AIアート · 1 min read · Sep 12, 2025
あなたの顔でStable Diffusion AIをトレーニングしてDreamBoothを使用してアートを作成する方法
ゲスト投稿:タルナーブ・ダッタ。
2021年が言葉ベースのAI言語モデルの年であったなら、2022年はテキストから画像へのAIモデルに飛躍しました。現在、高品質な画像を生成できるテキストから画像へのAIモデルが多数存在します。Stable Diffusionは最も人気があり、よく知られたオプションの一つです。これは、迅速で安定したモデルで、一貫した結果を生成します。

画像生成のプロセスはまだいくらか神秘的ですが、Stable Diffusionが優れた結果を生み出すことは明らかです。これは、テキストから画像を生成したり、既存の画像を変更したりするために使用できます。利用可能なオプションとパラメータにより、最終的な画像に対して多くのカスタマイズと制御が可能です。
有名人や人気のある人物の画像を扱うのは比較的簡単ですが、純粋に自分の顔でAIを動かすのはそれほど簡単ではありません。論理的には、AIモデルに自分の画像を与えて、その魔法を発揮させるべきですが、具体的にどうすればそれができるのでしょうか?
この記事では、DreamBoothのテキスト反転を使用してStable Diffusionモデルをトレーニングし、自分の顔や他のオブジェクトのAI表現を構築し、驚くべき結果、精度、一貫性を持つ結果画像を生成する方法を示します。技術的に聞こえるかもしれませんが、初心者にもわかりやすくするよう努めます。
Stable Diffusionとは?
基本を押さえましょう。Stable Diffusionモデルは、大規模な画像セットでトレーニングされた最先端のテキストから画像への機械学習モデルです。トレーニングには約660,000ドルの費用がかかります。しかし、Stable Diffusionモデルは自然言語を使用してアートを生成するために使用できます。
ディープラーニングのテキストから画像へのAIモデルは、テキストを正確に画像に変換する能力からますます人気が高まっています。このモデルは無料で使用でき、Hugging Face SpacesやDreamStudioで見つけることができます。モデルの重みもダウンロードしてローカルで使用できます。
