Hadoopインストール · 2 min read · Dec 21, 2025
Ubuntu 22.04にApache Hadoopをインストールする方法

Apache Hadoopはビッグデータを処理および保存するためのオープンソースフレームワークです。今日の産業において、Hadoopはビッグデータの標準フレームワークとなっています。Hadoopは、数百台または数千台のクラスタ化されたコンピュータや専用サーバーで実行されるように設計されています。このことを考慮すると、Hadoopは構造化データと非構造化データの両方に対して、高ボリュームと複雑さを持つ大規模データセットを処理できます。
すべてのHadoopデプロイメントには、以下のコンポーネントが含まれています:
- Hadoop Common: 他のHadoopモジュールをサポートする共通ユーティリティ。
- Hadoop Distributed File System (HDFS): アプリケーションデータへの高スループットアクセスを提供する分散ファイルシステム。
- Hadoop YARN: ジョブスケジューリングとクラスタリソース管理のためのフレームワーク。
- Hadoop MapReduce: 大規模データセットの並列処理のためのYARNベースのシステム。
このチュートリアルでは、Ubuntu 22.04サーバーに最新のApache Hadoopをインストールします。Hadoopは単一ノードサーバーにインストールされ、Hadoopデプロイメントの擬似分散モードを作成します。
前提条件
このガイドを完了するには、以下の要件が必要です:
- Ubuntu 22.04サーバー - この例では、ホスト名が’hadoop’でIPアドレスが’192.168.5.100’のUbuntuサーバーを使用します。
- sudo/root管理者権限を持つ非rootユーザー。
Java OpenJDKのインストール
HadoopはApache Software Foundationの下にある大規模なプロジェクトで、主にJavaで書かれています。この執筆時点での最新バージョンのHadoopはv3.3.4で、Java v11と完全に互換性があります。
Java OpenJDK 11はUbuntuリポジトリにデフォルトで用意されており、APTを介してインストールします。
まず、以下のaptコマンドを実行して、Ubuntuシステムのパッケージリスト/リポジトリを更新およびリフレッシュします。
sudo apt update次に、以下のaptコマンドを使用してJava OpenJDK 11をインストールします。Ubuntu 22.04リポジトリでは、パッケージ’default-jdk’はJava OpenJDK v11を指します。
sudo apt install default-jdkプロンプトが表示されたら、yを入力して確認し、ENTERを押して続行します。Java OpenJDKのインストールが始まります。
