービスが実行されていることをどうやって保証するのでしょうか?それに対する答えはデプロイメントです。
デプロイメント
ポッドだけではあまり役に立ちません。なぜなら、単一のポッド内でアプリケーションのインスタンスを複数持つことは非常に効率的ではないからです。異なるポッドにアプリケーションの何百ものコピーをプロビジョニングする方法がなければ、すぐに手に負えなくなります。
ここでデプロイメントが登場します。デプロイメントを使用すると、コントローラーでポッドを管理できます。これにより、実行する数を決定できるだけでなく、コンテナが実行するイメージのバージョンやイメージ自体を変更することで更新を管理できます。デプロイメントは、ほとんどの時間で作業することになるものです。デプロイメントは、ポッドや前述の他のオブジェクトと同様に、YAMLファイル内に独自の定義を持っています:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deployment labels: deployment: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
デプロイメントの定義を探求してみましょう。
YAMLの最初の部分には、apiVersion、kind、metadataなどの一般的なフィールドがあります。しかし、specの下には、このAPIオブジェクトの特定のオプションが見つかります。
specの下に追加できるフィールドは次のとおりです:
Selector: Selectorフィールドを使用すると、変更が適用されるときにデプロイメントがターゲットとするポッドを知ることができます。selectorの下で使用する2つのフィールドがあります:matchLabelsとmatchExpressions。matchLabelsを使用すると、セレクターはポッドのラベル(キー/値ペア)を使用します。ここで指定するすべてのラベルはANDされることに注意してください。つまり、ポッドはmatchLabelsの下で指定したすべてのラベルを持っている必要があります。
Replicas: これは、デプロイメントがレプリケーションコントローラーを介して実行し続ける必要があるポッドの数を示します。たとえば、3つのレプリカを指定し、1つのポッドが死んだ場合、レプリケーションコントローラーは望ましい状態としてレプリカの仕様を監視し、新しいポッドをスケジュールするようスケジューラーに通知します。現在の状態はポッドが死んだため2になっています。
RevisionHistoryLimit: デプロイメントに変更を加えるたびに、この変更はデプロイメントのリビジョンとして保存され、後でその以前の状態に戻すか、変更された内容の記録を保持できます。kubectl rollout history deployment/<デプロイメント名>で履歴を確認できます。revisionHistoryLimitを使用すると、保存したいレコードの数を設定できます。
Strategy: これにより、更新や水平ポッドスケールをどのように処理したいかを決定できます。デフォルトのrollingUpdateを上書きするには、typeキーを記述する必要があります。ここで、recreateまたはrollingUpdateの2つの値のいずれかを選択できます。
recreateはデプロイメントを更新するための迅速な方法ですが、すべてのポッドを削除し、新しいポッドに置き換えることになりますが、この戦略ではシステムのダウンタイムを考慮する必要があります。一方、rollingUpdateはスムーズで遅く、データを再バランスできるステートフルアプリケーションに最適です。rollingUpdateは、maxSurgeとmaxUnavailableという2つのフィールドの扉を開きます。
最初のフィールドは、更新を行う際に必要なポッドの合計数を超える数です。たとえば、100ポッドのデプロイメントで20%のmaxSurgeを指定すると、更新中に最大120ポッドに増加します。次のオプションでは、100ポッドのシナリオで新しいポッドに置き換えるために殺すことを許可するポッドのパーセンテージを選択できます。20%のmaxUnavailableの場合、20ポッドのみが殺され、新しいポッドに置き換えられた後、残りのデプロイメントの置き換えが続行されます。
Template: これは、デプロイメントが管理するポッドのすべての仕様とメタデータを含むネストされたポッド仕様フィールドです。
デプロイメントを使用すると、ポッドを管理し、望ましい状態を維持するのに役立ちます。これらのポッドはすべて、クラスター ネットワークと呼ばれるものに存在し、これはKubernetesクラスターコンポーネントのみが互いに通信できる閉じたネットワークであり、独自のIP範囲を持っています。外部からポッドにアクセスするにはどうすればよいでしょうか?アプリケーションにアクセスするにはどうすればよいでしょうか?ここでサービスが登場します。
サービス:
サービスという名前は、Kubernetesでサービスが実際に行うことを完全には説明していません。Kubernetesサービスは、トラフィックをポッドにルーティングするものです。サービスはポッドを結びつけるものです。