Stable Diffusionは、「拡散」と呼ばれるプロセスを使用して、テキストプロンプトに似た画像を生成します。
簡単に言うと、Stable Diffusionアルゴリズムはテキストの説明を受け取り、その説明に基づいて画像を生成します。生成された画像はテキストに似ていますが、正確なレプリカではありません。Stable Diffusionの代替としては、OpenAIのDall-EやGoogleのImagenモデルがあります。
関連情報:iPhoneおよびAndroid用の9つのベストAIアート生成アプリ
DreamBoothを使用して顔でStable Diffusion AIをトレーニングして画像を作成するガイド
今日は、私の顔を初期参照として使用して、オリジナルで新鮮なスタイルで一貫性が高く正確な画像を生成するためにStable Diffusionモデルをトレーニングする方法を示します。
そのために、Stable DiffusionをトレーニングするためにDreamBoothというGoogle Colabを使用します。
このGoogle Colabを起動する前に、特定のコンテンツ資産を準備する必要があります。
ステージ1:十分な空き容量のあるGoogle Drive
これには、少なくとも9GBの空き容量があるGoogle Driveアカウントが必要です。
無料のGoogle Driveアカウントには15GBの無料ストレージが付いており、このタスクには十分です。したがって、この目的のためだけに新しい(使い捨ての)Gmailアカウントを作成できます。
ステージ2:AIをトレーニングするための参照画像
次に、顔や任意のターゲットオブジェクトのポートレートを少なくとも12枚用意する必要があります。
- 撮影された画像では、顔の特徴が見えるようにし、適切に照明されていることを確認してください。特に顔に強い影を避けてください。
- さらに、被写体はカメラに向かっているか、両目とすべての顔の特徴がはっきりと見える横顔である必要があります。
- カメラは高品質な顔の特徴をキャプチャできるものでなければなりません。最良の選択肢はプロフェッショナルレベルのDSLRまたはミラーレスカメラです。優れた品質のスマートフォンカメラでも十分です。