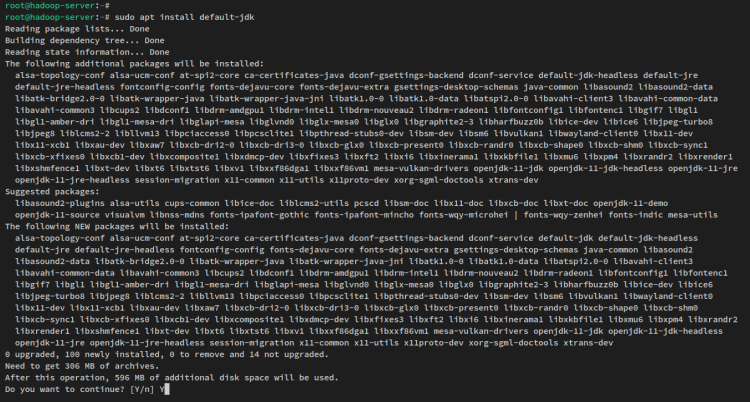
Javaがインストールされたら、以下のコマンドを実行してJavaのバージョンを確認します。UbuntuシステムにJava OpenJDK 11がインストールされているはずです。
java -versionJava OpenJDKがインストールされたので、次にHadoopプロセスとサービスを実行するために使用されるパスワードなしのSSH認証を持つ新しいユーザーを設定します。
ユーザーとパスワードなしのSSH認証の設定
Apache Hadoopは、システムでSSHサービスが実行されていることを要求します。これは、リモートサーバー上のリモートHadoopデーモンを管理するためにHadoopスクリプトによって使用されます。このステップでは、Hadoopプロセスとサービスを実行するために使用される新しいユーザーを作成し、次にパスワードなしのSSH認証を設定します。
システムにSSHがインストールされていない場合は、以下のaptコマンドを実行してSSHをインストールします。パッケージ’pdsh‘は、複数のホストでコマンドを並列モードで実行できるマルチスレッドリモートシェルクライアントです。
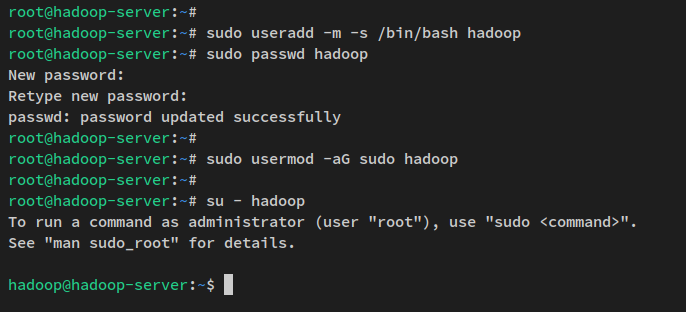
sudo apt install openssh-server openssh-client pdsh次に、以下のコマンドを実行して新しいユーザー’hadoop’を作成し、’hadoop’ユーザーのパスワードを設定します。
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoop‘hadoop’ユーザーの新しいパスワードを入力し、パスワードを繰り返します。
次に、以下のusermodコマンドを使用して’hadoop’ユーザーを’sudo‘グループに追加します。これにより、’hadoop’ユーザーが’sudo’コマンドを実行できるようになります。
sudo usermod -aG sudo hadoop‘hadoop’ユーザーが作成されたので、以下のコマンドを使用して’hadoop’ユーザーにログインします。
su - hadoopログインすると、プロンプトは次のようになります:「hadoop@hostname..」。
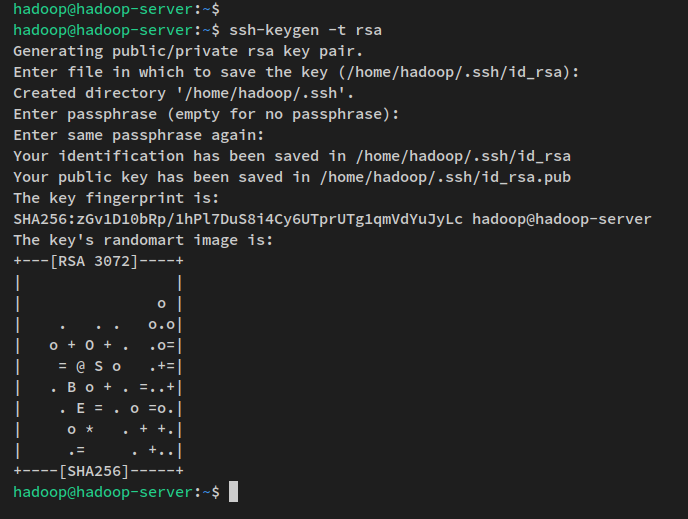
次に、以下のコマンドを実行してSSHの公開鍵と秘密鍵を生成します。鍵のパスワードを設定するように求められたら、ENTERを押してスキップします。
ssh-keygen -t rsaSSHキーは現在、~/.sshディレクトリに生成されました。id_rsa.pubはSSH公開鍵で、‘id_rsa’ファイルは秘密鍵です。
以下のコマンドを使用して生成されたSSHキーを確認できます。
