Ubuntu, Opsview · 1 min read · Oct 18, 2025
Ubuntu LandscapeとOpsview Enterpriseの統合
Ubuntu LandscapeとOpsview Enterpriseの統合
最近、私たちはMark Shuttleworthによる今年のOpenstack基調講演で概説されたUbuntuツールセットを見てきました。特に興味深かったのは、Ubuntu Landscapeです。これは、単一のコンソールから1000台のUbuntuサーバーのパッチ適用と管理を可能にするシステムおよびサーバー管理ツールです。
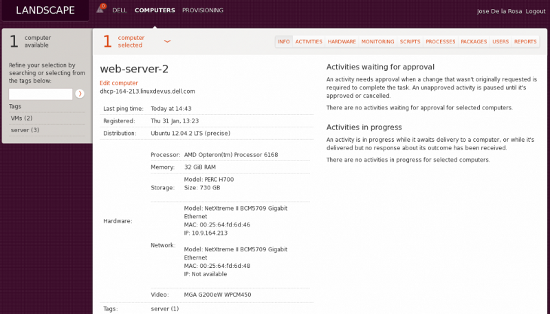
Landscapeの美しさは、1000台のUbuntuサーバーがある場合、単一のビューからソフトウェアを更新し、パッチを適用できることです。各サーバーをクリックしてハードウェアおよびソフトウェアのインベントリを取得したり、CPUを使用しているプロセスに関するレポートを確認したりすることも、すべて単一のツールから行えます。
Opsviewの観点から興味深い点は、デバイスごとに「監視」タブが含まれていることです。このタブは、以下のようにリソース使用量、ネットワークスループットなどの基本的な監視情報のみを表示するという点で初歩的です。
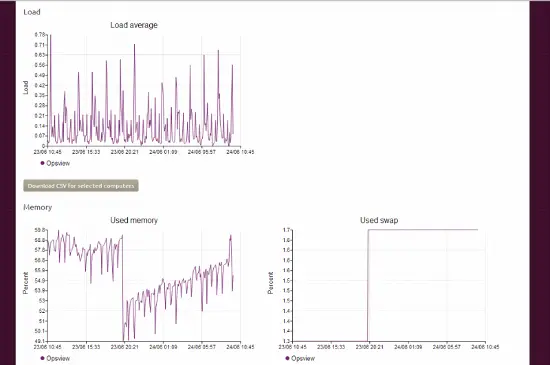
これは、おそらくUbuntuサーバー上で実行されているLandscapeクライアントによって取得され、通常の「負荷」などの出力が解析され、sedされているものです。この詳細はかなり基本的なものであるため、多くの人がOpsviewに代わってこのツールを単独で使用することは考えにくいですが、Landscapeダッシュボードにいる間に「X」の健康状態を確認できる便利なアドオンです。
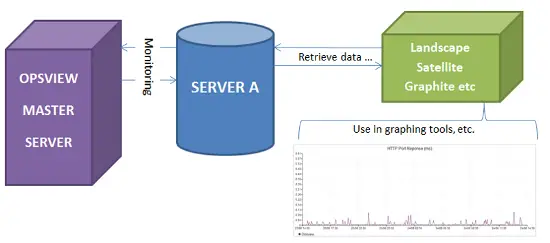
しかし、これが私たちに考えさせました。もしOpsviewを主要な監視ツールとして使用し、顧客がダッシュボードを介してシステムを表示し、メールレポートを受け取り、SMSアラートを送信できるようにし、OpsviewのデータをLandscapeダッシュボードに統合できるとしたらどうでしょうか。これにより、「Server100」をOpsviewでクリックし、「Server100」をLandscapeでクリックして同じグラフを見ることが可能になります。これにより、どのツールを使用していてもサーバーの健康状態を確認できるようになります。
Landscapeでこれを行うのは実際には非常に簡単です(システムのニュアンスに慣れれば)。まず、メインコンソールから「カスタムグラフ」に移動する必要があります。
次に、「カスタムグラフを追加」をクリックすると、以下のようなページが表示されます(フィールドをすでに入力して時間を節約しています):
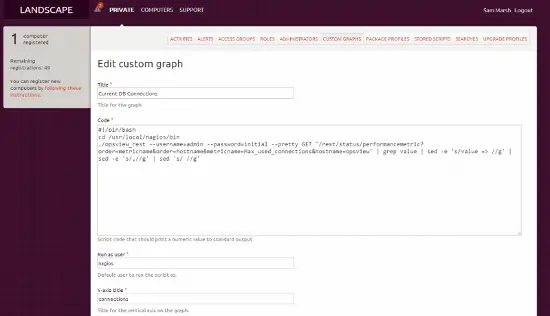
画像では読みづらいかもしれませんが、「コード」は以下に貼り付けています:
#!/bin/bash
cd /usr/local/nagios/bin
./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview' | grep value | sed -e 's/value => //g' | sed -e 's/,//g' | sed 's/ //g' これは基本的にopsview_restコマンドを使用してOpsview監視システムに接続し、ホスト「opsview」から「max_used_connections」メトリックを取得し、いくつかのsed/grep処理を行って、Ubuntuが好まない「value=>28;21;s…」ではなく、グラフ化可能な値「28」を提供します。
