클러스터 배포 · 8 min read · Nov 10, 2025
장애 허용 클러스터를 지속적 또는 고가용성으로 배포하는 방법
일부 기업은 서비스 중단을 허용할 수 없습니다. 서버 장애가 발생할 경우, 이동통신 사업자는 청구 시스템의 다운타임을 경험하여 모든 고객의 연결이 끊길 수 있습니다. 이러한 상황의 잠재적 영향을 인정하는 것은 항상 계획 B를 갖는 아이디어로 이어집니다.
이 기사에서는 서버 장애에 대한 다양한 보호 방법과 고가용성 클러스터를 구축하기 위한 제어 패널인 VMmanager Cloud의 배포에 사용되는 아키텍처에 대해 설명합니다.

서론
클러스터 내구성 분야의 용어는 웹사이트마다 다릅니다. 서로 다른 용어와 정의가 혼합되는 것을 피하기 위해, 이 기사에서 사용될 용어를 정리하겠습니다:
- 장애 허용(Fault Tolerance, FT)은 시스템의 구성 요소 중 하나가 실패한 후에도 시스템이 계속 작동할 수 있는 능력입니다.
- 클러스터는 통신 채널을 통해 연결된 서버 그룹(클러스터 노드)입니다.
- 장애 허용 클러스터(Fault Tolerant Cluster, FTC)는 하나의 서버가 실패하더라도 전체 클러스터의 완전한 사용 불가능 상태로 이어지지 않는 클러스터입니다. 실패한 노드의 기능은 나머지 노드 간에 자동으로 재배분됩니다.
- 지속적 가용성(Continuous Availability, CA)은 사용자가 시간 초과 없이 서비스를 사용할 수 있음을 의미합니다. 노드가 실패한 이후 얼마나 오랜 시간이 지났는지는 중요하지 않습니다.
- 고가용성(High Availability, HA)은 노드 중 하나가 다운될 경우 사용자가 서비스 시간 초과를 경험할 수 있음을 의미하지만, 시스템은 최소한의 다운타임으로 자동으로 복구됩니다.
- CA 클러스터는 지속적 가용성 클러스터입니다.
- HA 클러스터는 고가용성 클러스터입니다.
10개의 노드로 구성된 클러스터를 배포해야 한다고 가정해 보겠습니다. 각 노드에서 가상 머신이 실행됩니다. 목표는 서버 장애 후 가상 머신을 보호하는 것입니다. 계산 밀도를 극대화하기 위해 이중 CPU 서버가 사용됩니다.
처음에는 서비스가 장비가 실패한 후에도 계속 제공되는 지속적 가용성 클러스터를 배포하는 것이 기업에 가장 매력적인 옵션입니다. 실제로 청구 시스템의 운영을 유지하거나 지속적인 생산 프로세스를 자동화해야 하는 경우 지속적 가용성은 필수입니다. 그러나 이 접근 방식에도 함정과 위험이 있으며, 아래에서 다루겠습니다.
지속적 가용성
서비스의 연속성은 이 서비스를 제공하는 물리적 또는 가상 머신의 정확한 복사본이 언제든지 사용 가능할 때만 가능합니다. 이러한 중복 모델을 2N이라고 합니다. 장비가 실패한 후 서버의 복사본을 만드는 데는 시간이 걸리며, 이로 인해 서비스 시간 초과가 발생합니다. 게다가 이 경우 실패한 서버에서 RAM 덤프를 복구할 수 없으므로 그곳에 포함된 모든 정보가 사라지게 됩니다.
CA를 제공하는 데 사용되는 두 가지 방법이 있습니다: 하드웨어 및 소프트웨어 계층. 각 방법에 대해 자세히 살펴보겠습니다.
하드웨어 방법은 모든 구성 요소가 중복되고 계산이 동시에 독립적으로 실행되는 이중 서버를 나타냅니다. 동기화는 두 부분에서 오는 결과를 확인하는 전용 노드를 사용하여 달성됩니다. 노드가 불일치를 감지하면 문제를 정의하고 오류를 수정하려고 시도합니다. 오류를 수정할 수 없는 경우 시스템은 실패한 모듈을 끕니다.
CA 서버 제조업체인 Stratus는 시스템의 전체 다운타임이 연간 32초를 초과하지 않도록 보장합니다. 이러한 결과는 특수 장비를 사용하여 달성할 수 있습니다. Stratus 관계자에 따르면, 각 동기화 모듈에 대해 이중 CPU를 갖춘 CA 서버의 비용은 사양에 따라 약 $160,000입니다. 이 경우 전체 CA 클러스터의 확장 가격은 $1,600,000입니다.