ls ~/.ssh/次に、以下のコマンドを実行してSSH公開鍵’id_rsa.pub‘を’authorized_keys‘ファイルにコピーし、デフォルトの権限を600に変更します。
SSHでは、’authorized_keys‘ファイルはSSH公開鍵を保存する場所であり、複数の公開鍵を保存できます。’authorized_keys‘ファイルに保存された公開鍵を持ち、正しい秘密鍵を持つ人は、パスワードなしで’hadoop’ユーザーとしてサーバーに接続できます。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys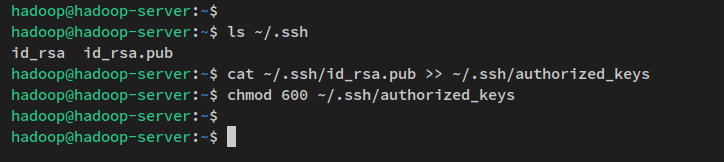
SSHのパスワードなしの設定が完了したので、以下のsshコマンドを使用してローカルマシンに接続して確認できます。
ssh localhostyesを入力して確認し、SSHフィンガープリントを追加すると、パスワード認証なしでサーバーに接続されます。
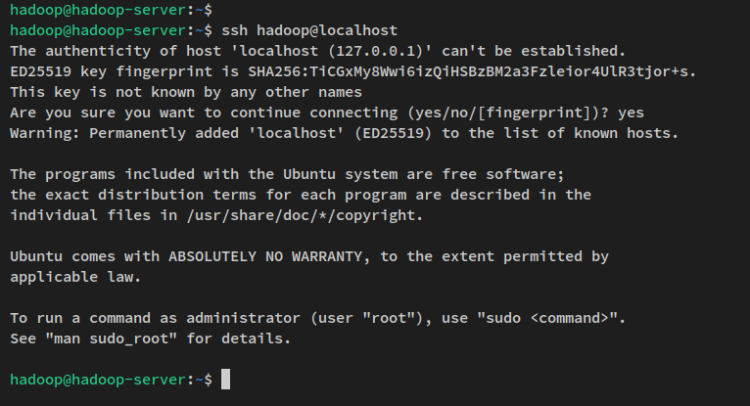
‘hadoop’ユーザーが作成され、パスワードなしのSSH認証が設定されたので、次にHadoopバイナリパッケージをダウンロードしてHadoopのインストールを行います。
Hadoopのダウンロード
新しいユーザーを作成し、パスワードなしのSSH認証を設定した後、Apache Hadoopのバイナリパッケージをダウンロードし、そのインストールディレクトリを設定できます。この例では、hadoop v3.3.4をダウンロードし、ターゲットインストールディレクトリは’/usr/local/hadoop‘ディレクトリになります。
以下のwgetコマンドを実行して、Apache Hadoopのバイナリパッケージを現在の作業ディレクトリにダウンロードします。現在の作業ディレクトリに’hadoop-3.3.4.tar.gz‘ファイルが作成されるはずです。
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz次に、以下のtarコマンドを使用してApache Hadoopパッケージ‘hadoop-3.3.4.tar.gz’を抽出します。その後、抽出したディレクトリを’/usr/local/hadoop‘に移動します。
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoop最後に、Hadoopインストールディレクトリ‘/usr/local/hadoop’の所有権をユーザー’hadoop‘とグループ’hadoop‘に変更します。
sudo chown -R hadoop:hadoop /usr/local/hadoop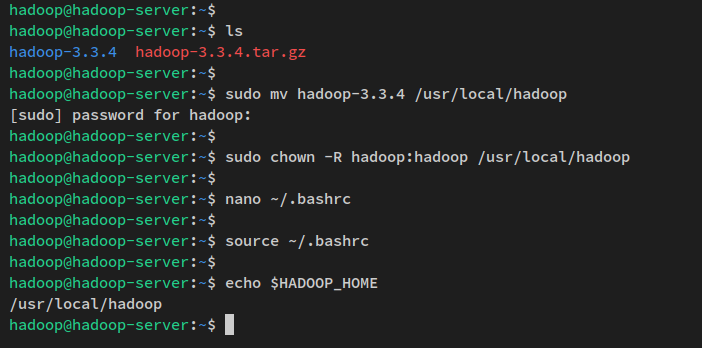
このステップでは、Apache Hadoopのバイナリパッケージをダウンロードし、Hadoopインストールディレクトリを設定しました。それを考慮して、Hadoopインストールの設定を開始できます。