フロントエンド/バックエンドタイプのアプリケーションを想像してみましょう。フロントエンドポッドがバックエンドポッドとポッドのIPアドレスを介して通信している場合、バックエンドのポッドが死ぬと、バックエンドとの通信を失います。これは、バックエンドのポッドが死んだポッドのIPアドレスを持たないだけでなく、新しいIPアドレスを使用するようにアプリを再構成する必要があるからです。この問題や類似の問題は、サービスによって解決されます。
サービスは、kube-proxyにサービスの背後にあるポッドに基づいてiptablesルールを作成するように指示する論理オブジェクトです。サービスは、エンドポイントを構成します。これは、サービスの背後にあるポッドの呼び方であり、デプロイメントがどのポッドを制御するかを知る方法と同じように、セレクターフィールドとポッドのラベルを使用します。
この図は、サービスがラベルを使用してトラフィックを管理する方法を示しています:
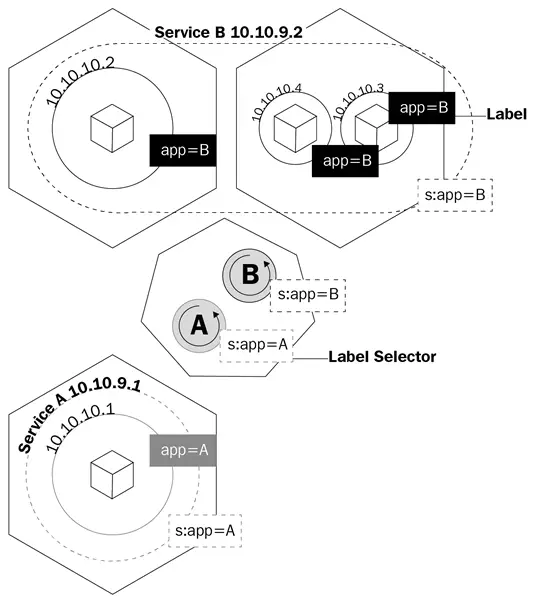
サービスは、kube-proxyにトラフィックをルーティングするルールを作成させるだけでなく、kube-dnsと呼ばれるものをトリガーします。
Kube-dnsは、クラスター上で実行されるSkyDNSコンテナを持つポッドのセットであり、DNSサーバーとフォワーダーを提供し、サービスや時にはポッドのためのレコードを作成します。サービスを作成するたびに、サービスの内部クラスターIPアドレスを指すDNSレコードがservice-name.namespace.svc.cluster.localの形式で作成されます。Kubernetes DNS仕様については、こちらで詳しく学ぶことができます:https://github.com/kubernetes/dns/blob/master/docs/specification.md。
例に戻ると、アプリケーションをサービスの完全修飾ドメイン名(FQDN)に話しかけるように構成するだけで、バックエンドポッドと通信できます。このようにすれば、ポッドとサービスのIPアドレスが何であっても問題ありません。サービスの背後にあるポッドが死んだ場合、サービスはAレコードを使用してすべてを処理します。これにより、フロントエンドにすべてのトラフィックをmy-svcにルーティングするように指示できます。サービスのロジックが他のすべてを処理します。
Kubernetesで作成するオブジェクトを宣言する際に作成できるサービスのさまざまなタイプがあります。それらを見て、どれが必要な作業に最も適しているかを見てみましょう:
ClusterIP: これはデフォルトのサービスです。ClusterIPサービスを作成すると、Kubernetesクラスター内でのみルーティング可能なクラスター内部IPアドレスを持つサービスが作成されます。このタイプは、ポッドが互いに通信するだけで、クラスターの外に出る必要がない場合に最適です。
NodePort: このタイプのサービスを作成すると、デフォルトで30000から32767のランダムなポートが割り当てられ、サービスのエンドポイントポッドにトラフィックを転送します。この動作をオーバーライドするには、ポート配列でノードポートを指定します。これが定義されると、<ノードのIP>:<ノードポート>を介してポッドにアクセスできるようになります。これは、ノードのIPアドレスを介してクラスターの外部からポッドにアクセスするのに便利です。
LoadBalancer: ほとんどの場合、クラウドプロバイダーでKubernetesを実行します。このタイプは、これらの状況に最適で、クラウドプロバイダーのAPIを介してサービスにパブリックIPアドレスを割り当てることができます。これは、クラスターの外部からポッドと通信したい場合に最適なサービスです。LoadBalancerを使用すると、パブリックIPアドレスを割り当てるだけでなく、Azureを使用して仮想プライベートネットワークからプライベートIPアドレスを割り当てることもできます。これにより、インターネットまたはプライベートサブネット内でポッドと通信できます。
サービスのYAML定義を見てみましょう:
apiVersion: v1kind: Servicemetadata: name: my-servicespec: selector: app: front-end type: NodePort ports: - name: http port: 80 targetPort: 8080 nodePort: 30024 protocol: TCP
サービスのYAMLは非常にシンプルであり、仕様は作成するサービスのタイプによって異なります。しかし、最も重要なことはポート定義です。これらを見てみましょう:
- port: これは公開されるサービスポートです。
- targetPort: これはサービスがトラフィックを送信しているポッドのポートです。
- nodePort: これは公開されるポートです。
クラスター内のポッドと通信する方法を理解したものの、ポッドが終了するたびにデータを失う問題をどのように管理するかを理解する必要があります。ここで永続的ボリューム(PV)が役立ちます。
