Linuxコマンド · 1 min read · Sep 19, 2025
初心者のためのLinux Uniqコマンドチュートリアル(10の例)
もしあなたがLinuxコマンドラインユーザーで、テキストファイルを扱う仕事をしているなら、さまざまな状況で非常に役立つコマンドラインユーティリティがたくさんあることを知っておくべきです。例えば、ファイル内の繰り返し行を報告または削除するツール「uniq」が存在します。
この記事では、わかりやすい例を通じて「uniq」について説明します。しかし、その前に、このチュートリアルで言及されているすべての例と指示は、Ubuntu 16.04LTSでテストされていることを言及しておく価値があります。
Linux Uniqコマンド
冒頭で述べたように、uniqコマンドは繰り返し行を報告または省略します。このコマンドの一般的な構文は次のとおりです:
uniq [OPTION]… [INPUT [OUTPUT]]
ユーティリティのマニュアルページによると:「INPUT(または標準入力)から隣接する一致行をフィルタリングし、OUTPUT(または標準出力)に書き込みます。オプションがない場合、一致行は最初の出現にマージされます。」
以下は、このツールをよりよく理解するためのいくつかの例です。
1. uniqコマンドを使用して繰り返し行を削除する方法
ファイルに次の行が含まれているとします:
明らかに、各行が繰り返されています。では、このファイルでuniqを実行して、何が起こるか見てみましょう。
uniq file1ご覧のとおり、コマンドが生成した出力には繰り返し行が含まれていません。元のファイル - この場合は「file1」 - は影響を受けないことに注意してください。ツールの出力を別のファイルにリダイレクトして、保存して作業することもできます。
2. 各行の繰り返し回数を表示する方法
必要に応じて、uniqが出力に行が繰り返された回数を表示するようにすることもできます。これは、-cコマンドラインオプションを使用することで実現できます。例えば、次のコマンド:
uniq -c file1は次の出力を生成します:
ご覧のとおり、各行の繰り返し回数が出力の前に接頭辞として付加されています。
3. 重複行のみを印刷する方法
uniqが重複行のみを印刷するようにするには、-Dコマンドラインオプションを使用します。例えば、file1が下部に追加の行を含むとします(この行は繰り返されていないことに注意してください)。
次に、次のコマンドを実行します:
uniq -D file1次の出力が生成されます:
ご覧のとおり、-Dオプションはuniqが出力にすべての繰り返し行を表示するようにします。繰り返し行の各グループの後に空行を挿入することで、より明確に区別できます。これは、–all-repeatedオプションを使用して実行できます。
uniq –all-repeated[=METHOD] file1
このオプションは、ユーザーによってメソッド名を入力する必要があります。値はprepend(空行を前に追加)またはseparate(空行を後に追加)です。例えば、prependメソッドでこのオプションを実行する例を示します。

次に、ツールが各グループごとに1つの重複行のみを表示するようにしたい場合は、-dオプションを選択できます。以下はその例です:
明らかに、出力には各グループから1つの繰り返し行のみが表示されました。
4. uniqが最初のいくつかのフィールドを比較しないようにする方法
場合によっては、状況に応じて、2つの行の類似性はそれらの行の小さな部分によって定義されます。例えば、次のファイルの内容を考えてみましょう:
今、行がその2番目のフィールド(HTFまたはFF)に基づいて類似または異なると見なされ、これをuniqに伝えたい場合は、-fコマンドラインオプションを使用して実行できます。
uniq -f [スキップするフィールドの数] [ファイル名]-fオプションは、コマンドにスキップしたいフィールドの数を渡す必要があります。例えば、私たちのケースでは、最初のフィールドをスキップしたいので、-fに’1’を引数として渡すことができます。
uniq -f 1 file1出力は明らかに、uniqがそれぞれの2番目のフィールドに基づいて最初と3番目の行を繰り返し行と見なしたことを示しています。
5. uniqがすべての行を表示し、繰り返しグループを空行で区切る方法
すべての行を表示し、繰り返し行のグループを空行で区切る必要がある場合は、–groupオプションを使用できます。前述の–all-repeatedオプションと同様に、–groupも空行の位置(prepend、append、またはboth)を指定する必要があります。
以下はその例です:
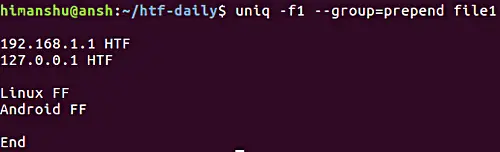
注意:-fオプションは前のセクションで既に説明しました。
6. uniqが非繰り返し行のみを印刷する方法
これまでに理解したように、デフォルトではuniqコマンドは出力に繰り返し行のみを表示します。しかし、代わりに非繰り返し行またはユニークな行のみを表示するようにすることもできます。これは、-uコマンドラインオプションを使用して実現できます。
uniq -u [ファイル名]したがって、私たちのケースでは:
uniq -u file1
以下はその例です:
注意:-fオプションはセクション/ポイント番号4で既に説明しました。
7. uniqが初期の文字数を比較しないようにする方法
以前の例の1つで、uniqがフィールドをスキップする方法について説明しました。しかし、必要に応じて、ツールに初期の文字数をスキップさせることもできます。この機能は、-sコマンドラインオプションを使用してアクセスできます。
uniq -s [文字数] filename
例えば、ファイルに次の行が含まれているとします:
今、各行の最初の4文字を比較する前にスキップしたい場合は、次のように実行できます:
uniq -s 4 file1
以下は上記のコマンドの実行例です:
ご覧のとおり、元々あった4行目(faq_forge)は出力からスキップされました。これは、最初の4文字をスキップした後、3行目と4行目が同じであると見なされたため、uniqによって繰り返し行と見なされたからです。
8. 比較を設定された文字数に制限する方法
文字をスキップする方法と同様に、uniqに比較を設定された文字数に制限するように指示することもできます。これには、-wコマンドラインオプションを使用する必要があります。
uniq -w [文字数] [ファイル名]
例えば、ファイルに次の行が含まれているとします:
今、比較を最初の3文字に制限する必要がある場合は、次のように実行できます:
uniq -w 3 file1
以下は上記のコマンドの実行例です:
3行目と4行目の最初の3文字が同じであるため、これらの行は繰り返し行と見なされました。したがって、出力には3行目のみが表示されます。
9. uniqの比較を大文字と小文字を区別しないようにする方法
デフォルトでは、uniqが行う比較は大文字と小文字を区別します。しかし、-iコマンドラインオプションを使用して、プロセスを大文字と小文字を区別しないようにすることができます。
例えば、前のセクションで説明したのと同じケースを考えてみましょう。ただし、4行目は大文字のH、O、Wで始まります。
次に、前のセクションで使用したのと同じコマンドを実行すると、出力が異なることがわかります:
これは、3行目と4行目の最初の3文字が大文字のためにuniqにとって異なるからです。このような状況では、-iコマンドラインオプションを使用して比較を大文字と小文字を区別しないようにすることができます。
10. uniqの出力をNUL終端にする方法
デフォルトでは、uniqが生成する出力は改行で終わります。しかし、必要に応じて、NUL終端の出力を得ることもできます(スクリプトでuniqを扱う際に便利です)。これは、-zコマンドラインオプションを使用して実現できます。
uniq -z [ファイル名]
結論
私たちは、uniqコマンドが提供するほとんどすべてのコマンドラインオプションをカバーしましたので、ここで説明したことを練習すれば、uniqの動作と提供する機能についてしっかりと理解できるはずです。常に、質問や疑問がある場合は、まずコマンドのマニュアルページを確認してください。
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。