- 構図はフレームの中心に配置し、少しの頭上スペースを持たせるべきです。
- 入力画像として、顔のクローズアップ写真を最低12枚、頭から腰上までをカバーするミッドショット写真を5枚、全身写真を約3枚用意する必要があります。
- この目的には、最低20枚の参照写真があれば十分です。
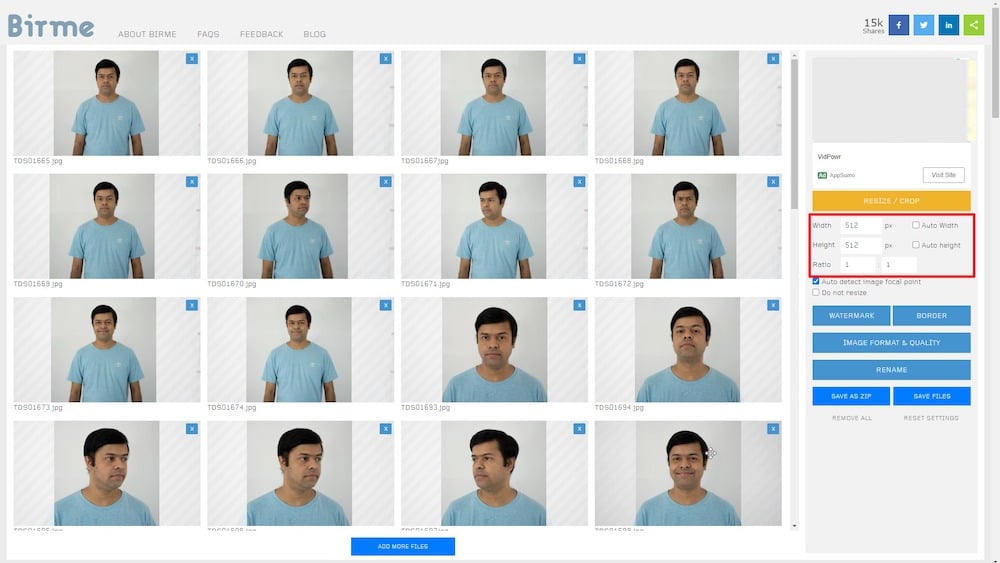
私の場合、約50枚の自撮りを撮影し、オンラインツールのBirmeを使用して512 x 512ピクセルにトリミングしました。この目的のために他の画像編集ツールを使用しても構いません。
最終的な出力画像は、ウェブ用に最適化され、品質を最小限に損なう形でファイルサイズが削減されている必要があることを忘れないでください。
ステージ3:Google Colab
Google Colabのランタイムを実行できるようになりました。
Google Colabプラットフォームには無料版と有料版があります。Dreamboothは無料版で実行できますが、Colab Pro(有料版)ではパフォーマンスが大幅に向上し、高速GPUの使用が優先され、タスクに少なくとも15GBのVRAMが割り当てられます。
数ドルを支払うことを気にしないのであれば、月に100の計算ユニットを含む10ドルのColab Proサブスクリプションは、このセッションには十分です。
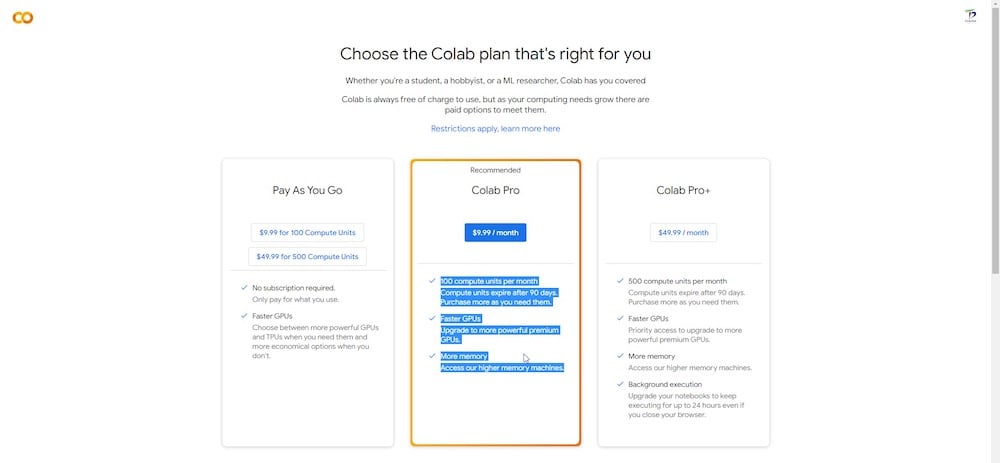
また、比較的強力で高速な追加のメモリRAMとGPUにアクセスできます。
これを繰り返しますが、Colabを実行するために技術的な専門家である必要はありません。事前のコーディング経験も必要ありません。
Google Colab(無料または有料版)にサインアップしたら、資格情報でサインインし、このリンクに移動してDreamBooth Stable Diffusionを開いてください。
Google Colabには、左側にクリック可能な再生ボタンがある「ランタイム」セクションやセルがあり、順番に配置されています。最初から再生を開始するには、再生ボタンを1つずつクリックしてください。各セグメントは実行する必要があるランタイムで構成されています。再生ボタンをクリックすると、対応するセクションがランタイムとして実行されます。しばらくすると、再生ボタンの左側に緑のチェックマークが表示され、ランタイムが正常に実行されたことを示します。
