하둡 설치 · 8 min read · Dec 21, 2025
우분투 22.04에 아파치 하둡 설치하는 방법

아파치 하둡은 대용량 데이터를 처리하고 저장하기 위한 오픈 소스 프레임워크입니다. 오늘날 산업에서 하둡은 대용량 데이터의 표준 프레임워크가 되었습니다. 하둡은 수백 대 또는 수천 대의 클러스터 컴퓨터 또는 전용 서버에서 실행되도록 설계되었습니다. 이를 염두에 두고 하둡은 구조화된 데이터와 비구조화된 데이터 모두에 대해 높은 볼륨과 복잡성을 가진 대규모 데이터 세트를 처리할 수 있습니다.
모든 하둡 배포에는 다음 구성 요소가 포함됩니다:
- 하둡 공통: 다른 하둡 모듈을 지원하는 공통 유틸리티.
- 하둡 분산 파일 시스템(HDFS): 애플리케이션 데이터에 대한 고처리량 접근을 제공하는 분산 파일 시스템.
- 하둡 YARN: 작업 스케줄링 및 클러스터 리소스 관리를 위한 프레임워크.
- 하둡 맵리듀스: 대규모 데이터 세트의 병렬 처리를 위한 YARN 기반 시스템.
이 튜토리얼에서는 우분투 22.04 서버에 최신 버전의 아파치 하둡을 설치합니다. 하둡은 단일 노드 서버에 설치되며 하둡 배포의 의사 분산 모드를 생성합니다.
전제 조건
이 가이드를 완료하려면 다음 요구 사항이 필요합니다:
- 우분투 22.04 서버 - 이 예제에서는 호스트 이름이 ‘hadoop’이고 IP 주소가 ‘192.168.5.100’인 우분투 서버를 사용합니다.
- sudo/root 관리자 권한이 있는 비루트 사용자.
자바 OpenJDK 설치
하둡은 아파치 소프트웨어 재단의 대규모 프로젝트로, 주로 자바로 작성되었습니다. 이 글을 작성할 당시 하둡의 최신 버전은 v3.3.4로, 자바 v11과 완전히 호환됩니다.
자바 OpenJDK 11은 기본적으로 우분투 저장소에서 제공되며, APT를 통해 설치합니다.
먼저 아래의 apt 명령을 실행하여 우분투 시스템의 패키지 목록/저장소를 업데이트하고 새로 고칩니다.
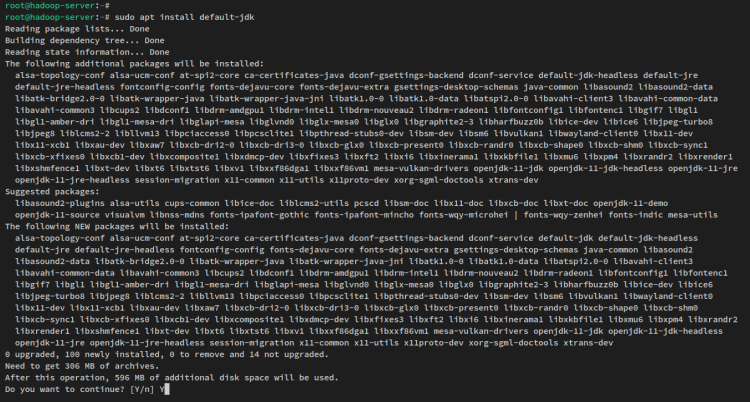
sudo apt update이제 아래의 apt 명령을 통해 자바 OpenJDK 11을 설치합니다. 우분투 22.04 저장소에서 패키지 ‘default-jdk’는 자바 OpenJDK v11을 참조합니다.
sudo apt install default-jdk프롬프트가 표시되면 y를 입력하여 확인하고 ENTER를 눌러 진행합니다. 그러면 자바 OpenJDK 설치가 시작됩니다.
자바가 설치된 후 아래 명령을 실행하여 자바 버전을 확인합니다. 우분투 시스템에 자바 OpenJDK 11이 설치되어 있어야 합니다.
java -version이제 자바 OpenJDK가 설치되었으므로 하둡 프로세스와 서비스를 실행하는 데 사용될 비밀번호 없는 SSH 인증을 가진 새 사용자를 설정합니다.
사용자 및 비밀번호 없는 SSH 인증 설정
아파치 하둡은 시스템에서 SSH 서비스가 실행되고 있어야 합니다. 이는 하둡 스크립트가 원격 서버의 원격 하둡 데몬을 관리하는 데 사용됩니다. 이 단계에서는 하둡 프로세스와 서비스를 실행하는 데 사용될 새 사용자를 생성한 다음 비밀번호 없는 SSH 인증을 설정합니다.