これにより、Opsview監視システムをLandscapeホストとして追加し、Opsviewシステムによって監視されている他のホストの健康状態と、それに対して実行されているサービスチェックをLandscapeを介して監視できるようになります。この情報は、次のコマンドを実行することで取得できます:
opsview_rest --username=admin --password=initial --pretty GET /rest/status/performancemetric/?hostname=opsviewここで「?hostname」は、パフォーマンスデータを表示しようとしているホストです。この設定が完了し、前のスクリーンショットに従って保存されると、「実行ユーザーとして設定する:」(rootまたは別のユーザー)と「Y軸タイトル」(秒、データベース接続、温度など)を設定する必要があります。完了したら「保存」をクリックし、これがすべてのホストに適用されます(ボックスにチェックを入れた場合)。
その後、1日ほど経つと、ホストに移動して「監視」タブを表示し、カスタムグラフを確認できます:
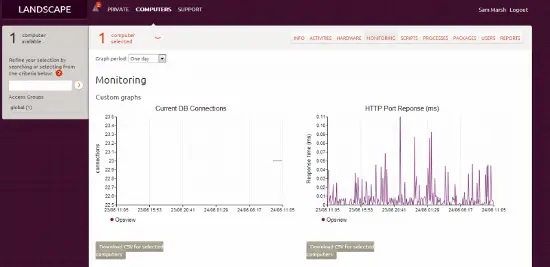
…これがOpsviewとUbuntu Landscapeを統合する方法です。
課題
次に直面した課題は、Landscape管理デバイスが次のコマンドを実行することです:
./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'..これはbash経由で「opsview_rest」を使用し、ローカルで実行されます。理想的なのは、どこからでも(つまり、Landscapeで管理しているサーバーから)これを実行し、Opsviewシステムに対して実行することですが、後者は簡単です。以下のようにプレフィックスを追加できます:
./opsview_rest *--url-prefix=monitoringtool.company.com* --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'…しかし、これでも「opsview_rest」コマンドに依存しており、カスタムグラフがUbuntu Landscape管理システム上でローカルにスクリプトを実行するためには、当然ローカルボックスで利用可能でなければなりません。また、これによりユーザー名とパスワードがホストサーバーに露出します。つまり、あなたのWebサーバーはOpsviewのログイン情報を持つことになります。しかし、後者の問題は、その役割に非常に特定のアクセスを許可することで制限できます。
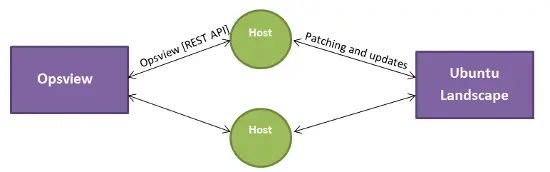
私たちが必要なのは、Opsviewによって監視され、Ubuntu Landscapeによって管理されているホストが、自身の健康状態についてOpsviewにREST APIを介してクエリを実行できる能力です。これにより、この情報をLandscapeに戻してグラフ化できるようになります。しかし、Perlの問題、依存関係などのためにopsview_restを配布することはできないので、私たちは何ができるでしょうか?