必ず、1回に1つのランタイムのみを手動で実行し、現在のランタイムが終了したら次の「ランタイム」セクションに進んでください。
上部メニューバーのランタイム部分には、すべてのランタイムを同時に実行するオプションがあります。ただし、これは推奨されません。

その下には「ランタイムの種類を変更」というオプションがあります。プロサブスクリプションに加入している場合は、実行のために「プレミアム」GPUと高RAMを選択して保存できます。
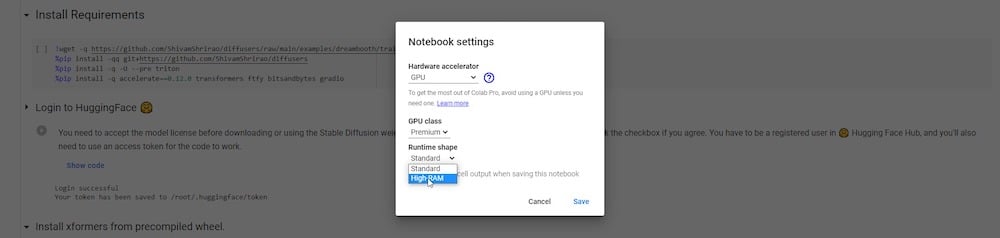
これでDreamBooth Colabを開始する準備が整いました。

DreamBoothでトレーニングされたAIモデルを成功裏に完了するための10ステップ
ステップ1:GPUとVRAMを決定する
最初のステップは、利用可能なGPUとVRAMの種類を決定することです。プロユーザーは、より安定した高速GPUと強化されたVRAMにアクセスできます。
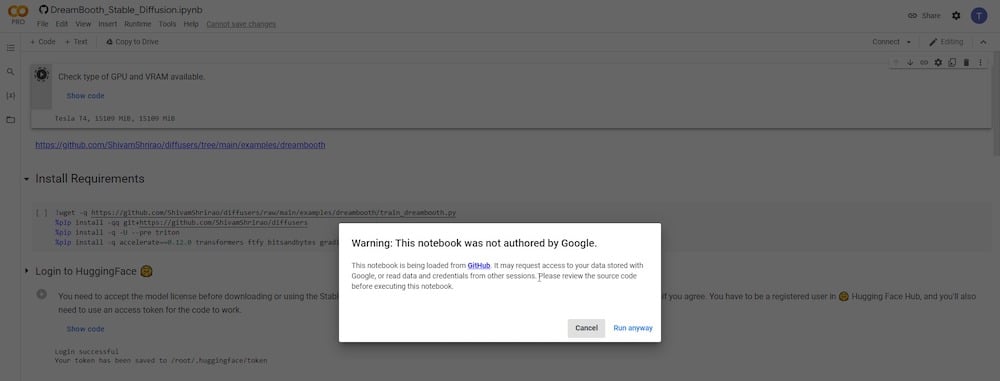
再生ボタンをクリックすると、開発者のソースウェブサイトであるGitHubにアクセスしているため、警告が表示されます。「とにかく実行」をクリックして続行するだけです。
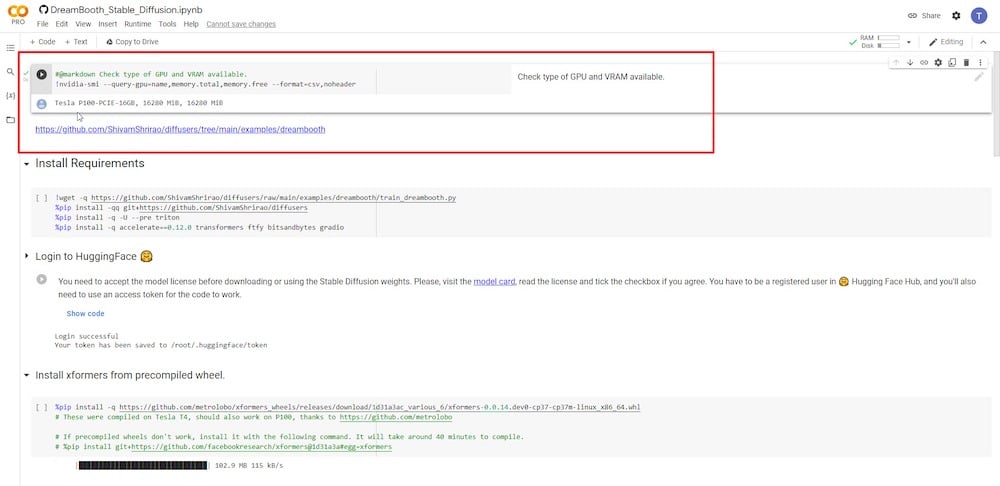
ステップ2:DreamBoothを実行する
次のステップでは、特定の要件と依存関係をインストールする必要があります。再生ボタンをクリックして実行させるだけです。
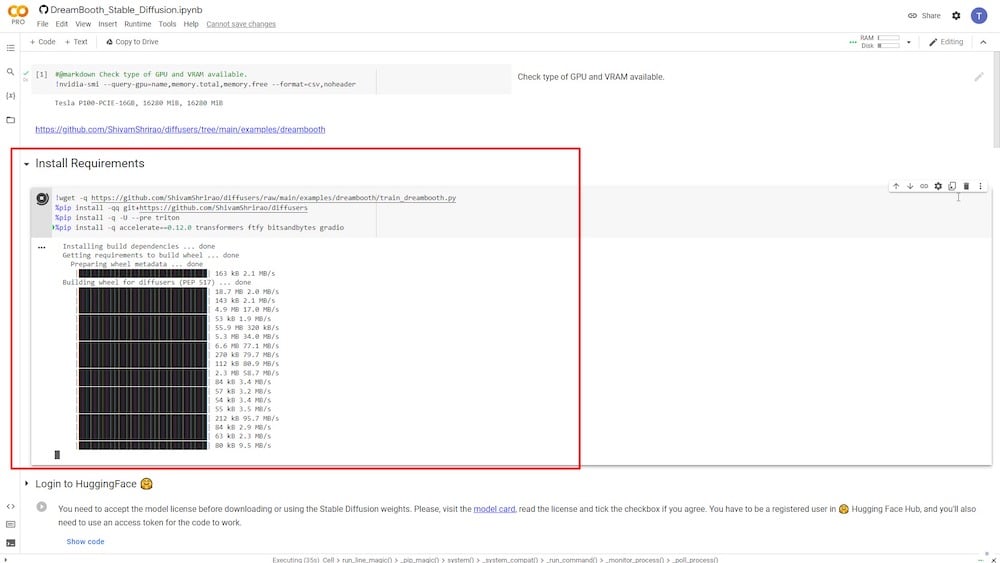
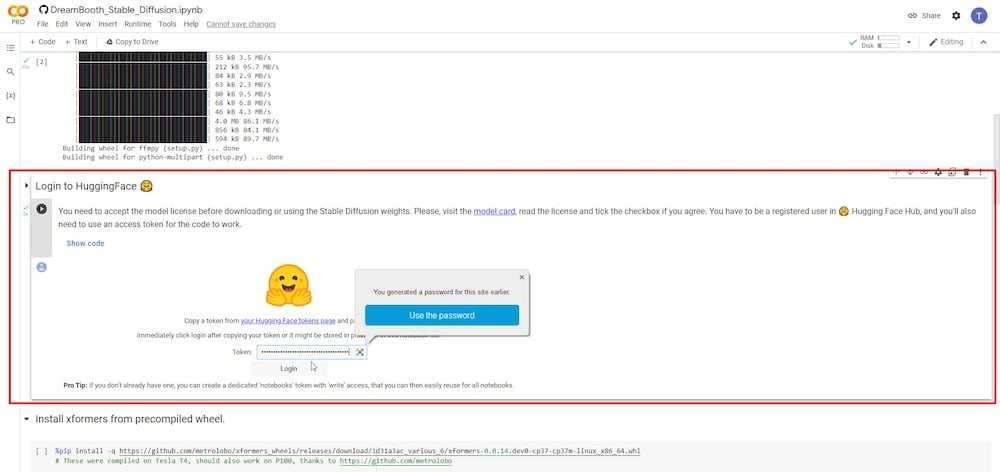
ステップ3:Hugging Faceにログインする
再生ボタンをクリックした後、次のステップではHugging Faceアカウントにログインする必要があります。まだアカウントを持っていない場合は、無料アカウントを作成できます。ログインしたら、右上の設定ページに移動します。