소프트웨어 방법
이 기사가 작성될 당시 지속적 가용성 클러스터 배포를 위한 가장 인기 있는 소프트웨어 도구는 VMware vSphere입니다. 이 제품의 지속적 가용성 기술은 장애 허용(Fault Tolerance)이라고 합니다.
하드웨어 방법과 달리 이 기술에는 다음과 같은 특정 요구 사항이 있습니다:
- 물리적 호스트의 CPU: - Sandy Bridge 아키텍처(또는 그 이후)의 Intel. Avoton은 지원되지 않습니다.
- AMD Bulldozer(또는 그 이후).
- 장애 허용이 있는 머신은 저지연의 10 Gb 네트워크에 연결되어야 합니다. VMware는 전용 네트워크 사용을 강력히 권장합니다.
- VM당 4개 이상의 가상 CPU가 아닙니다.
- 물리적 호스트당 8개 이상의 가상 CPU가 아닙니다.
- 물리적 호스트당 4개 이상의 가상 머신이 아닙니다.
- 가상 머신 스냅샷은 사용할 수 없습니다.
- 스토리지 vMotion은 사용할 수 없습니다.
제한 사항 및 호환성 목록은 공식 문서에서 확인할 수 있습니다.
vSphere 라이센스는 물리적 CPU를 기준으로 합니다. 가격은 라이센스당 $1750 + 연간 구독 및 지원 비용 $550부터 시작합니다. 클러스터 관리 자동화는 VMware vCenter Server도 필요하며, 이는 $8000 이상입니다. 지속적 가용성을 제공하기 위해 2N 모델이 사용되므로, 10개의 노드와 가상 머신이 있는 클러스터를 구축하기 위해 각 서버에 대한 라이센스를 포함하여 10개의 복제 서버를 구매해야 합니다.
소프트웨어의 전체 비용은 2[서버당 CPU 수] (10[가상 머신이 있는 노드 수] + 10[복제 노드 수]) (1750 + 550)[각 CPU당 라이센스 비용] + 8000[VMware vCenter Server 비용] = $100,000입니다. 모든 가격은 반올림되었습니다.
특정 노드 구성은 이 기사에서 설명되지 않으며, 서버 구성 요소는 클러스터의 목적에 따라 항상 다릅니다. 네트워크 장비도 설명되지 않으며, 모든 경우에 동일해야 합니다. 이 기사는 라이센스 비용과 같이 확실히 달라질 수 있는 구성 요소에 중점을 둡니다.
더 이상 개발 및 지원되지 않는 제품도 언급하는 것이 중요합니다.
Remus라는 제품은 Xen 가상화 기반입니다. 이는 마이크로 스냅샷 기술을 활용하는 무료 오픈 소스 솔루션입니다. 불행히도 그 문서는 오랫동안 업데이트되지 않았습니다: 설치 가이드는 2014년에 수명이 종료된 Ubuntu 12.10에 대한 지침을 제공합니다. Google 검색에서도 Remus를 운영에 사용하는 회사를 찾을 수 없었습니다.
QEMU를 수정하여 이 기술로 지속적 가용성 클러스터를 구축하려는 시도가 있었습니다. 이 방향으로 작업을 발표한 두 개의 프로젝트가 있습니다.
첫 번째는 Yoshiaki Tamura가 주도하는 오픈 소스 제품인 Kemari입니다. 이 프로젝트는 라이브 QEMU 마이그레이션을 사용하려고 했습니다. 마지막 커밋은 2011년 2월에 이루어졌으며, 이는 개발이 교착 상태에 이르렀고 계속되지 않을 것임을 시사합니다.
두 번째 제품은 Michael Hines가 설립한 오픈 소스 프로젝트인 Micro Checkpointing입니다. 지난 1년 동안 변경 로그에서 활동이 발견되지 않았으며, 이는 Kemari 프로젝트와 유사합니다.
이러한 사실들은 현재 KVM 가상화에서 지속적 가용성을 달성할 수 있는 가능성이 없다는 결론을 내릴 수 있게 합니다.
모든 지속적 가용성 시스템의 장점에도 불구하고 이러한 솔루션을 배포하고 운영하는 데는 많은 장애물이 있습니다. 그럼에도 불구하고 경우에 따라 장애 허용이 필요할 수 있지만 지속적으로 가용할 필요는 없습니다. 이러한 시나리오는 고가용성 클러스터를 사용할 수 있게 합니다.
고가용성
고가용성 클러스터는 하드웨어가 다운되었는지 자동으로 감지하고 이후 사용 가능한 노드에서 서비스를 시작하여 장애 허용을 제공합니다.
고가용성은 노드에서 실행되는 CPU의 동기화를 지원하지 않으며 항상 로컬 디스크를 동기화할 수 있는 것은 아닙니다. 이를 염두에 두고, 노드에서 사용하는 드라이브는 네트워크 스토리지와 같은 별도의 독립적인 스토리지에 위치하는 것이 좋습니다.