Hadoop環境変数の設定
以下のnanoエディタコマンドを使用して設定ファイル’~/.bashrc‘を開きます。
nano ~/.bashrcファイルの最後に以下の行を追加してください。
# Hadoop環境変数
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"ファイルを保存し、終了したらエディタを閉じます。
次に、以下のコマンドを実行して’~/.bashrc‘ファイル内の新しい変更を適用します。
source ~/.bashrcコマンドが実行された後、新しい環境変数が適用されます。以下のコマンドを使用して各環境変数を確認できます。各環境変数の出力が得られるはずです。
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTS次に、JAVA_HOME環境変数を’hadoop-env.sh’スクリプトでも設定します。
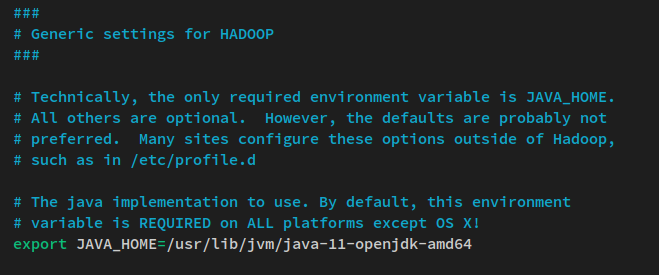
以下のnanoエディタコマンドを使用してファイル’hadoop-env.sh’を開きます。ファイル’hadoop-env.sh’は’ $HADOOP_HOME ‘ディレクトリにあり、Hadoopインストールディレクトリ‘/usr/local/hadoop‘を指します。
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shJAVA_HOME環境行のコメントを解除し、値をJava OpenJDKインストールディレクトリ’ /usr/lib/jvm/java-11-openjdk-amd64‘に変更します。
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64ファイルを保存し、終了したらエディタを閉じます。
環境変数の設定が完了したので、以下のコマンドを実行してシステム上のHadoopバージョンを確認します。システムにApache Hadoop 3.3.4がインストールされているはずです。
hadoop version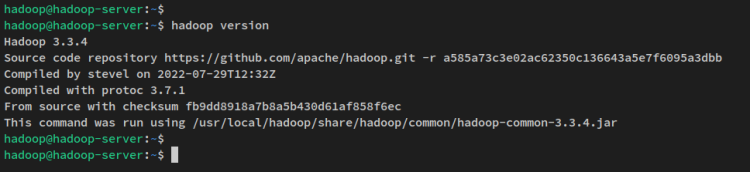
この時点で、Hadoopクラスタを設定して構成する準備が整いました。これは複数のモードでデプロイできます。
Apache Hadoopクラスタの設定:擬似分散モード
Hadoopでは、3つの異なるモードでクラスタを作成できます:
- ローカルモード(スタンドアロン) - デフォルトのHadoopインストールで、単一のJavaプロセスとして実行され、非分散モードです。これにより、Hadoopプロセスを簡単にデバッグできます。
- 擬似分散モード - これにより、単一のノード/サーバーでも分散モードでHadoopクラスタを実行できます。このモードでは、Hadoopプロセスは別々のJavaプロセスで実行されます。