次に、「アクセストークン」セクションをクリックし、「新規作成」ボタンをクリックして新しい「アクセストークン」を生成し、希望の名前に変更します。
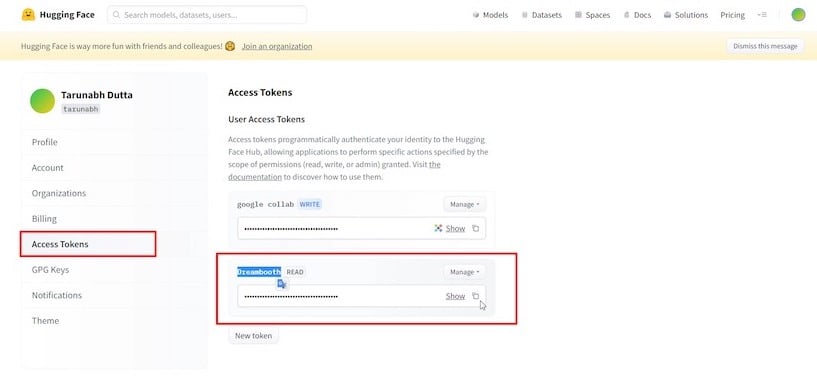
アクセストークンをコピーし、Colabタブに戻って指定されたフィールドに入力し、「ログイン」をクリックします。
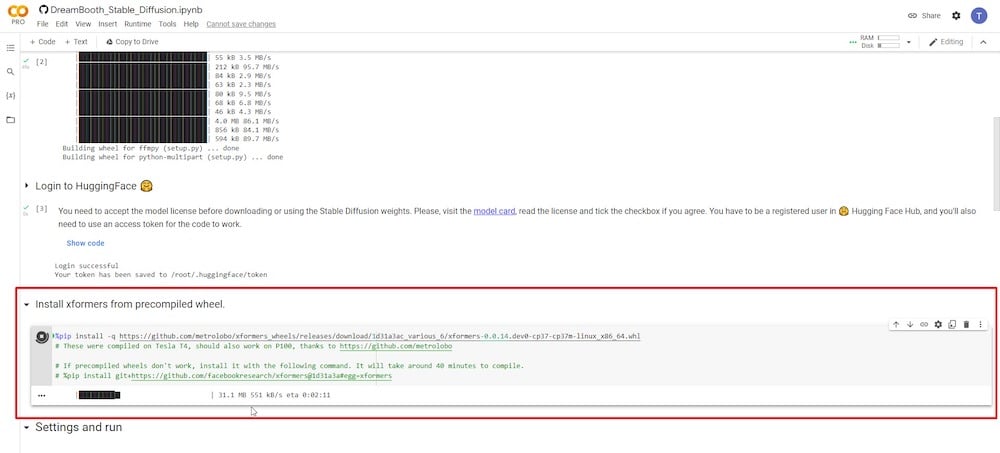
ステップ4:xformersをインストールする
このステップでは、再生ボタンを押すだけでxformersをインストールするためにランタイムをクリックできます。
ステップ5:Google Driveを接続する
再生ボタンをクリックすると、新しいポップアップウィンドウが表示され、Google Driveアカウントへのアクセス許可を求められます。許可を求められたら「許可」をクリックしてください。
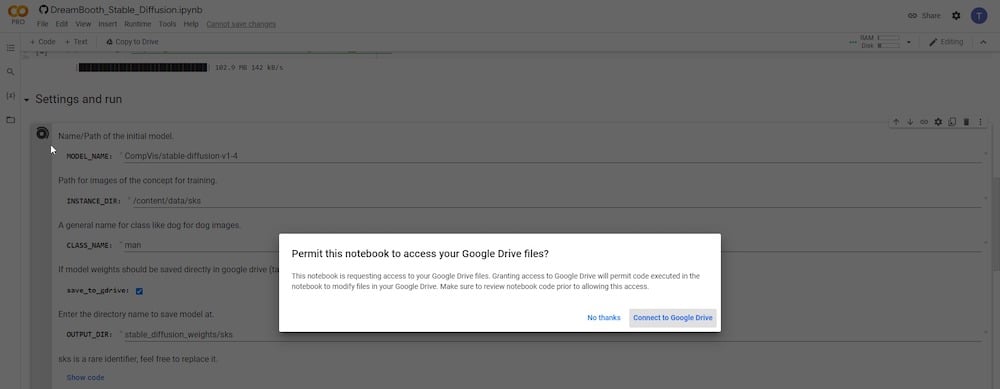
許可を与えた後、「Google Driveに保存」が選択されていることを確認する必要があります。また、「CLASS NAME」変数に新しい名前を設定する必要があります。人の参照画像を提出する場合は、「person」、「man」、「woman」と入力してください。参照画像が犬の場合は「dog」と入力します。そのほかのフィールドは変更しないでおいても構いません。代わりに、入力ディレクトリ「INSTANCE DIR」や出力ディレクトリ「OUTPUT DIR」の名前を変更することもできます。
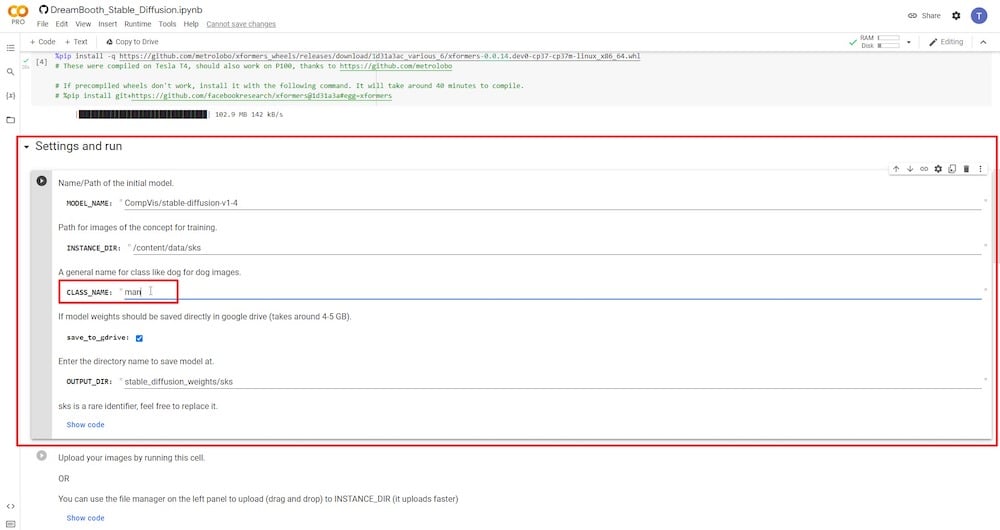
ステップ6:参照写真をアップロードする
前のステップで再生ボタンをクリックすると、すべての参照写真をアップロードして追加するオプションが表示されます。
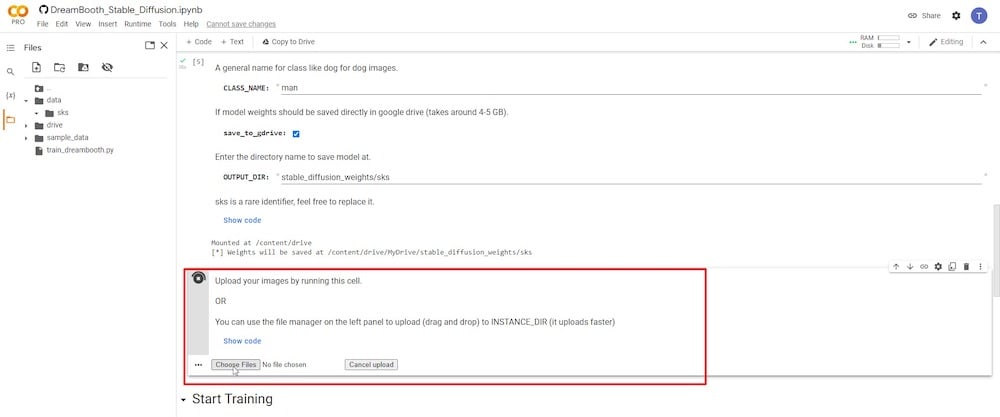
最低6枚、最大20枚の写真を推奨します。被写体がどのようにキャプチャされているかに基づいて、最適な参照写真を選択する方法については、上記の「ステージ2」を参照してください。
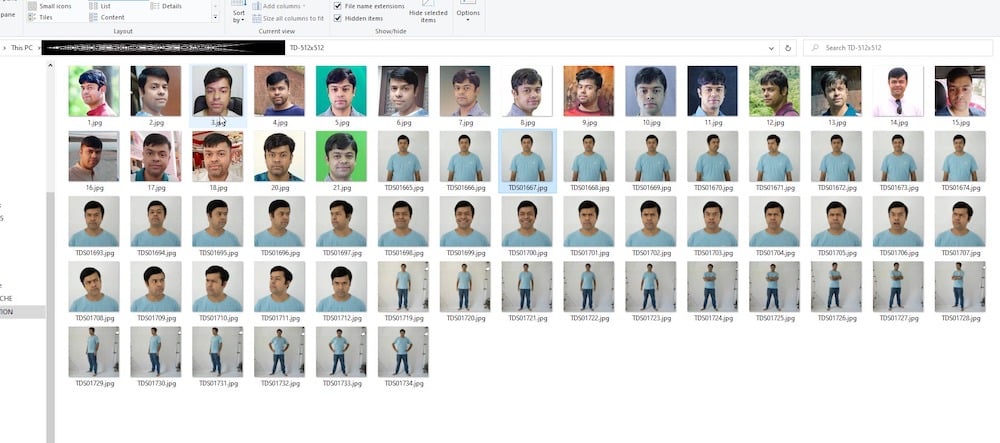
