クラスタ展開 · 1 min read · Nov 10, 2025
障害耐性クラスタを継続的または高可用性で展開する方法
一部の企業は、サービスがダウンすることを許可できません。サーバーの障害が発生した場合、通信事業者は請求システムのダウンタイムを経験し、すべてのクライアントとの接続が失われる可能性があります。このような状況の潜在的な影響を認識することは、常にプランBを持つという考えにつながります。
この記事では、サーバー障害に対する保護のさまざまな方法と、高可用性クラスタを構築するためのコントロールパネルであるVMmanager Cloudの展開に使用されるアーキテクチャについて説明します。

前書き
クラスタ耐性の分野における用語は、ウェブサイトによって異なります。異なる用語や定義が混在しないように、この記事で使用される用語を以下に示します:
- 障害耐性(FT)は、システムがそのコンポーネントの1つが故障した後も運用を続ける能力です。
- クラスタは、通信チャネルを介して接続されたサーバーのグループ(クラスタノード)です。
- 障害耐性クラスタ(FTC)は、1つのサーバーの故障がクラスタ全体の完全な利用不可を引き起こさないクラスタです。故障したノードの機能は、残りのノード間で自動的に再割り当てされます。
- 継続的可用性(CA)とは、ユーザーがタイムアウトを経験することなくサービスを利用できることを意味します。ノードが故障してからどれだけの時間が経過したかは関係ありません。
- 高可用性(HA)とは、ノードの1つがダウンした場合にユーザーがサービスのタイムアウトを経験する可能性があることを意味します。ただし、システムは最小限のダウンタイムで自動的に回復します。
- CAクラスタは、継続的可用性クラスタです。
- HAクラスタは、高可用性クラスタです。
10ノードからなるクラスタを展開する必要があると仮定します。各ノードには仮想マシンが実行されています。目標は、サーバーの故障後に仮想マシンを保護することです。ラックの計算密度を最大化するために、デュアルCPUサーバーが使用されます。
一見すると、機器が故障した後もサービスが提供される継続的可用性クラスタを展開することが企業にとって最も魅力的な選択肢です。実際、請求システムの運用を維持する必要がある場合や、継続的な生産プロセスを自動化する必要がある場合、継続的可用性は必須です。しかし、このアプローチには罠や落とし穴もあり、以下で説明します。
継続的可用性
サービスの継続性は、このサービスを持つ物理または仮想マシンの正確なコピーがいつでも利用可能である場合にのみ実現可能です。このような冗長性モデルは2Nと呼ばれます。機器が故障した後にサーバーのコピーを作成するには時間がかかり、サービスのタイムアウトを引き起こします。さらに、この場合、故障したサーバーからRAMダンプを取得することはできず、そこに含まれるすべての情報が失われることを意味します。
CAを提供するために使用される方法は2つあります:ハードウェア層とソフトウェア層です。それぞれについて詳しく見ていきましょう。
ハードウェア方式は、すべてのコンポーネントが複製され、計算が同時に独立して実行されるダブルサーバーを表します。同期は、両方の部分からの結果をチェックする専用ノードを使用して達成されます。ノードが不一致を検出した場合、問題を特定し、エラーを修正しようとします。エラーが修正できない場合、システムは故障したモジュールをオフにします。
CAサーバーの製造業者であるStratusは、システムの全体的なダウンタイムが年間32秒を超えないことを保証しています。このような結果は、特別な機器を使用することで達成できます。Stratusの代表者によると、各同期モジュール用のデュアルCPUを持つCAサーバー1台のコストは、仕様に応じて約160,000ドルです。この場合、全体のCAクラスタの拡張価格は1,600,000ドルになります。
ソフトウェア方式
この記事の時点で、継続的可用性クラスタの展開に最も人気のあるソフトウェアツールはVMware vSphereです。この製品の継続的可用性技術は障害耐性と呼ばれています。
ハードウェア方式とは異なり、この技術には以下のような特定の要件があります:
- 物理ホスト上のCPU:- Sandy Bridgeアーキテクチャ(またはそれ以降)のIntel。Avotonはサポートされていません。
- AMD Bulldozer(またはそれ以降)。
- 障害耐性のあるマシンは、低遅延の1つの10 Gbネットワークに接続されている必要があります。VMwareは専用ネットワークの使用を強く推奨しています。
- VMごとに4つ以上の仮想CPUは不可。
- 物理ホストごとに8つ以上の仮想CPUは不可。
- 物理ホストごとに4つ以上の仮想マシンは不可。
- 仮想マシンスナップショットは利用できません。
- ストレージvMotionは利用できません。
制限事項と互換性のない項目の完全なリストは公式文書に記載されています。
vSphereのライセンスは物理CPUに基づいています。価格はライセンスあたり1750ドルから始まり、年間サブスクリプションとサポートに550ドルが追加されます。クラスタ管理の自動化には、8000ドル以上のVMware vCenter Serverも必要です。継続的可用性を提供するために2Nモデルが使用されるため、10ノードのクラスタを構築するには、各サーバーにライセンスを持つ10台の複製サーバーを購入する必要があります。