- 完全分散モード - 複数または数千のノード/サーバーを持つ大規模なHadoopデプロイメント。生産環境でHadoopを実行したい場合は、完全分散モードでHadoopを使用する必要があります。
この例では、単一のUbuntuサーバーで擬似分散モードのApache Hadoopクラスタを設定します。そのために、いくつかのHadoop設定を変更します:
- core-site.xml - これはHadoopクラスタのNameNodeを定義するために使用されます。
- hdfs-site.xml - この設定はHadoopクラスタのDataNodeを定義するために使用されます。
- mapred-site.xml - HadoopクラスタのMapReduce設定。
- yarn-site.xml - HadoopクラスタのResourceManagerおよびNodeManager設定。
NameNodeとDataNodeの設定
まず、HadoopクラスタのNameNodeとDataNodeを設定します。
以下のnanoエディタを使用してファイル’ $HADOOP_HOME/etc/hadoop/core-site.xml‘を開きます。
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml以下の行をファイルに追加します。NameNodeのIPアドレスを変更するか、’0.0.0.0’に置き換えて、NameNodeがすべてのインターフェースとIPアドレスで実行されるようにします。
fs.defaultFS
hdfs://192.168.5.100:9000
ファイルを保存し、終了したらエディタを閉じます。
次に、以下のコマンドを実行して、HadoopクラスタのDataNodeに使用される新しいディレクトリを作成します。その後、DataNodeディレクトリの所有権を’hadoop‘ユーザーに変更します。
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsその後、以下のnanoエディタコマンドを使用してファイル‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’を開きます。
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml以下の設定をファイルに追加します。この例では、単一ノードでHadoopクラスタを設定するため、’dfs.replication’の値を’1’に変更する必要があります。また、DataNodeに使用されるディレクトリを指定する必要があります。
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
ファイルを保存し、終了したらエディタを閉じます。