すべての画像がアップロードされると、左側の列でそれらを表示できます。フォルダーアイコンがあります。それをクリックすると、データが現在保存されているフォルダーやサブフォルダーを表示できます。
データディレクトリの下に、すべてのアップロードされた写真が保存されている入力ディレクトリを表示できます。私の場合、それは「sks」と呼ばれています(デフォルト名)。
さらに、このコンテンツはGoogle Driveではなく、Google Colabストレージに一時的に保存されていることに注意してください。
ステップ7:DreamBoothでAIモデルをトレーニングする
これは最も重要なステップです。アップロードしたすべての参照写真を使用して新しいAIモデルをトレーニングします。
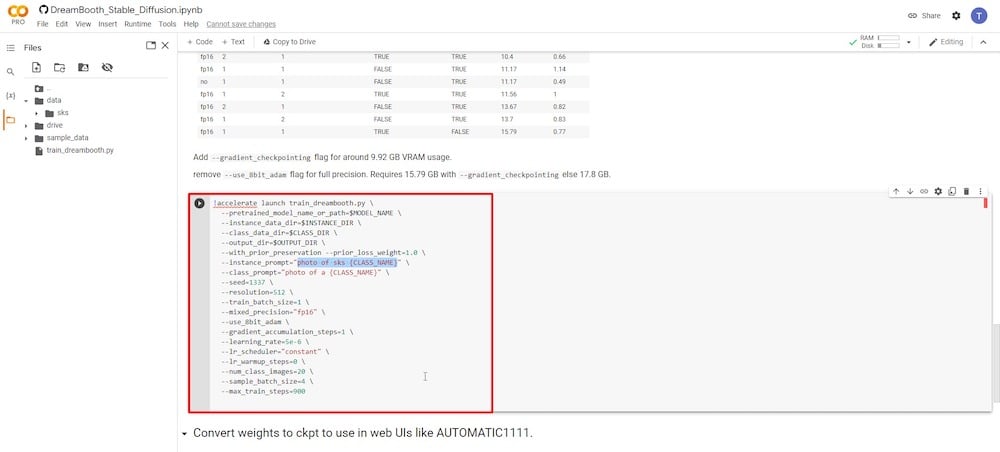
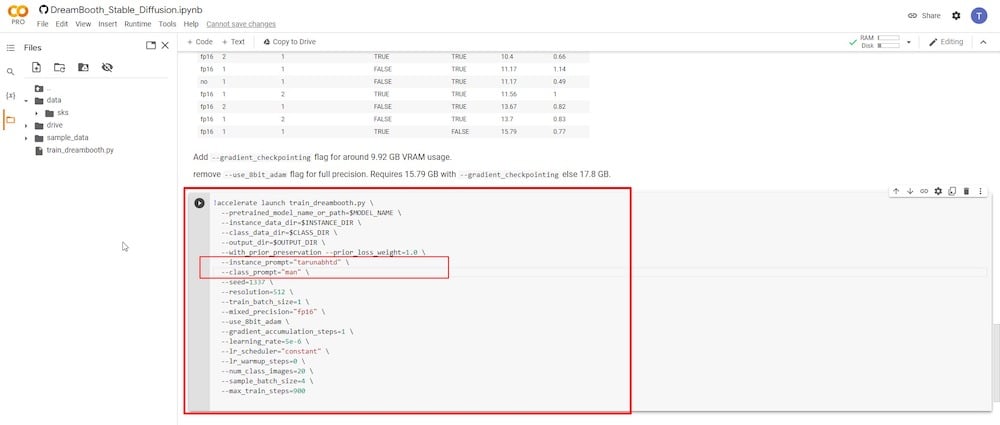
2つの入力フィールドにのみ集中する必要があります。最初のパラメータは「—instance prompt」です。ここでは、非常にユニークな名前を入力する必要があります。私の場合は、名前の後にイニシャルを付けます。全体のアイデアは、完全な名前をユニークで正確に保つことです。
2つ目の重要な入力フィールドは「—class prompt」パラメータです。これは、ステップ4で使用したものと一致するように名前を変更する必要があります。私の場合は「man」という用語を使用したので、このフィールドに再入力して以前のエントリを上書きします。
残りのフィールドはそのままにしておいても構いません。ユーザーが「—num class images」を12に、「—max train steps」を1000、2000、またはそれ以上に変更して実験しているのを見たことがあります。ただし、これらのフィールドを変更すると、Colabがメモリ不足になり、クラッシュする可能性があるため、最初の試行では編集しないことをお勧めします。十分な経験を積んだ後に、将来的にそれらを実験することができます。
このランタイムを再生ボタンをクリックして実行すると、Colabは必要な実行可能ファイルをダウンロードし、参照画像を使用してトレーニングできるようになります。