私たちの基準を満たす唯一のアイテムは、NRPEを「非伝統的な方法」で使用することのようです。私が言いたいのは、伝統的にNRPEはOpsviewによって情報をクエリされるクライアント側プログラムであるということです。つまり、「CPUはどれくらい忙しいですか?ディスクはどれくらい満杯ですか?」という情報をOpsviewに返します。これらの値はOpsviewに戻され、レポート、ダッシュボード、アラートなどに使用されます。
この例でわかったのは、監視されている/管理されているホストにNRPEクライアント(Opsviewエージェント)をインストールし、それを使用してOpsviewマスター上で実行されているNRPEをクエリできるということです。
このOpsviewマスターでは、「/usr/local/nagios/etc/nrpe_local/overrides.cfg」にNRPEコマンドを指定します(このファイルは存在しないため、作成する必要があります)し、以下の行を追加します:
############################################################################
# Opsview用の追加NRPE設定ファイル
############################################################################
check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl $ARG1$ $ARG2$ここで「get_rest」は、リモートで呼び出すコマンドであり、「=」の東側はローカルで実行される実際のコマンドです。
上記からわかるように、私たちは「landscape_monitor.pl」というものを実行しています。これは、ホスト引数(つまり、$ARG1$はOpsview内の「server00156」または「networkswitch-X624」(ホスト名))を受け取るために書いたPerlスクリプトです。これにより、各ホストごとにチェックコマンドを作成する必要がなくなります。つまり:
check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl server1
check_command[get_rest2]=/usr/local/nagios/bin/landscape_monitor.pl server2
check_command[get_rest3]=/usr/local/nagios/bin/landscape_monitor.pl server3 私たちは単に$ARG1$を使用し、Perlスクリプトがそれを期待することができます。次に、実際のスクリプトがあります(これはJSONとIPCを使用するため、Opsviewシステムに次のパッケージがインストールされている必要があります:libipc-run-perl libjson-any-perl)
#!/usr/bin/perl Shell
use strict;
use warnings;
use IPC::Run qw(run);
use JSON;
my $hostname = $ARGV[0] || '';
my $perf_metric = $ARGV[1] || '';
my @cmd = qw(/usr/local/nagios/bin/opsview_rest --username admin --password initial --data-format json GET);
push @cmd, '/rest/status/performancemetric?order=metricname&order=hostname&metricname='. $perf_metric .'&hostname='. $hostname;
run \
@cmd, \
def, \
ext;
my $data = decode_json($out);
print $data->{list}->[0]->{value};上記のように、変数(ホスト名)を取得し、それを構築しているopsview_restコマンドに追加します。また、パフォーマンスメトリックも取得し、構築したコマンドを実行した後、JSON形式からコマンド出力を印刷します。これにより、Landscapeが使用できる実際の値を取得するためにgrep/sedをたくさん使用する必要がなくなります。
したがって、「landscape_monitor.pl」スクリプトを/usr/local/nagios/bin/に追加し、chmod/chownを行ったら、上記のようにoverrides.cfgファイルを作成し、行を追加できます。