Kubernetesと永続ストレージ
コンテナの世界における永続ストレージは深刻な問題です。コンテナの実行間で永続的なストレージは、イメージのレイヤーのみであり、これらは読み取り専用です。コンテナが実行されるレイヤーは読み書き可能ですが、このレイヤー内のすべてのデータはコンテナが停止すると削除されます。ポッドでも同様です。コンテナが死ぬと、その上に書き込まれたデータは消えます。
Kubernetesには、ポッド間でストレージを管理するためのオブジェクトのセットがあります。最初に議論するのはボリュームです。
ボリューム
ボリュームは、永続ストレージに関する最大の問題の1つを解決します。まず、ボリュームは実際にはオブジェクトではなく、ポッドの仕様の定義です。ポッドを作成するとき、ポッドの仕様フィールドの下にボリュームを定義できます。このポッド内のコンテナは、マウント名前空間にボリュームをマウントでき、ボリュームはコンテナの再起動やクラッシュを超えて利用可能になります。ただし、ボリュームはポッドに結びついており、ポッドが削除されるとボリュームも消えます。ボリューム内のデータは別の話であり、データの永続性はそのボリュームのバックエンドに依存します。
Kubernetesは、ローカルノードからのファイルシステムマップ、クラウドプロバイダーの仮想ディスク、ソフトウェア定義ストレージバックボリュームなど、さまざまなタイプのボリュームまたはボリュームソースをサポートしています。ローカルファイルシステムマウントは、通常のボリュームに関して最も一般的に見られるものです。ローカルノードファイルシステムを使用することの欠点は、データがクラスターのすべてのノードで利用できず、ポッドがスケジュールされたノードでのみ利用可能であることです。
ボリュームを持つポッドがYAMLでどのように定義されるかを見てみましょう:
apiVersion: v1kind: Podmetadata: name: test-pdspec: containers: - image: k8s.gcr.io/test-webserver name: test-container volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: path: /data type: Directory
specの下にvolumesというフィールドがあり、次にvolumeMountsという別のフィールドがあります。
最初のフィールド(volumes)は、そのポッドのために作成したいボリュームを定義する場所です。このフィールドは常に名前を必要とし、その後ボリュームソースが続きます。ソースに応じて、要件は異なります。この例では、ソースはノードのローカルファイルシステムであるhostPathです。hostPathは、ディレクトリ、ファイル、ブロックデバイス、さらにはUnixソケットなど、さまざまなタイプのマッピングをサポートしています。
2番目のフィールドであるvolumeMountsには、ボリュームをマウントするコンテナ内のパスを定義するmountPathがあります。nameパラメータは、ポッドがどのボリュームを使用するかを指定する方法です。これは重要です。なぜなら、volumesの下にいくつかのタイプのボリュームを定義でき、名前がポッドがどのボリュームを使用するかを知る唯一の方法になるからです。
さまざまなタイプのボリュームについては、こちらを参照してください:https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes およびKubernetes APIリファレンスドキュメント(https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.11/#volume-v1-core)。
ポッドと共にボリュームが消えるのは理想的ではありません。私たちは永続するストレージが必要であり、これがPVの必要性が生じた理由です。
永続ボリューム、永続ボリューム要求、およびストレージクラス
ボリュームとPVの主な違いは、PVが実際にはKubernetes APIオブジェクトであるため、ボリュームとは異なり、個別のエンティティとして管理でき、したがってポッドが削除された後も永続します。
このサブセクションにPV、永続 ボリューム 要求(PVC)、およびストレージクラスがすべて混在している理由を疑問に思うかもしれません。これは、すべてが互いに依存しており、ポッドのストレージをプロビジョニングするためにどのように相互作用するかを理解することが重要だからです。
PVとPVCから始めましょう。ボリュームと同様に、PVにはストレージソースがあり、ボリュームが持つのと同じメカニズムがここに適用されます。ソフトウェア定義ストレージクラスターが論理 ユニット 番号(LUN)を提供するか、クラウドプロバイダーが仮想ディスクを提供するか、またはKubernetesノードのローカルファイルシステムを提供しますが、ここではボリュームソースではなく永続 ボリューム タイプと呼ばれます。
PVは、ストレージアレイのLUNのようなもので、作成しますが、マッピングはありません。単に使用されるのを待っている割り当てられたストレージの束です。PVCはLUNマッピングのようなもので、PVにバックアップまたはバインドされており、ポッドが使用できるように実際に定義、関連付け、および利用可能にするものです。