モデルのトレーニングには15分から1時間以上かかります。辛抱強く進捗を追跡し、ランタイムが完了するまで待ってください。Google Colabが長時間アイドル状態になると、リセットされる可能性があります。したがって、進捗を確認し、時折タブをクリックしてください。
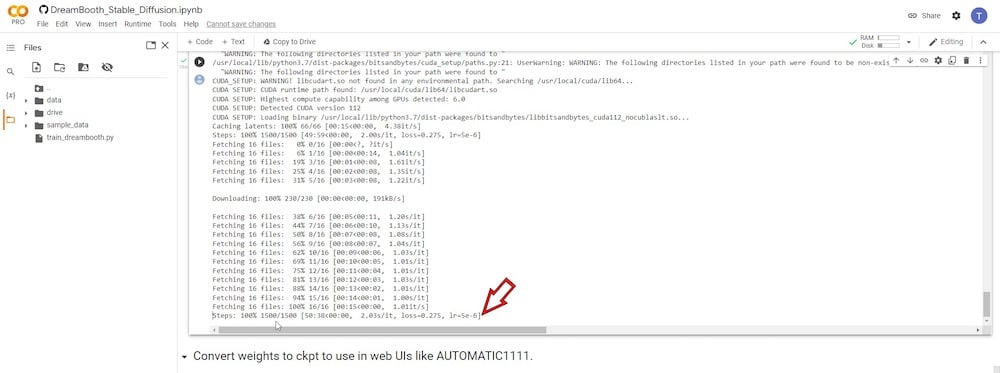
ステップ8:AIモデルをckpt形式に変換する
トレーニングが完了すると、トレーニングされたモデルをStable Diffusionと直接互換性のあるckpt形式のファイルに変換するオプションが表示されます。
変換は2つのランタイムフェーズで実行できます。最初は「ダウンロードスクリプト」、2つ目は「変換を実行」で、トレーニングされたモデルのダウンロードサイズを減らすオプションがあります。ただし、そうすると結果の画像品質が大幅に低下します。
したがって、元のサイズを維持するには、「fp16」オプションをチェックしないでください。
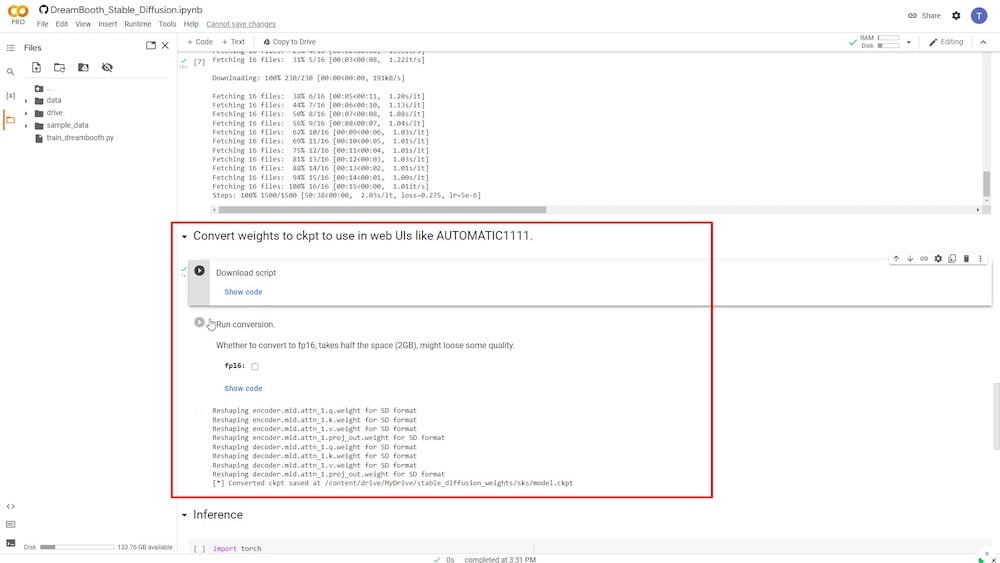
この特定のランタイムの最後に、「model.ckpt」というファイルが接続されたGoogle Driveに保存されます。
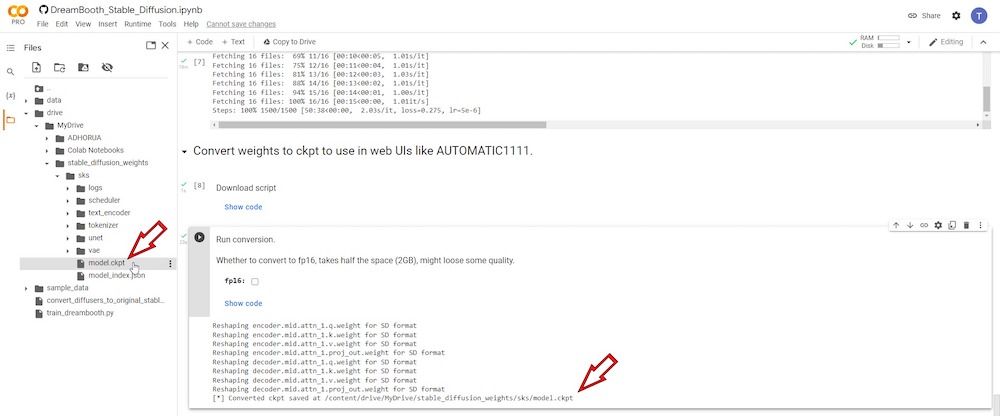
このファイルは将来の使用のために保存できます。DreamBooth Colabブラウザタブを閉じると、ランタイムはすぐに削除されます。後でDreamBoothのColabバージョンを再度開くと、最初からやり直す必要があります。
トレーニングされたモデルファイルをGoogle Driveに保存した場合、後でローカルにインストールされたStable Diffusion GUI、DreamBooth、または「model.ckpt」ファイルを読み込む必要があるStable Diffusion Colabノートブックで使用するために取得できます。また、後で使用するためにローカルハードディスクに保存することもできます。
ステップ9:テキストプロンプトの準備
「推論」カテゴリの次の2つのランタイムプロセスは、画像生成に使用されるテキストプロンプトのために新しくトレーニングされたモデルを準備します。各ランタイムの再生ボタンを押すだけで、数分で完了します。
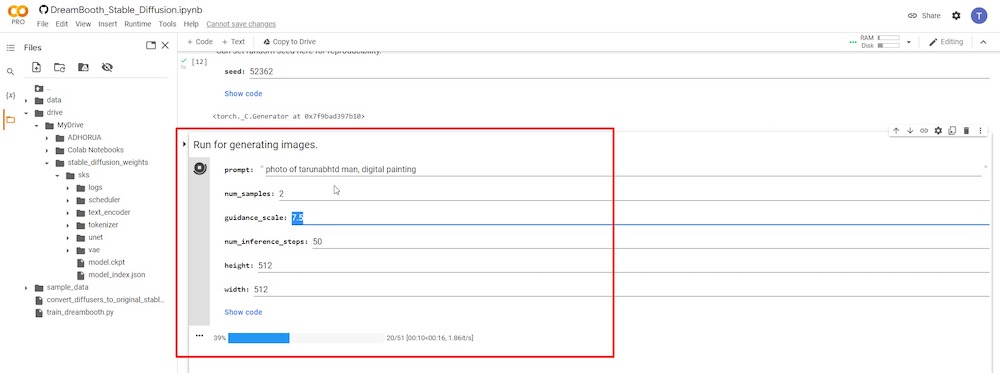