시스템에 SSH가 설치되어 있지 않은 경우 아래의 apt 명령을 실행하여 SSH를 설치합니다. 패키지 ‘pdsh’는 여러 호스트에서 명령을 병렬 모드로 실행할 수 있는 다중 스레드 원격 셸 클라이언트입니다.
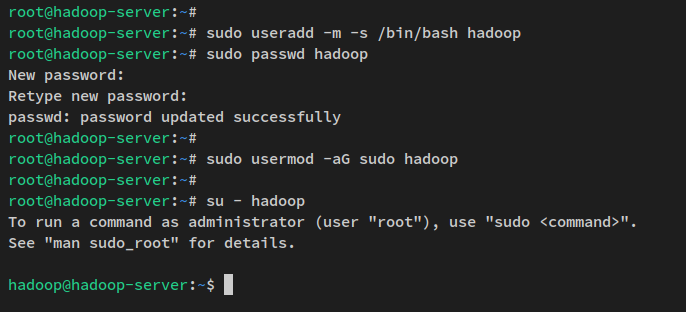
sudo apt install openssh-server openssh-client pdsh이제 아래 명령을 실행하여 새 사용자 ‘hadoop’을 생성하고 ‘hadoop’ 사용자에 대한 비밀번호를 설정합니다.
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoop‘hadoop’ 사용자에 대한 새 비밀번호를 입력하고 비밀번호를 반복합니다.
다음으로, 아래의 usermod 명령을 통해 ‘hadoop’ 사용자를 ‘sudo’ 그룹에 추가합니다. 이렇게 하면 ‘hadoop’ 사용자가 ‘sudo’ 명령을 실행할 수 있습니다.
sudo usermod -aG sudo hadoop이제 ‘hadoop’ 사용자가 생성되었으므로 아래 명령을 통해 ‘hadoop’ 사용자로 로그인합니다.
su - hadoop로그인 후 프롬프트는 다음과 같이 표시됩니다: “ hadoop@hostname.. “.
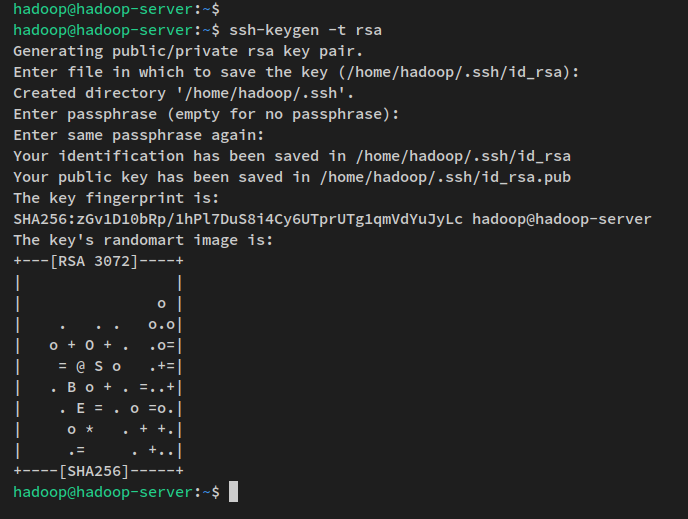
다음으로 아래 명령을 실행하여 SSH 공개 및 개인 키를 생성합니다. 키의 비밀번호를 설정하라는 메시지가 표시되면 ENTER를 눌러 건너뜁니다.
ssh-keygen -t rsaSSH 키는 이제 ~/.ssh 디렉토리에 생성되었습니다. id_rsa.pub는 SSH 공개 키이고 ‘id_rsa’ 파일은 개인 키입니다.
다음 명령을 통해 생성된 SSH 키를 확인할 수 있습니다.
ls ~/.ssh/다음으로 아래 명령을 실행하여 SSH 공개 키 ‘ id_rsa.pub ‘를 ‘ authorized_keys ‘ 파일로 복사하고 기본 권한을 600으로 변경합니다.
SSH에서 ‘ authorized_keys ‘ 파일은 SSH 공개 키를 저장하는 곳으로, 여러 개의 공개 키를 저장할 수 있습니다. ‘ authorized_keys ‘ 파일에 저장된 공개 키를 가진 사람은 올바른 개인 키를 가지고 있다면 비밀번호 없이 ‘ hadoop ‘ 사용자로 서버에 연결할 수 있습니다.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys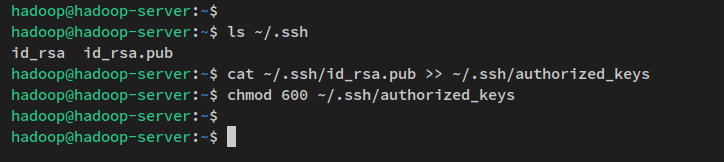
SSH 비밀번호 없는 구성 설정이 완료되었으므로 아래의 ssh 명령을 통해 로컬 머신에 연결하여 확인할 수 있습니다.
ssh localhostyes를 입력하여 확인하고 SSH 지문을 추가하면 비밀번호 인증 없이 서버에 연결됩니다.