ソフトウェアの総コストは2[サーバーあたりのCPU数] (10[仮想マシンを持つノード数] + 10[複製ノード数]) (1750 + 550)[各CPUのライセンスコスト] + 8000[VMware vCenter Serverのコスト] = 100,000ドルです。すべての価格は四捨五入されています。
特定のノード構成はこの記事では説明されていません。サーバーコンポーネントは常にクラスタの目的に応じて異なるためです。ネットワーク機器についても説明されていません。なぜなら、すべてのケースで同一であるべきだからです。この記事は、確実に異なるコンポーネント、すなわちライセンスコストに焦点を当てています。
開発およびサポートが終了した製品についても言及することが重要です。
Remusという製品は、Xen仮想化に基づいています。これは、マイクロスナップショット技術を利用する無料のオープンソースソリューションです。残念ながら、その文書は長い間更新されていません:インストールガイドは、2014年にEOLが発表されたUbuntu 12.10の手順を提供しています。Google検索でも、Remusを使用している企業は見つかりませんでした。
QEMUを修正してこの技術で継続的可用性クラスタを構築する試みが行われました。この方向で作業を発表したプロジェクトが2つあります。
最初のプロジェクトは、田村義明がリードするオープンソース製品のKemariです。このプロジェクトは、ライブQEMUマイグレーションを使用することを意図していました。最後のコミットは2011年2月に行われており、開発が行き詰まり、続行されないことを示唆しています。
2番目の製品は、マイケル・ハインズによって設立されたオープンソースプロジェクトのMicro Checkpointingです。過去1年間の変更ログには活動が見られず、Kemariプロジェクトに似ています。
これらの事実から、現時点でKVM仮想化における継続的可用性の可能性は単に存在しないという結論を導くことができます。
継続的可用性システムのすべての利点にもかかわらず、そのようなソリューションを展開し運用するには多くの障害があります。それにもかかわらず、場合によっては障害耐性が必要ですが、常に利用可能である必要はありません。このようなシナリオでは、高可用性のクラスタを使用することができます。
高可用性
高可用性クラスタは、ハードウェアがダウンしているかどうかを自動的に検出し、その後利用可能なノードでサービスを起動することによって障害耐性を提供します。
高可用性は、ノードで起動されたCPUの同期をサポートせず、ローカルディスクの同期を常に許可するわけではありません。このことを考慮して、ノードによって使用されるドライブは、ネットワークストレージなどの独立したストレージに配置することをお勧めします。
理由は明らかです:ノードは故障後に到達できず、そのストレージデバイスからの情報を取得することはできません。データストレージシステムも障害耐性が必要です。そうでなければ、高可用性は実現できません。その結果、高可用性クラスタは2つのサブクラスタで構成されます:
- 仮想マシンを持つノードからなる計算クラスタ
- 計算ノードによって使用されるディスクを持つストレージクラスタ。
現在、クラスタノード上の仮想マシンを使用して高可用性クラスタを実装するために使用されているソリューションは以下の通りです:
- Heartbeat、バージョン1.?とDRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering with Hyper-V server role;
- VMmanager Cloud。
VMmanager Cloudを詳しく見てみましょう。
VMmanager Cloud
VMmanager Cloudは、高可用性クラスタを展開することを可能にし、QEMU-KVM仮想化を使用する製品です。この技術は、積極的に開発およびサポートされており、仮想マシンに任意のオペレーティングシステムをインストールできるため選ばれました。この製品は、クラスタの可用性を検出するためにCorosyncを使用します。サーバーの1つがダウンした場合、VMmanagerは残りのノード間でその仮想マシンを1つずつ分配します。
簡略化された形でこのメカニズムは次のように機能します:
- システムは、仮想マシンの数が最も少ないクラスタノードを特定します。
- マシンを配置するのに十分なRAMがあるかどうかを確認します。
- 関連するマシンのためにノードに十分なメモリがある場合、VMmanagerはこのノードに新しい仮想マシンを作成します。
- メモリが不足している場合、システムは他のノードをチェックし、より多くの仮想マシンを持つノードを探します。
いくつかのハードウェア構成をテストし、多くの現在のVMmanager Cloudユーザーに問い合わせた結果、通常、故障したノードからすべてのVMの操作を分配し復元するのに45〜90秒かかることが確認されました。これは、機器の性能によって異なります。
