トラフィック分析 · 1 min read · Dec 14, 2025
Debian Lennyを使用したトラフィック分析
Debian Lennyを使用したトラフィック分析
私のネットワーク監視機器を使用して、MRTGで常に重い負荷がかかっているリンクを確認しました。このリンクには多くの異なるトラフィックが集約されているため、累積トラフィックがどのプロトコルやアプリケーションの量で構成されているのかを分析することにしました。
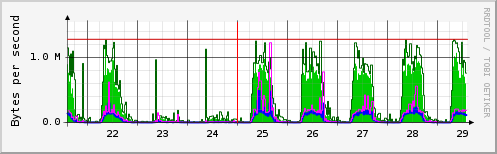
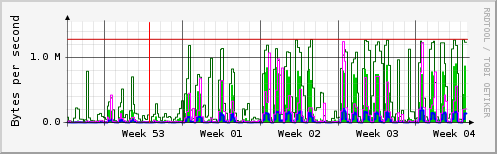
簡単に見て取れるように、週末や祝日以外の日には毎日多くのトラフィックがあります。
そのために使用できるOSSアプリケーションの一つがntopです。www.ntop.orgからの抜粋:
"ntopはネットワーク使用状況を表示するネットワークトラフィックプローブで、人気のあるUnixコマンドのtopと似ています。ntopはlibpcapに基づいており、ほぼすべてのUnixプラットフォームおよびWin32で実行できるようにポータブルな方法で書かれています。ntopユーザーは、ウェブブラウザ(例:netscape)を使用してntop(ウェブサーバーとして機能する)のトラフィック情報をナビゲートし、ネットワークの状態のダンプを取得できます。この場合、ntopは埋め込まれたウェブインターフェースを持つシンプルなRMONライクエージェントとして見ることができます。"予備および免責事項
この記事に記載されているようなことを行うことが法律で禁止されている国もあるため、法的権利を侵害しないようにしてください。また、以下のレシピは私たちが解決策を実装した方法を説明しているものであり、あなたにとって機能することを保証するものではありません。
1. リンク
リンクは10 MBit/sのワイヤスピードを持ち、数キロメートル離れた2つのサイト間のルーティングゲートウェイです。このリンクを通過するデータ量を短く計算したところ、約25 GigaByte/Dayの範囲であることがわかりました。リンクの一方には約2000システム、もう一方には約200システムがあり、私たちにとって興味のある両側の間に約12の通信関係があります。後に、毎日午前7時から午後5時までの間に約4000万から5000万パケットがこのリンクを通過することに気付きました。
ntopはすべてのトラフィックを分析し、トップトーカーなどの通信関係を表示するため、ntopがすべての通信関係についてテーブルを構築するために多くのRAMを使用するだろうと考え、プローブにはできるだけ多くのRAMを搭載することにしました。
2. プローブ
古い未使用のボックスを使用し、Debian Lennyの最小インストールを行い、ntopプローブとして使用することに決めました。X11やこのユースケースには無駄な他のアプリケーションのために貴重なRAMを浪費したくなかったので、最小インストールを行いました。Debianを使用することに決めたのは、私たちのニーズに簡単に適応でき、安定性で知られているからです。しかし、ここで説明したように、他のLinuxディストリビューションでもプローブを構築できますし、*BSDも良い基盤になるかもしれません。
このプローブをリンクを処理するルーターの近くに配置し、ミラーポートを設定してこのリンク上のすべてのトラフィックにアクセスできるようにしました。
プローブには2つ目のNICを装備しました。なぜなら、トラフィックキャプチャ用に1つのNICが必要で、SSHでプローブをリモート管理できるようにしたかったからです。最初のNIC(eth0)はIPアドレスなしで構成されました。これは、ルーターのミラーポートからトラフィックをキャプチャするためだけに使用され、アクティブな通信は行いません。さらに、eth0はすべてのトラフィックを見るためにプロミスキャスモードにする必要があり、これはlibpcapによって行われます。リモート管理専用の2つ目のNIC(eth1)は静的IPアドレスで構成されました。
幸運なことに、プローブとして使用された古いボックスには2GBのRAM(十分でした)、AMD Athlon(tm) 64 Processor 3800+、およびローカル80GBディスクが装備されていました。ディスクは次のようにパーティション分割されました:
# fdisk -lディスク /dev/sda: 80.0 GB, 80026361856 バイト
255 ヘッド, 63 セクター/トラック, 9729 シリンダー
単位 = シリンダーの16065 * 512 = 8225280 バイト
ディスク識別子: 0x37aa37aa
デバイス ブート 開始 終了 ブロック Id システム
/dev/sda1 1 131 1052226 83 Linux
/dev/sda2 132 162 249007+ 82 Linux swap / Solaris
/dev/sda3 163 9729 76846927+ 5 拡張
/dev/sda5 163 9729 76846896 83 Linux/dev/sda1はLenny用の1GBパーティション、/dev/sda2は小さなスワップパーティション、/dev/sda5はキャプチャファイル用に使用されます。ファイルシステムはext3ですが、大きなファイルにはxfsも良い候補です。
3. オフラインレポート
ntopはリアルタイムでトラフィックを分析することも、後で分析および報告のためにpcapファイルを読み取ることもできます。
私たちはまずオフラインアプローチを使用し、午前7時から午後5時までtcpdumpでリンクのトラフィックをキャプチャし、短いシェルスクリプトをcronで実行し、次のステップで分析を行うことに決めました。
シェルスクリプトはSys-Vのinitスクリプトのように見えます:
#!/bin/sh
PATH=/sbin:/usr/sbin:/bin:/usr/bin
do_start() {
ifconfig eth0 up;
tcpdump -i eth0 -w /media/capture/`date +%F_%R`_tcpdump.pcap &