이유는 명확합니다: 노드가 실패한 후에는 접근할 수 없으며, 해당 스토리지 장치에서 정보를 복구할 수 없습니다. 데이터 저장 시스템도 장애 허용이 되어야 하며, 그렇지 않으면 고가용성을 달성할 수 없습니다. 결과적으로 고가용성 클러스터는 두 개의 하위 클러스터로 구성됩니다:
- 가상 머신이 있는 노드로 구성된 컴퓨팅 클러스터
- 컴퓨팅 노드에서 사용하는 디스크가 있는 스토리지 클러스터.
현재 클러스터 노드에서 가상 머신을 사용하여 고가용성 클러스터를 구현하는 데 사용되는 솔루션은 다음과 같습니다:
- Heartbeat, 버전 1.?와 DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Hyper-V 서버 역할이 있는 Windows Server Failover Clustering;
- VMmanager Cloud.
VMmanager Cloud를 자세히 살펴보겠습니다.
VMmanager Cloud
VMmanager Cloud는 고가용성 클러스터를 배포할 수 있는 제품으로 QEMU-KVM 가상화를 사용합니다. 이 기술은 활발히 개발 및 지원되고 있으며 가상 머신에 모든 운영 체제를 설치할 수 있기 때문에 선택되었습니다. 이 제품은 클러스터의 가용성을 감지하기 위해 Corosync를 사용합니다. 서버 중 하나가 다운되면 VMmanager는 나머지 노드 간에 가상 머신을 하나씩 분배합니다.
단순화된 형태로 이 메커니즘은 다음과 같이 작동합니다:
- 시스템은 가상 머신 수가 가장 적은 클러스터 노드를 식별합니다.
- 해당 머신을 배치할 수 있는 충분한 RAM이 있는지 확인합니다.
- 해당 머신에 필요한 메모리가 노드에 충분하면 VMmanager는 이 노드에서 새 가상 머신을 생성합니다.
- 메모리가 충분하지 않으면 시스템은 더 많은 가상 머신이 있는 다른 노드를 확인합니다.
몇 가지 하드웨어 구성을 테스트하고 많은 현재 VMmanager Cloud 사용자의 문의를 통해, 일반적으로 실패한 노드에서 모든 VM의 작업을 분배하고 복구하는 데 45-90초가 걸린다는 것을 확인했습니다. 이는 장비 성능에 따라 다릅니다.
비상 상황에 대비하여 하나 또는 여러 개의 노드를 전용으로 두고, 일상적인 운영 중에는 이러한 노드에 VM을 배포하지 않는 것이 좋습니다. 이는 실패한 노드에서 가상 머신을 추가하기 위해 활성 클러스터 노드에서 자원이 부족할 가능성을 최소화합니다. 만약 하나의 백업 노드만 사용된다면, 이러한 보안 모델을 N+1이라고 합니다.
VMmanager Cloud는 다음과 같은 스토리지 유형을 지원합니다: 파일 시스템, LVM, 네트워크 LVM, iSCSI 및 Ceph [특히 RBD(RADOS 블록 장치), Ceph 구현 중 하나]. 마지막 세 가지는 고가용성에 사용됩니다.
10개의 운영 노드와 1개의 백업 노드에 대한 평생 라이센스 비용은 €3520, 현재 $3865입니다(각 노드당 라이센스 비용은 CPU 수와 관계없이 €320입니다). 라이센스에는 1년의 무료 업데이트가 포함되어 있으며, 두 번째 해부터는 전체 클러스터에 대해 연간 €880의 가격으로 구독 모델을 통해 업데이트가 제공됩니다.
VMmanager Cloud가 고가용성 클러스터 배포에 이미 어떻게 사용되었는지 확인해 보겠습니다.
FirstByte
FirstByte는 2016년 2월에 클라우드 호스팅을 제공하기 시작했습니다. 처음에는 그들의 클러스터가 OpenStack에 구축되었으나, 이 시스템에 대한 전문가의 부족과 비용 문제로 인해 대체 솔루션을 찾게 되었습니다. 고가용성 클러스터를 구축하기 위한 새로운 시스템은 다음 요구 사항을 충족해야 했습니다:
- KVM 가상 머신을 배포할 수 있는 능력.
- Ceph와의 통합.
- 기존 서비스를 제공하기 위한 청구 시스템과의 통합.
- 합리적인 라이센스 비용.
- 소프트웨어 개발자의 지원.
VMmanager Cloud는 모든 요구 사항을 충족했습니다.
FirstByte 클러스터의 특징:
- 데이터 전송은 이더넷 기술과 Cisco 장비를 기반으로 합니다.
- 라우팅은 Cisco ASR9001을 사용하여 수행됩니다. 클러스터는 약 50000개의 IPv6 주소를 사용합니다.