最後に、監視されている/管理されているデバイスでNRPEを開始し、以下のように準備が整います。
シナリオ
ステージ1: 標準の監視環境があります。Opsviewは「サーバーA」を監視し、DB統計、Apache統計などの情報を要求し、ユーザーにGUIを介してこの情報をダッシュボードに表示し、問題が発生したときにメール/テキストメッセージ、アラートなどを送信します。
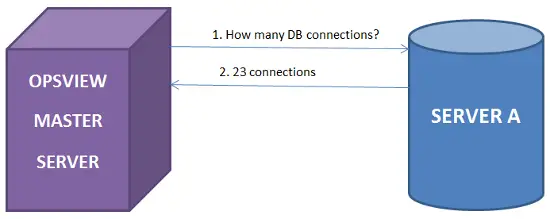
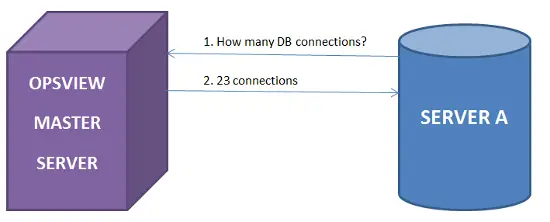
ステージ2: Opsviewがサーバーから数千のメトリックと統計を収集しているので、上記のPerlスクリプトを使用して監視されているサーバー(つまり「サーバーA」)からこれらの統計をクエリするためにREST APIを使用できます。これを行うには、単に以下のコマンドを実行します:
./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connectionsubuntuserver@serverA:/usr/local/nagios/libexec$ ./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connections
23
ubuntuserver@serverA:/usr/local/nagios/libexec$ServerAでcheck_nrpeを使用し、ホスト名「ServerA」を渡すことで、Opsviewが持っているmax_db_connectionsの値を確認できます。
ステージ3: 監視されているデバイスが自身のメトリックを知る能力を持つようになったため、私たちができることの可能性は無限大です。私たちの例では、単にLandscapeを使用してOpsviewが収集したメトリックをグラフ化し、Landscapeシステム内で「一目で」グラフにアクセスできるようにしたいと考えています。また、Opsviewに潜り込んでレポート/ダッシュボードや、より監視に特化した項目を確認できるようにします。しかし、この技術を使用してOpsviewを他のグラフ作成ツールなどと統合することを妨げるものはありません。
これをLandscapeと統合するのは非常に簡単です。単に前述のように別の「カスタムグラフ」を作成し、テキストボックスに以下を追加するだけです:
#!/bin/bash
cd /usr/local/nagios/bin
./check_nrpe –H opsviewserver –c get_rest -a servername max_used_connections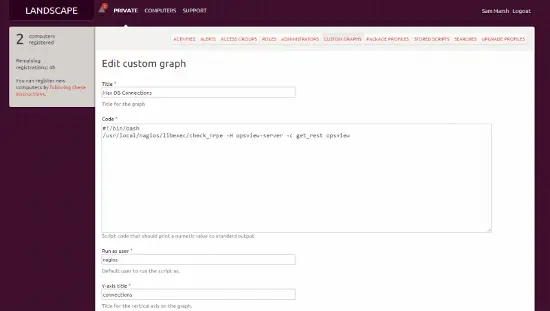
最後に、このグラフを監視したいホストに適用します。これで、Landscapeを介してサーバーの「最大DB接続」を監視できるようになります。これを基にして、メトリックを変更することもできるため、実質的にUbuntu Landscape、RH SatelliteなどからOpsviewが収集したすべてのメトリックを見ることができます。
最後の見通し
理論的には、次のシナリオがあります:
- 100台のUbuntuサーバーがUbuntu Landscapeによって管理され、パッチが適用されています。
- 100台のUbuntuサーバーがOpsview Enterpriseによって監視され、アラートが送信されています。
ホストはLandscapeとOpsviewの両方に追加され、Opsviewを使用してより詳細な監視、アラート、レポート、ダッシュボード、NetFlowなどを行い、特に興味深い「一目で」メトリックをそのホストのLandscapeページに取り込むことができます。
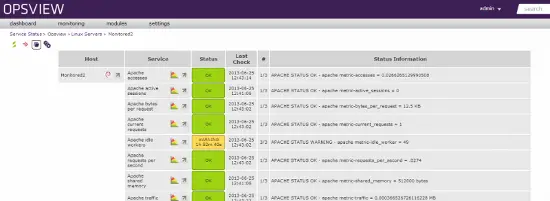
Opsviewのホスト
ホストは上記のようにOpsviewに追加され、すべてのメトリックを確認し、グラフ化し、監視されるタイミングを制御し、期間に基づいてメトリックを変更することができます。
Landscapeのホスト
Landscapeにもホストがあります。このビューから、資産(ハードウェアなど)を確認し、パッケージを更新し、システムの健康状態に関するレポートを確認できます。また、「監視」をクリックして、Landscape内でOpsviewが収集した「一目で」情報を確認できます。
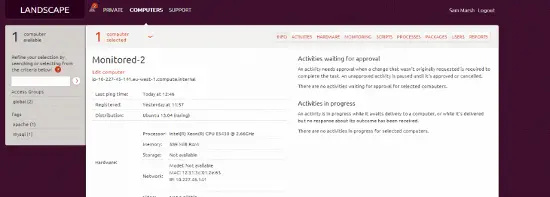
(ただし、あまり使用されていないApacheサーバーです! ^_^)。
Opsview Enterpriseを試す ›
Ubuntu Landscapeを試す ›
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。