}
do_stop() {
pkill -SIGTERM tcpdump;
ifconfig eth0 down;
}
case "$1" in
start)
do_start 2>&1
;;
stop)
do_stop
;;
*)
echo "Usage: $0 start|stop" >&2
exit 3
;;
esac
午前7時から午後5時までのトラフィックをキャプチャすると、約30GBのサイズのファイルが生成されます:
-rw-r--r-- 1 root root 32725662515 Jan 14 17:00 2020-01-14_07:00_tcpdump.pcapキャプチャファイルを読み取るには、次のようにします:
ntop -m 10.80.192.0/18,10.81.20.0/24 -f /media/capture/2010-01-13_10\:30_tcpdump.pcap -n -4 -w3000 --w3c -p /etc/ntop/protocol.listntopのコマンドラインスイッチとパラメータの詳細な説明については、manページを参照し、ニーズに合わせて調整してください。
その後、ntopのレポートをntopが実行されているシステムのポート3000でウェブブラウザで確認できます。
4. オンラインレポート
ntopを使用する別の方法は、ntop自体がeth0上のトラフィックをキャプチャし、リアルタイムでオンラインレポートを行うことです。これにより、数秒後に何が起こっているのかを見ることができ、(rrdプラグインが有効になっている場合)マウスでズームインできる非常に素晴らしい(管理者に優しい!)グラフを取得できます。
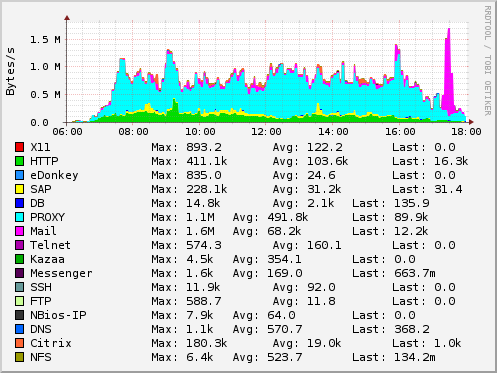
5. 最初の結論
予想通り、全体のトラフィックの約70%が1つのシステム、インターネットプロキシによって引き起こされていることがわかりました。生産的なアプリケーションに関連するトラフィックは3-5%の範囲でした。状況を悪化させるために、この生産的なトラフィックはCitrix、Telnet、SAPなどのインタラクティブなアプリケーションに関連しています。次のステップは、(例えば)diffservやTOSマングリングの助けを借りてトラフィックを優先/整形することにすることにしました。
6. ngrep
次に、プロキシ関連のトラフィックを分析し、どのウェブサイトが最も訪問されているかを調べることにしました。このような深い分析はntopでは不可能ですが、ngrepを使用すれば、特定のシステムに行くトラフィックや特定のポートに行く/来るトラフィックを簡単にキャプチャできます。ngrepはペイロード内の表現を検索することもできるため、次のアプローチはngrepを使用してインターネットプロキシ関連のトラフィックをキャプチャし、さらに分析することでした。
これは次のように簡単に行えます:
grep -d eth0 host 10.89.1.17 -O /media/capture/snap.pcapこの単純なキャプチャ方法はtcpdumpでも行うことができることは言うまでもありません。
午前7時から午後5時まで実行すると、約14GBのファイルが生成される可能性があります:
-rw-r--r-- 1 root root 14223354675 Jan 25 16:26 snap.pcapこのファイルは分析する必要があります。アイデアは次のとおりです。
- tcpdumpでファイルを読み取り、stdoutにダンプする。
- “get http://“でgrepする。
- サイトのFQDNを切り出す。
- 短いシリーズにある重複エントリを捨てる(ブラウザでの1回のクリックに関連する可能性があるため、連続したgetの行が生成される)。
- 出現回数に応じてデータをカウントし、ソートする。
これは中間ファイルを使用していくつかのステップで行うこともできますし、複数のコマンドラインツールをパイプでつなげた1つのコマンドで行うこともできます:
tcpdump -r snap.pcap -A | grep -i "get http://" | awk '/http/ { print $2 }' | cut -d/ -f1-3 | grep http | sed '$!N; /^\(.*
\
\\1$/!P; D' | sort | uniq -c | sort -r > urls.txtこれを実行すると、キャプチャファイル内で見つかったサイトがどれだけ訪問されたかを降順にソートしたファイルが得られます。上記のすべての仮定が正しく処理されているかどうかは100%確信が持てませんが、ファイル内の数字は妥当に見えます。
13418 http://www.gxxxxx.dx
10184 http://www.gxxxxx-axxxxxxxx.cxx
8281 http://www.fxxxxxxx.dx
5470 http://www.bxxx.dx
4269 http://www.sxxxxxx.dx
2550 http://www.gxxx.cxx
2047 http://www.bxxxxxxx-zxxxxxx.dx
2044 http://www.fxxxxxxx.cxx
1618 http://www.exxxxxxx.dx
1410 http://www.lx-bx.dx
....訪問されたウェブサイトに関するレポートを取得する別の方法は、インターネットプロキシのログファイルを解釈することです。たとえば、Squidの場合やCalamarisで処理可能なログを生成するプロキシの場合です。プロキシログがない場合、どのようにそのようなレポートを生成できるかはわかりません。
最後に、このプロジェクトでユーザー関連の情報は評価されていないことを強調したいと思います。
7. URL
Debian
ネットワーク監視機器
MRTG
Ntop
tcpdump + libpcap
RRD
ngrep
Squid
Calamaris
AWK 1行スクリプト
SED 1行スクリプト
新しい投稿を受信箱で受け取る
スパムはありません。いつでも購読を解除できます。