Linux, コマンド · 2 min read · Sep 12, 2025
Linuxシェルでファイル内の文字列を検索するためのgrepの使い方

LinuxのGREPコマンド - 概要
Linuxのgrepコマンドは、特定のパターンをファイルやテキストストリーム内で検索するための強力なテキスト検索ユーティリティです。これは「global regular expression print」の略で、単純なテキスト文字列やより複雑な正規表現による検索をサポートしています。このコマンドは、出力をフィルタリングおよび洗練するために他のコマンドと組み合わせて使用されることがよくあります。デフォルトでは、grepはパターンを含むすべての行を返しますが、大文字と小文字の区別、出現回数のカウント、ディレクトリ内の再帰的検索など、検索をカスタマイズするためのさまざまなオプションを提供します。これにより、システム管理者、開発者、およびUnixライクな環境で大規模なデータセットを扱うすべての人にとって不可欠なツールとなっています。
grepコマンドは、指定された単語/文字列に一致する行をテキストまたはファイル内で検索するために主に使用されます。デフォルトでは、grepは一致した行を表示し、1つ以上の正規表現に一致するテキスト行を検索するために使用され、一致した行のみを出力します。
前提条件
grepコマンドは、任意のLinuxディストリビューションの基本ユーティリティの一部であるため、AlmaLinux、CentOS、Debian、Linux Mint、Ubuntu、RHEL、およびRockyLinuxにデフォルトでプリインストールされています。
基本的なgrepコマンドの構文
基本的なgrepコマンドの構文は次のとおりです:
grep 'word' filename
grep 'word' file1 file2 file3
grep 'string1 string2' filename
cat otherfile | grep 'something'
command | grep 'something'
command option1 | grep 'data'
grep --color 'data' fileNameファイル内を検索するためのgrepコマンドの使い方
最初の例では、Linuxのpasswdファイルでユーザー「tom」を検索します。/etc/passwdファイルでユーザー「tom」を検索するには、次のコマンドを入力する必要があります:
grep tom /etc/passwd以下はサンプル出力です:
tom:x:1000:1000:tom,,,:/home/tom:/bin/bashgrepに単語の大文字と小文字を無視するよう指示するオプションがあります。つまり、-iオプションを使用してabc、Abc、ABC、およびすべての可能な組み合わせに一致させることができます。以下のように示します:
grep -i "tom" /etc/passwdgrepの再帰的使用
ディレクトリ階層内に多数のテキストファイルがある場合、たとえば、/etc/apache2/内のApache設定ファイルで、特定のテキストが定義されているファイルを見つけたい場合は、grepコマンドの-rオプションを使用して再帰的検索を行います。これにより、/etc/apache2/ディレクトリおよびそのすべてのサブディレクトリ内の文字列「197.167.2.9」を検索する再帰的検索操作が実行されます(以下のように):
grep -r "mydomain.com" /etc/apache2/また、次のコマンドを使用することもできます:
grep -R "mydomain.com" /etc/apache2/以下は、Nginxサーバーでの同様の検索のサンプル出力です:
grep -r "mydomain.com" /etc/nginx/
/etc/nginx/sites-available/mydomain.com.vhost: if ($http_host != "www.mydomain.com") {ここでは、mydomain.comの結果が、見つかったファイル名(たとえば、/etc/nginx/sites-available/mydomain.com.vhost)の前に表示される独自の行で表示されます。出力データにファイル名を含めることは、-hオプションを使用することで簡単に抑制できます(以下に説明):grep -h -R “mydomain.com” /etc/nginx/。以下はサンプル出力です:
grep -r "mydomain.com" /etc/nginx/
if ($http_host != "www.mydomain.com") {grepを使用して単語のみを検索する