ステップ10:AI画像を生成する
これは最終ステップで、テキストプロンプトを入力するとAI画像が生成されます。
「instance_prompt」と「–class_prompt」をステップ6からテキストプロンプトの最初に正確に使用する必要があります。例えば、私の場合は「タルナーブ・ダッタの肖像、デジタルペインティング」と使用して、自分に似た新しいAI画像を生成します。
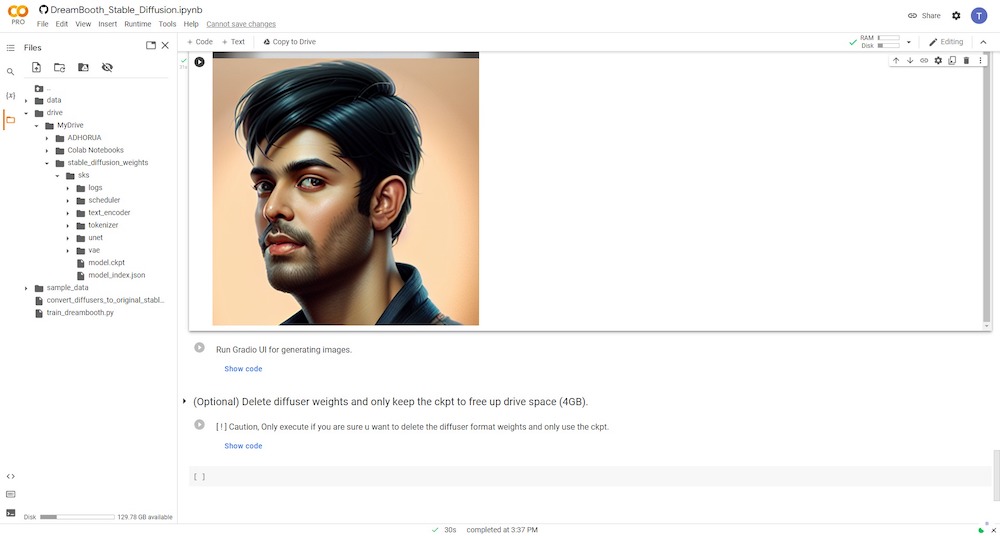
以下は、DreamBoothのトレーニングモデルで生成された画像結果のいくつかです。

プロンプトを試して最高の出力を得る
上記の手順を注意深く実行すれば、参照画像の顔の特徴に非常に似たAI画像を生成できるようになります。この方法では、テキスト反転のためのAI技術のアップグレード版を実行するためにオンラインのGoogle Colabプラットフォームが必要です。
テキストプロンプトのアイデアをより良くするために、以下のサイトをチェックできます。
- OpenArt AI
- Krea AI
- Lexica art
さまざまなアートスタイルやさまざまな組み合わせを使用して、より良く効果的なテキストプロンプトを作成する技術も学ぶ必要があります。良い出発点はStable DiffusionのSubRedditです。
RedditにはStable Diffusionに特化した大きなコミュニティがあります。また、Stable Diffusionの新しい道を探求し、共有し、議論しているFacebookグループやDiscordコミュニティも多数あります。
以下は、YouTubeで視聴できるいくつかのDreamBoothチュートリアル動画へのリンクも共有しています。
このガイドが役立つことを願っています。質問があれば、下にコメントしてください。お手伝いできるよう努めます。
著者:タルナーブ・ダッタは、独立したバナー「TD Film Studio」の下で、過去16年間にわたり、長編映画、短編映画、ミュージックビデオ、ドキュメンタリー、商業広告を含む45以上のプロジェクトを完成させた受賞歴のある映画製作者です。
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。