Grep · 1 min read · Sep 18, 2025
Grepを使用してファイル内でパターン検索を実行する方法
私たちのgrepコマンドに関する最初の記事では、このツールが提供するいくつかの機能について説明しました。これには、単語のみを検索する方法、2つの単語を検索する方法、一致した単語を含む行をカウントする方法などが含まれます。これらに加えて、このツールはさらに理解しやすく便利な機能を提供します。この記事では、それらのいくつかについて説明します。
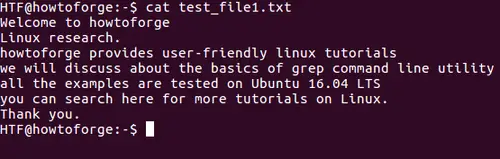
このチュートリアルで言及されているすべての例は、Ubuntu 14.04LTSでテストされています。また、すべてのgrep関連の例には、次のファイル(test_file1.txt)を使用します:
Grepによる大文字と小文字を区別しない検索
デフォルトでは、grepは大文字と小文字を区別します。つまり、例えば、’ABC’と’abc’は別々に扱われます。しかし、検索を大文字と小文字を区別しないようにしたい場合は、-iコマンドラインオプションを使用できます。
grep -i [検索する文字列] [ファイル名]例えば:
grep -i "linux" test_file1.txt注意:パターン(例えば、上記の例の’linux’)だけでなく、grepのマニュアルページによれば、-iオプションは入力ファイルの大文字と小文字の区別も無視することを保証します。以下はその抜粋です:
-i, --ignore-case
大文字と小文字の区別をPATTERNと入力ファイルの両方で無視します。(-iはPOSIXによって指定されています。)ただし、私たちは入力ファイルに関連する動作を再現することができませんでした。
Grepで一致した文字列を含む行の前後の特定の非一致行を表示
このツールを使用すると、一致した文字列を含む行の前後または周囲の指定された行数を表示することもできます。
一致した行の後に’N’行を印刷するには、-Aコマンドラインオプションを使用します。
$ grep -A N [検索する文字列] [ファイル名]例えば:
$ grep -A 2 "linux" test_file1.txt上記のコマンドの出力は以下の通りです。
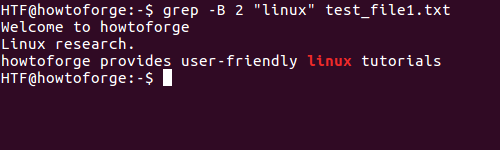
同様に、-Bコマンドラインオプションは、一致した行の前の行を表示するために使用されます。
$ grep -B N [検索する文字列] [ファイル名]例えば:
$ grep -B 2 "linux" test_file1.txt出力は以下の通りです:
最後に、一致した行の周囲の行を印刷するには、-Cコマンドラインオプションを使用します。
$ grep -C N [検索する文字列] [ファイル名]例えば:
$ grep -C 2 "linux" test_file1.txtキャプチャされた出力は以下の通りです:
Grepで一致した文字列のみを印刷
一致した文字列のみを標準出力に印刷することも許可されています(デフォルトで表示される完全な行ではなく)。この機能は、-oコマンドラインオプションを使用してアクセスできます。
$ grep -o [検索する文字列] [ファイル名]例えば、ファイル内で文字列”linux”を検索する必要がある場合(ただし、完全な行は印刷しない)、次のコマンドを使用します。
$ grep -o "linux" [ファイル名]また、や.のようなワイルドカード文字を使用して、複数の文字列をgrepすることもできます。例えば、”how”で始まり”linux”で終わる単語のグループをgrepしたい場合、次のコマンドを使用できます。
$ grep -o "how.*linux" [ファイル名]Grepでの位置を表示
grepコマンドは、一致した文字列が発生する行のバイトオフセットを表示することもできます。この機能は、-bコマンドラインオプションを使用してアクセスできます。しかし、このオプションをより良く使用するために、-oコマンドラインオプションと一緒に使用すると、一致した文字列の正確な位置が表示されます。
$ grep -o -b [検索する文字列] [ファイル名]例えば:
$ grep -o -b "for" test_file1.txt出力は以下の通りです:
結論
これらのオプションを毎日必要とするわけではありませんが、いつ役立つかわからないので、少なくとも知っておくべきです。grepは正規表現と一緒に使用するとさらに強力になりますが、そのトピックは別の日にしましょう。
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。