abcを検索している場合、grepはkbcabc、abc123、aarfbc35など、単語の境界を無視してさまざまなものに一致します。grepコマンドに、完全な単語(abcにのみ一致するもの)を含む行のみを選択させることができます。以下のように示します:
grep -w "abc" file.txt例:
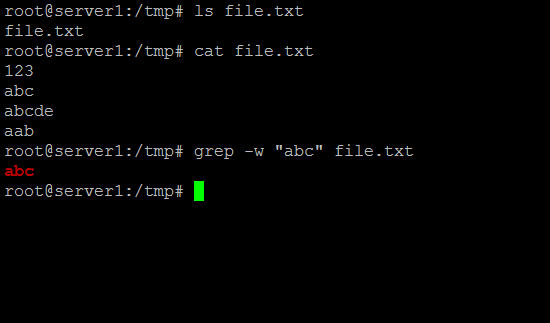
grepを使用して2つの異なる単語を検索する
2つの異なる単語を検索するには、以下のようにegrepコマンドを使用する必要があります:
egrep -w 'word1|word2' /path/to/file一致した単語の行数をカウントする
grepコマンドは、-c(カウント)オプションを使用して、各ファイルに対して特定のパターンが一致した回数を報告する機能があります(以下のように):
grep -c 'word' /path/to/fileさらに、ユーザーは’-n’オプションを使用して、出力の各行の前に、取得元のテキストファイルの行番号を付加することができます(以下のように):
grep -n 'root' /etc/passwd以下はサンプル出力です:
1:root:x:0:0:root:/root:/bin/bashgrepの反転一致
ユーザーは、-vオプションを使用して一致を反転させることができ、指定された単語を含まない行のみを一致させることができます。たとえば、次のコマンドを使用して、単語parを含まないすべての行を表示します:
grep -v par /path/to/file一致するファイルの名前のみをリストする方法
特定の単語が言及されているファイル名をリストするには、-lオプションを使用する必要があります。たとえば、単語’primary’を使用して、次のコマンドを実行します:
grep -l 'primary' *.c最後に、grepに特定の色で出力を表示させるオプションがあります。次のコマンドを使用します:
grep --color root /etc/passwd以下はサンプル出力です:
grepコマンドで複数の検索パターンを処理する方法
特定のファイル(またはファイルセット)内で複数のパターンを検索したい場合があります。そのようなシナリオでは、grepが提供する’ -e‘コマンドラインオプションを使用する必要があります。
たとえば、現在の作業ディレクトリ内のすべてのテキストファイルで「how」、「to」、および「forge」という単語を検索したい場合、次のように実行できます:
grep -e how -e to -e forge *.txt以下はコマンドの実行例です:
‘ -e‘コマンドラインオプションは、パターンがハイフン(-)で始まる場合にも役立ちます。たとえば、’-how’を検索したい場合、次のコマンドは役に立ちません:
grep -how *.txt‘-e’コマンドラインオプションを使用すると、コマンドはこの場合に何を検索しているのかを理解します:
grep -e -how *.txt以下は両方のコマンドの実行例です:
grepの出力を特定の行数に制限する方法
grepの出力を特定の行数に制限したい場合、’ -m‘コマンドラインオプションを使用できます。たとえば、testfile1.txtで「how」という単語を検索したいが、検索パターンを含む行が3行見つかった後にgrepが検索を停止する必要がある場合、次のコマンドを実行できます:
grep "how" -m3 testfile1.txt以下はコマンドの実行例です:
次に、コマンドのmanページには次のように記載されています:
入力が通常のファイルからの標準入力であり、一致する行がNUM出力される場合、grepは標準入力が最後の一致行の直後に位置することを保証します。これは、呼び出しプロセスが検索を再開できるようにします。したがって、たとえば、ループがあるbashスクリプトがあり、ループの各反復で1つの一致を取得したい場合、’grep -m1’を使用すると必要なことができます。
grepがファイルからパターンを取得するようにする方法
grepコマンドにファイルからパターンを取得させることもできます。このツールの-fコマンドラインオプションを使用すると、これが可能です。
たとえば、現在のディレクトリ内のすべての.txtファイルで「how」と「to」という単語を検索したいが、これらの入力文字列を「input」という名前のファイルを通じて供給したい場合、次のように実行できます:
grep -f input *.txt以下はコマンドの実行例です:
grepが検索パターンと完全に一致する行のみを表示するようにする方法