NameNodeとDataNodeが設定されたので、以下のコマンドを実行してHadoopファイルシステムをフォーマットします。
hdfs namenode -format次のような出力が得られます:
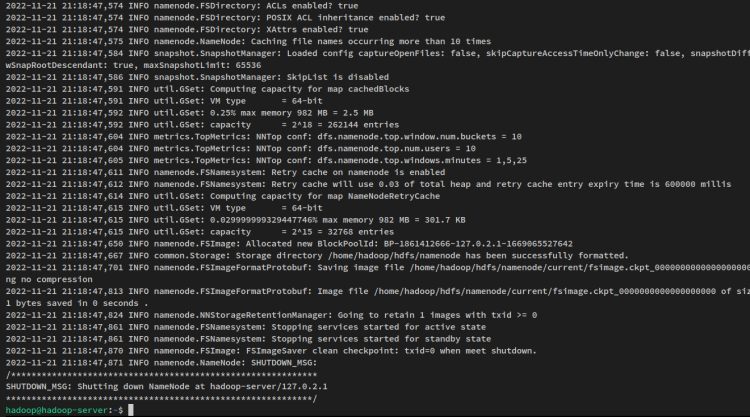
次に、以下のコマンドを使用してNameNodeとDataNodeを起動します。NameNodeは、‘core-site.xml’ファイルで設定したサーバーIPアドレスで実行されます。
start-dfs.sh次のような出力が得られます:
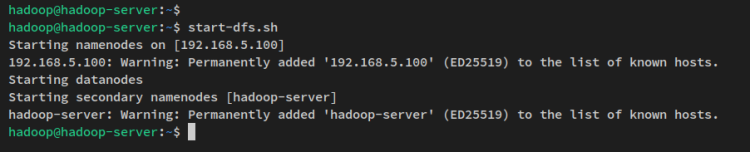
NameNodeとDataNodeが実行されているので、次にWebインターフェースを介して両方のプロセスを確認します。
Hadoop NameNodeのWebインターフェースはポート’9870‘で実行されています。したがって、Webブラウザを開いて、サーバーのIPアドレスの後にポート9870を追加してアクセスします(例:http://192.168.5.100:9870/)。
次のスクリーンショットのようなページが表示されます - NameNodeは現在アクティブです。
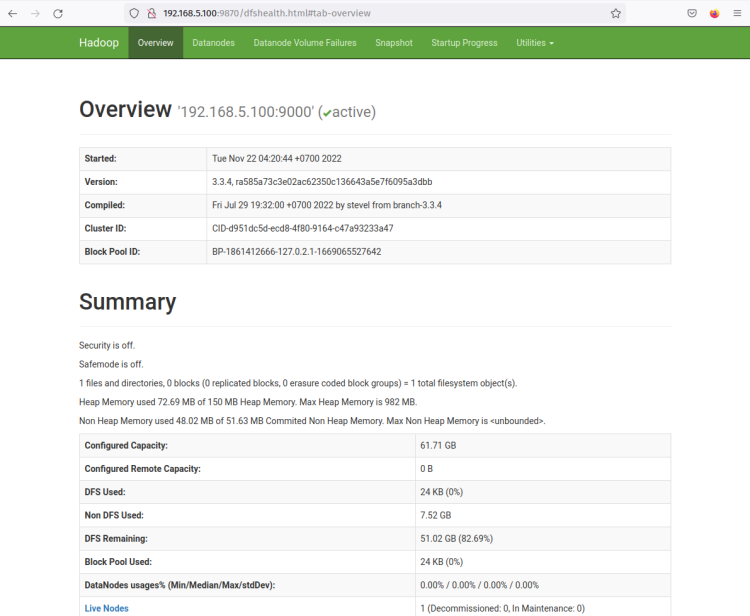
次に、’Datanodes’メニューをクリックすると、Hadoopクラスタで現在アクティブなDataNodeが表示されます。次のスクリーンショットは、Hadoopクラスタでポート’9864‘でDataNodeが実行されていることを確認しています。
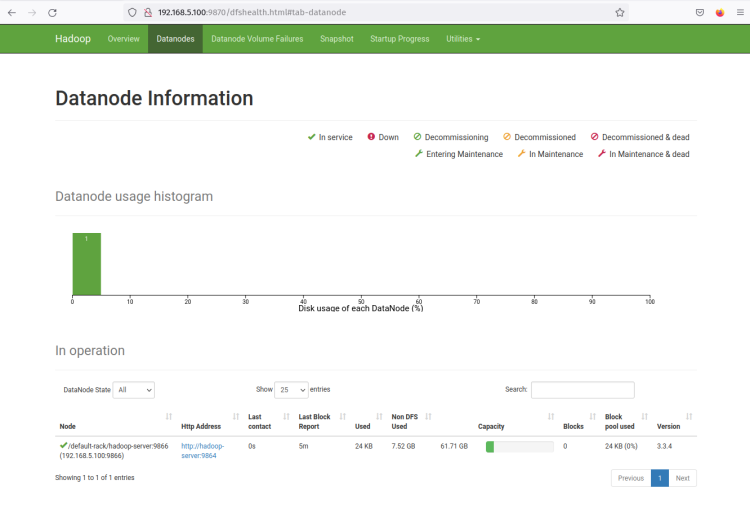
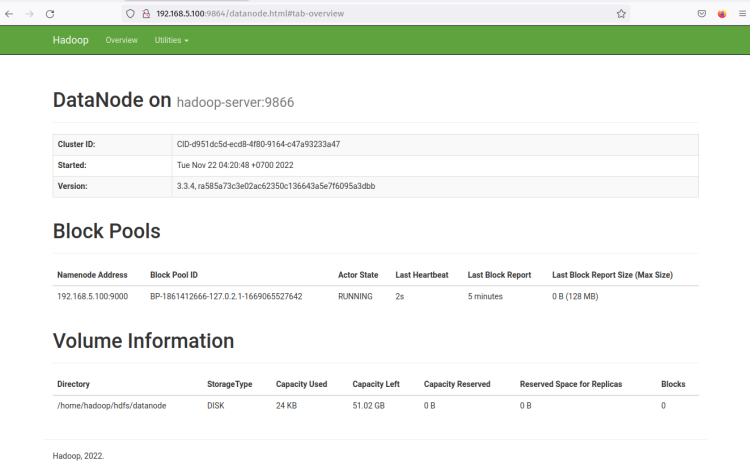
DataNodeの’Http Address‘をクリックすると、DataNodeに関する詳細情報が表示される新しいページが開きます。次のスクリーンショットは、DataNodeがボリュームディレクトリ’ /home/hadoop/hdfs/datanode‘で実行されていることを確認しています。
NameNodeとDataNodeが実行されているので、次にYarnマネージャー(Yet Another ResourceManagerとNodeManager)でMapReduceを設定して実行します。
Yarnマネージャー
擬似分散モードでYarnでMapReduceを実行するには、設定ファイルにいくつかの変更を加える必要があります。
以下のnanoエディタコマンドを使用してファイル‘$HADOOP_HOME/etc/hadoop/mapred-site.xml‘を開きます。
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml以下の行をファイルに追加します。mapreduce.framework.nameを’yarn’に変更してください。