緊急事態に対する保護策として1つまたは複数のノードを専用にし、通常の運用中にこれらのノードにVMを展開しないことをお勧めします。これにより、故障したノードからの仮想マシンを追加するために、ライブクラスタノードでリソースが不足する可能性が最小限に抑えられます。バックアップノードが1つだけ使用される場合、このようなセキュリティモデルはN+1と呼ばれます。
VMmanager Cloudは、ファイルシステム、LVM、ネットワークLVM、iSCSI、Ceph(特にRBD(RADOS Block Device)、Cephの実装の1つ)などのストレージタイプをサポートしています。後者の3つは高可用性に使用されます。
10の運用ノードと1つのバックアップノードの生涯ライセンスは、現在3520ユーロ、または3865ドルです(1ライセンスあたり320ユーロ、CPU数に関係なく)。ライセンスには1年間の無料アップデートが含まれています。2年目以降は、クラスタ全体の年間880ユーロの価格でサブスクリプションモデルでアップデートが提供されます。
VMmanager Cloudが高可用性クラスタの展開にどのように使用されているかを確認しましょう。
FirstByte
FirstByteは2016年2月にクラウドホスティングを提供し始めました。最初は彼らのクラスタはOpenStackに基づいて構築されていましたが、このシステムの専門家が不足していること、そしてそのコストが彼らを代替ソリューションを探すように促しました。高可用性クラスタを構築するための新しいシステムは、以下の要件を満たす必要がありました:
- KVM仮想マシンを展開する能力。
- Cephとの統合。
- 既存のサービスを提供するための請求システムとの統合。
- 手頃なライセンスコスト。
- ソフトウェア開発者からのサポート。
VMmanager Cloudはすべての要件を満たしました。
FirstByteクラスタの特徴:
- データ転送はEthernet技術とCisco機器に基づいています。
- ルーティングはCisco ASR9001を使用して行われます。クラスタは約50000のIPv6アドレスを使用しています。
- 計算ノードとスイッチ間のリンク速度は10 Gbpsです。
- スイッチとストレージノード間のデータ転送速度は20 Gbpsで、各10 Gbpsの2つの結合チャネルがあります。
- ストレージノード間のレプリケーションのために、ストレージノードを持つラック間に別の20 Gbpsリンクが使用されます。
- すべてのストレージノードにはSASディスクとSSDがインストールされています。
- ストレージタイプはRBDです。
システムレイアウトは以下の通りです:
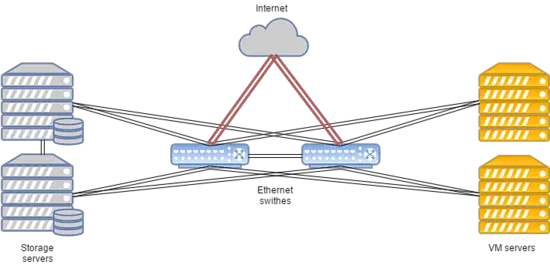
この構成は、人気のあるウェブサイト、ゲームサーバー、平均以上の負荷を持つデータベースのホスティングに適しています。
FirstVDS
FirstVDSは、2015年9月に開始された障害耐性クラスタのサービスを提供しています。
このクラスタには、以下の要因からVMmanager Cloudが選ばれました:
- ISPsystemコントロールパネルの使用に関する確かな経験。
- デフォルトでBILLmanagerとの統合。
- 高品質の技術サポート。
- Cephとの統合。
彼らのクラスタには以下の特徴があります:
- データ転送はInfinibandネットワークに基づいており、接続速度は56 Gbpsです。
- InfinibandネットワークはMellanox機器で構築されています。
- ストレージノードにはSSDドライブがあります。
- ストレージタイプはRBDです。
システムは以下のようにレイアウトできます:
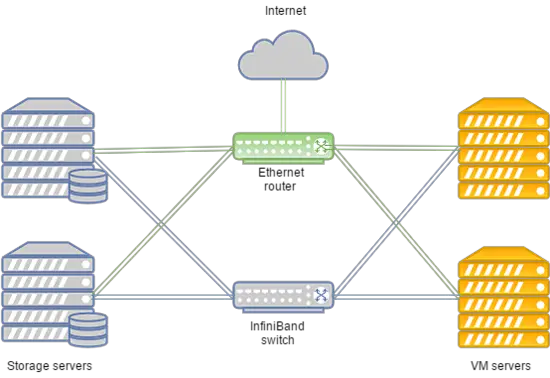
Infinibandネットワークが故障した場合、VMディスクストレージと計算サーバー間の接続は、Juniper機器上に展開されたEthernetネットワークを介して確立されます。新しい接続は自動的に設定されます。
ストレージとの通信速度が非常に高いため、このクラスタは超高トラフィックのウェブサイト、ビデオおよびコンテンツストリーミング、大規模データのホスティングに最適です。
結論
この記事の重要な発見をまとめましょう。
継続的可用性クラスタは、ダウンタイムの1秒が大きな損失をもたらす場合に必須です。バックアップノードに仮想マシンを展開する際に5分の停止が許可される場合、高可用性クラスタはハードウェアおよびソフトウェアコストを削減する良い選択肢となります。
障害耐性を達成する唯一の方法は冗長性であることを思い出すことも重要です。サーバー、データ通信機器、リンク、インターネットアクセスチャネル、電源を複製してください。複製できるものはすべて複製してください。このような対策により、システム全体のダウンタイムを引き起こす可能性のあるボトルネックや潜在的な障害点を排除することができます。上記の対策を講じることで、障害に強いクラスタを確保することができます。
高可用性モデルがあなたの要件に合っていて、VMmanager Cloudがそれを実現するための良いツールであると思われる場合は、インストールマニュアルと文書を参照してシステムについて詳しく学んでください。 あなたの運用が障害なく継続することを願っています!**
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。