これまでのところ、デフォルトではgrepは検索パターンを含む行を一致させて表示することを見てきました。しかし、grepが検索パターンと完全に一致する行のみを表示するようにする必要がある場合、’-x’コマンドラインオプションを使用してこれを実行できます。
たとえば、testfile1.txtファイルに次の行が含まれているとします:
そして、検索したいパターンは「how are you?」です。grepがこのパターンと完全に一致する行のみを表示するようにするには、次のように使用します:
grep -x "how are you?" *.txt以下はコマンドの実行例です:
grepが出力に何も表示しないように強制する方法
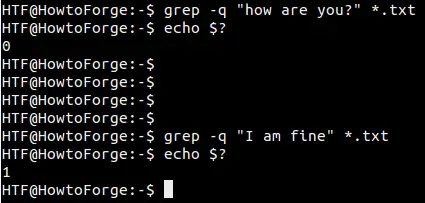
grepコマンドが出力に何も生成しない必要がある場合があります。代わりに、コマンドの終了ステータスに基づいて、一致が見つかったかどうかを知りたいだけです。これは-qコマンドラインオプションを使用して実現できます。
-qオプションは出力をミュートしますが、ツールの終了ステータスは’echo $?’コマンドで確認できます。grepの場合、コマンドは成功した場合(つまり、一致が見つかった場合)に’0’ステータスで終了し、一致が見つからなかった場合は’1’ステータスで終了します。
以下のスクリーンショットは、成功したシナリオと失敗したシナリオの両方を示しています:
grepが検索パターンを含まないファイルの名前を表示するようにする方法
デフォルトでは、grepコマンドは検索パターンを含むファイルの名前(および一致した行)を表示します。これは非常に論理的であり、このツールに期待されることです。しかし、検索パターンを含まないファイルの名前を取得する必要がある場合もあります。
これもgrepで可能です。-Lオプションを使用すると、これができます。たとえば、現在のディレクトリ内の「how」という単語を含まないすべてのテキストファイルを見つけるには、次のコマンドを実行できます:
grep -L "how" *.txt以下はコマンドの実行例です:
grepによって生成されるエラーメッセージを抑制する方法
grepが出力に表示するエラーメッセージをミュートするように強制することができます。これは-sコマンドラインオプションを使用して行うことができます。たとえば、grepが遭遇するディレクトリに関連するエラー/警告を生成する次のシナリオを考えてみてください:
このようなシナリオでは、-sコマンドラインオプションが役立ちます。以下を参照してください。
そのため、エラー/警告がミュートされたことがわかります。
grepを再帰的にディレクトリを検索するようにする方法
前のポイントで使用した例から明らかなように、grepコマンドはデフォルトでは再帰的検索を行いません。grep検索を再帰的にするには、-dコマンドラインオプションを使用し、その値に’recurse’を渡します。
grep -d recurse "how" *注1 :前のポイントで説明したディレクトリ関連のエラー/警告メッセージも、-dオプションを使用してミュートできます。行う必要があるのは、その値に’skip’を渡すことだけです。
注2 :再帰検索からパターンDIRに一致するディレクトリを除外するには、’–exclude-dir=[DIR]’オプションを使用します。
grepがNULL文字でファイル名を終了させるようにする方法
すでに説明したように、grepの-lコマンドラインオプションは、出力にファイル名のみを表示したい場合に使用されます。たとえば:
上記の出力の各名前は改行文字で区切られています/終了しています。これを確認する方法は次のとおりです:
出力をファイルにリダイレクトし、その後ファイルの内容を印刷します:
そのため、catコマンドの出力はファイル名の間に改行文字が存在することを確認します。
ただし、ファイル名に改行文字が含まれている場合もあることはご存知かもしれません。したがって、改行を含むファイル名を扱う場合、grepの出力を操作することが難しくなります(特にスクリプトを通じて出力にアクセスする場合)。
区切り/終了文字が改行でない方が良いでしょう。さて、grepはファイル名の後に改行ではなくNULL文字が続くことを保証するコマンドラインオプション-Zを提供していることを知って嬉しいです。
したがって、私たちの場合、コマンドは次のようになります:
grep -lZ "how" *.txt以下はNULL文字の存在を確認した方法です:
以下は知っておくべき関連するコマンドラインオプションです:
-z, --null-data