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
ファイルを保存し、終了したらエディタを閉じます。
次に、以下のnanoエディタコマンドを使用してYarn設定’ $HADOOP_HOME/etc/hadoop/yarn-site.xml‘を開きます。
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlデフォルトの設定を以下の設定に変更します。
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
ファイルを保存し、終了したらエディタを閉じます。
以下のコマンドを実行してYarnデーモンを起動します。ResourceManagerとNodeManagerの両方が起動しているのが確認できるはずです。
start-yarn.shResourceManagerはデフォルトのポート8088で実行されるはずです。Webブラウザに戻り、サーバーのIPアドレスの後にResourceManagerポート’8088’を追加してアクセスします(例:http://192.168.5.100:8088/)。
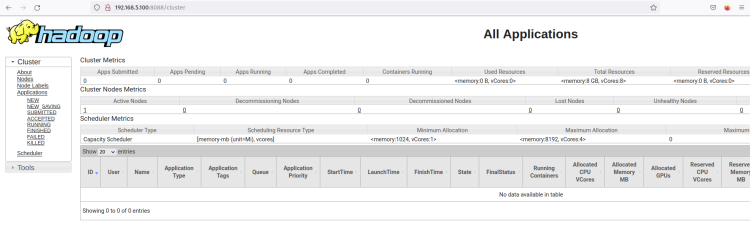
Hadoop ResourceManagerのWebインターフェースが表示されるはずです。ここから、Hadoopクラスタ内のすべての実行中のプロセスを監視できます。
ノードメニューをクリックすると、Hadoopクラスタで現在実行中のノードが表示されます。
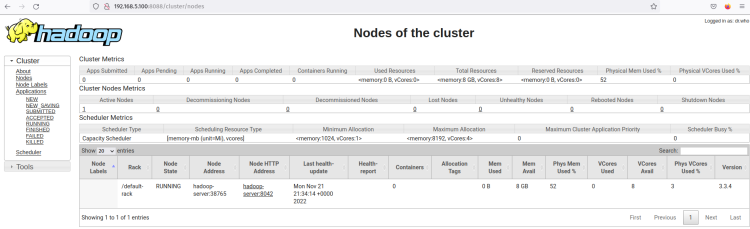
現在、Hadoopクラスタは擬似分散モードで実行されています。これは、各Hadoopプロセスが単一のノードUbuntuサーバー22.04上で単一のプロセスとして実行されていることを意味します。これにはNameNode、DataNode、MapReduce、Yarnが含まれます。
結論
このガイドでは、単一のマシンUbuntu 22.04サーバーにApache Hadoopをインストールしました。擬似分散モードが有効な状態でHadoopをインストールしました。これは、各Hadoopコンポーネントがシステム上で単一のJavaプロセスとして実行されていることを意味します。このガイドでは、Javaの設定、システム環境変数の設定、SSH公開鍵を介したパスワードなしのSSH認証の設定方法も学びました。
このタイプのHadoopデプロイメント、擬似分散モードは、テスト専用で推奨されます。中規模または大規模なデータセットを処理できる分散システムが必要な場合は、Hadoopをクラスターモードでデプロイすることができます。これは、より多くのコンピューティングシステムを必要とし、アプリケーションの高可用性を提供します。
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。