- 컴퓨팅 노드와 스위치 간의 링크 속도는 10 Gbps입니다.
- 스위치와 스토리지 노드 간의 데이터 전송 속도는 20 Gbps이며, 각 10 Gbps의 두 개의 결합 채널이 있습니다.
- 스토리지 노드 간의 복제를 위해 랙 간에 별도의 20 Gbps 링크가 사용됩니다.
- 모든 스토리지 노드에 SAS 디스크와 SSD가 설치되어 있습니다.
- 스토리지 유형은 RBD입니다.
시스템 레이아웃은 아래와 같습니다:
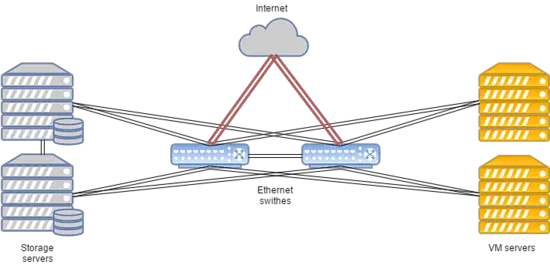
이러한 구성은 평균 이상의 부하를 가진 인기 웹사이트, 게임 서버 및 데이터베이스 호스팅에 적합합니다.
FirstVDS
FirstVDS는 2015년 9월에 시작된 장애 허용 클러스터 서비스를 제공합니다.
이 클러스터에는 다음과 같은 이유로 VMmanager Cloud가 선택되었습니다:
- ISPsystem 제어 패널 사용 경험이 풍부합니다.
- 기본적으로 BILLmanager와의 통합.
- 높은 품질의 기술 지원.
- Ceph와의 통합.
그들의 클러스터는 다음과 같은 특징을 가지고 있습니다:
- 데이터 전송은 56 Gbps의 연결 속도를 가진 Infiniband 네트워크를 기반으로 합니다.
- Infiniband 네트워크는 Mellanox 장비로 구축되었습니다.
- 스토리지 노드는 SSD 드라이브를 가지고 있습니다.
- 스토리지 유형은 RBD입니다.
시스템은 다음과 같이 배치될 수 있습니다:
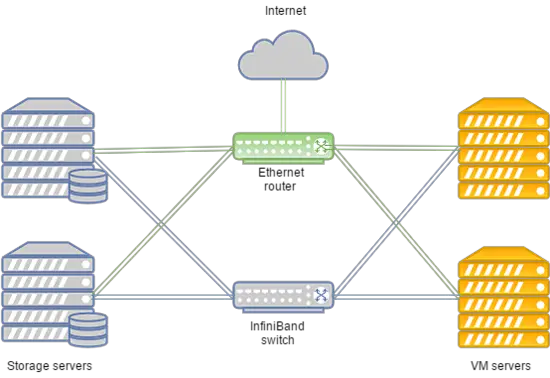
Infiniband 네트워크가 실패할 경우, VM 디스크 스토리지와 컴퓨팅 서버 간의 연결은 Juniper 장비에 배포된 이더넷 네트워크를 통해 설정됩니다. 새로운 연결은 자동으로 설정됩니다.
스토리지와의 통신 속도가 높기 때문에 이 클러스터는 초고속 트래픽을 가진 웹사이트, 비디오 및 콘텐츠 스트리밍, 대량 데이터 호스팅에 적합합니다.
결론
이 기사의 주요 발견을 요약해 보겠습니다.
지속적 가용성 클러스터는 다운타임의 매초가 상당한 손실을 초래할 때 필수입니다. 백업 노드에서 가상 머신을 배포하는 동안 5분의 중단이 허용된다면, 고가용성 클러스터는 하드웨어 및 소프트웨어 비용을 줄이는 좋은 옵션이 될 수 있습니다.
장애 허용을 달성하는 유일한 방법은 과잉입니다. 서버, 데이터 통신 장비 및 링크, 인터넷 접근 채널 및 전원을 복제해야 합니다. 가능한 모든 것을 복제하십시오. 이러한 조치는 전체 시스템의 다운타임을 초래할 수 있는 병목 현상 및 잠재적 실패 지점을 제거할 수 있게 합니다. 위의 조치를 취하면 장애에 강한 장애 허용 클러스터를 갖추게 됩니다.
고가용성 모델이 귀하의 요구 사항에 적합하고 VMmanager Cloud가 이를 실현하는 좋은 도구라고 생각하신다면, 설치 매뉴얼 및 문서를 참조하여 시스템에 대해 더 알아보시기 바랍니다. I 장애 없이 지속적인 운영을 기원합니다!**
새 게시물을 받은 편지함에서 받기
스팸은 없습니다. 언제든지 구독 해지 가능합니다.