入力を、各行がゼロバイト(ASCII NUL文字)で終了する行のセットとして扱います。改行の代わりに。-Zまたは--nullオプションのように、このオプションはsort -zのようなコマンドと組み合わせて任意のファイル名を処理するために使用できます。GREPを使用してログファイル内のエラーを見つける方法
Grepは、サービスのデバッグエラーに関してLinux管理者のスイスアーミーナイフです。ほとんどのLinuxサービスには、エラーを報告するログファイルがあります。これらのログファイルは巨大になる可能性があり、grepは接続システムのIPアドレス、エラーストリング、または影響を受けたメールユーザーのメールアドレスを検索するための多用途で高速なコマンドです。
例:
特定のメールアドレスに関連する接続を検索します。ここで、’[email protected]’はサーバーのmail.logファイルにあります。
grep [email protected] /var/log/mail.log結果:
Aug 22 09:45:10 mail dovecot: pop3-login: Login: user=<[email protected]>, method=PLAIN, rip=192.168.0.112, lip=78.46.229.46, mpid=17596, TLS, session=<3uoa5ffQovld3Uep>
Aug 22 09:45:10 mail dovecot: pop3([email protected])<17596><3uoa5ffQovld3Uep>: Disconnected: Logged out top=0/0, retr=1/6647, del=1/1, size=6630
Aug 22 09:45:10 mail dovecot: pop3-login: Login: user=<[email protected]>, method=PLAIN, rip=192.168.0.112, lip=78.46.229.46, mpid=17673, TLS, session=
Aug 22 09:45:10 mail dovecot: pop3([email protected])<17673>: Disconnected: Logged out top=0/0, retr=0/0, del=0/0, size=0
Aug 22 09:45:10 mail dovecot: pop3-login: Login: user=<[email protected]>, method=PLAIN, rip=192.168.0.112, lip=78.46.229.46, mpid=17868, TLS, session=
Aug 22 09:45:10 mail dovecot: pop3([email protected])<17868>: Disconnected: Logged out top=0/0, retr=0/0, del=0/0, size=0
Aug 22 09:45:10 mail dovecot: pop3-login: Login: user=<[email protected]>, method=PLAIN, rip=192.168.0.112, lip=78.46.229.46, mpid=17964, TLS, session=
Aug 22 09:45:10 mail dovecot: pop3([email protected])<17964>: Disconnected: Logged out top=0/0, retr=0/0, del=0/0, size=0
Aug 22 09:45:10 mail postfix/smtpd[6932]: NOQUEUE: reject: RCPT from unknown[1.2.3.4]: 504 5.5.2 <1.2.3.4>: Helo command rejected: need fully-qualified hostname; from=<[email protected]> to=<[email protected]> proto=ESMTP helo=<1.2.3.4> このメールアドレスに対する接続を監視するために、tailとgrepコマンドを次のように組み合わせます:
tail -f /var/log/mail.log | grep [email protected]監視機能を終了するには、[strg] + cキーを押します。
さらなるGREPコマンドの例
このLinuxコマンドの使用に関するさらに多くの例は、私たちの2番目のGREPコマンドチュートリアルで見つけることができます。
- grepを使用してファイル内でパターン検索を行う方法
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。