ポッドでPVCを使用する方法は、通常のボリュームとまったく同じです。2つのフィールドがあります。1つは使用したいPVCを指定し、もう1つはそのPVCをどのコンテナで使用するかをポッドに伝えます。
PVC APIオブジェクト定義のYAMLは次のようになります:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: gluster-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi
ポッドのYAMLは次のようになります:
kind: PodapiVersion: v1metadata: name: mypodspec: containers: - name: myfrontend image: nginx volumeMounts: - mountPath: “/mnt/gluster” name: volume volumes: - name: volume persistentVolumeClaim: claimName: gluster-pvc
Kubernetes管理者がPVCを作成するとき、この要求を満たす方法は2つあります:
- 静的: いくつかのPVがすでに作成されており、ユーザーがPVCを作成すると、要件を満たす任意の利用可能なPVがそのPVCにバインドされます。
- 動的: 一部のPVタイプは、PVC定義に基づいてPVを作成できます。PVCが作成されると、PVタイプは動的にPVオブジェクトを作成し、バックエンドにストレージを割り当てます。これが動的プロビジョニングです。動的プロビジョニングの注意点は、Kubernetesストレージオブジェクトの3番目のタイプ、ストレージ クラスが必要であることです。
ストレージクラスは、ストレージを階層化する方法のようなものです。遅いストレージボリュームをプロビジョニングするクラスを作成したり、超高速SSDドライブを持つ別のクラスを作成したりできます。ただし、ストレージクラスは単なる階層化よりも少し複雑です。PVCを作成する2つの方法で述べたように、ストレージクラスは動的プロビジョニングを可能にします。クラウド環境で作業している場合、すべてのPVのために手動でバックエンドディスクを作成したくはありません。ストレージクラスは、クラウドプロバイダーのAPIと対話するために必要なボリュームプラグインを呼び出すプロビジョナーと呼ばれるものを設定します。各プロビジョナーには、指定されたクラウドプロバイダーまたはストレージプロバイダーと対話するための独自の設定があります。
ストレージクラスを次のようにプロビジョニングできます。これは、Azure-diskをディスクプロビジョナーとして使用するストレージクラスの例です:
kind: StorageClassapiVersion: storage.k8s.io/v1metadata: name: my-storage-classprovisioner: kubernetes.io/azure-diskparameters: storageaccounttype: Standard_LRS kind: Shared
各ストレージクラスプロビジョナーとPVタイプには、ボリュームと同様に異なる要件とパラメータがあります。これまでのところ、彼らがどのように機能し、何に使用できるかについての一般的な概要を持っています。特定のストレージクラスやPVタイプについて学ぶことは、あなたの環境に依存します。各ストレージクラスについては、以下のリンクをクリックしてさらに学ぶことができます:
- https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner
- https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
この記事では、Kubernetesとは何か、そのコンポーネント、オーケストレーションを使用する利点について学びました。これにより、各Kubernetes APIオブジェクト、その目的、および使用例を特定することが容易になるはずです。マスターノードがクラスターを制御し、ワーカーノードのコンテナをスケジュールする方法を理解できるようになったはずです。
この記事が役に立った場合は、‘ Hands-On Linux for Architects ’があなたにとって役立つでしょう。この本では、Linuxコンポーネントや機能からハードウェアやソフトウェアのサポートまで、効果的なLinuxベースのソリューションを実装し、調整するのに役立つすべてをカバーします。Linux設計方法論とソリューション設計のコアコンセプトの概要を説明します。Linuxシステム管理者、Linuxサポートエンジニア、DevOpsエンジニア、Linuxコンサルタント、またはアーキテクチャに関する知識を学びたい、または拡張したい人にとって、この本はあなたのためのものです。
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。