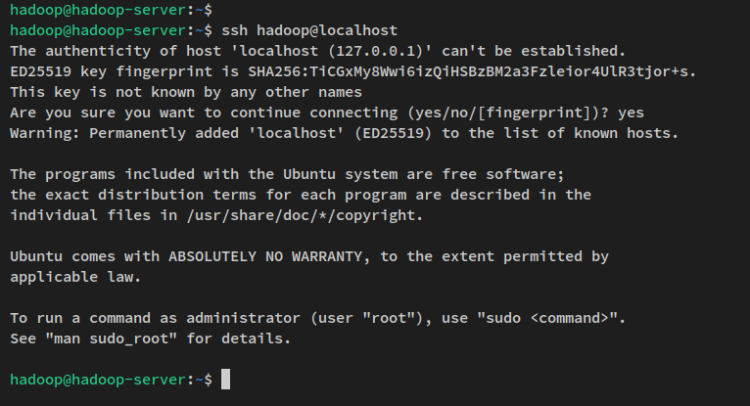
이제 ‘ hadoop ‘ 사용자가 생성되고 비밀번호 없는 SSH 인증이 구성되었으므로 하둡 바이너리 패키지를 다운로드하여 하둡 설치를 진행합니다.
하둡 다운로드
새 사용자를 생성하고 비밀번호 없는 SSH 인증을 구성한 후, 이제 아파치 하둡 바이너리 패키지를 다운로드하고 설치 디렉토리를 설정할 수 있습니다. 이 예제에서는 하둡 v3.3.4를 다운로드하며, 대상 설치 디렉토리는 ‘ /usr/local/hadoop ‘ 디렉토리가 됩니다.
아래의 wget 명령을 실행하여 아파치 하둡 바이너리 패키지를 현재 작업 디렉토리로 다운로드합니다. 현재 작업 디렉토리에 ‘ hadoop-3.3.4.tar.gz ‘ 파일이 생성되어야 합니다.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz다음으로 아래의 tar 명령을 통해 아파치 하둡 패키지 ‘hadoop-3.3.4.tar.gz’를 추출합니다. 그런 다음 추출된 디렉토리를 ‘ /usr/local/hadoop ‘로 이동합니다.
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoop마지막으로 하둡 설치 디렉토리 ‘/usr/local/hadoop’의 소유권을 ‘ hadoop ‘ 사용자와 ‘ hadoop ‘ 그룹으로 변경합니다.
sudo chown -R hadoop:hadoop /usr/local/hadoop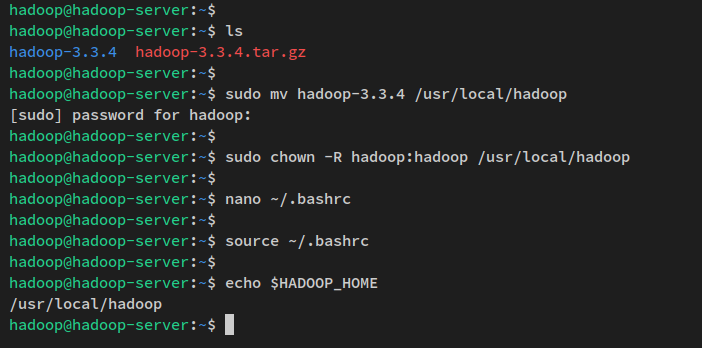
이 단계에서는 아파치 하둡 바이너리 패키지를 다운로드하고 하둡 설치 디렉토리를 구성했습니다. 이를 염두에 두고 이제 하둡 설치 구성을 시작할 수 있습니다.
하둡 환경 변수 설정
아래의 nano 편집기 명령을 통해 구성 파일 ‘ ~/.bashrc ‘를 엽니다.
nano ~/.bashrc파일의 끝에 다음 줄을 추가합니다.
# 하둡 환경 변수
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"파일을 저장하고 편집기를 종료합니다.
다음으로 아래 명령을 실행하여 ‘ ~/.bashrc ‘ 파일 내의 새 변경 사항을 적용합니다.
source ~/.bashrc명령이 실행된 후 새 환경 변수가 적용됩니다. 아래 명령을 통해 각 환경 변수를 확인할 수 있습니다. 각 환경 변수의 출력이 표시되어야 합니다.
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTS다음으로 ‘ hadoop-env.sh ‘ 스크립트에서 JAVA_HOME 환경 변수를 구성합니다.
아래의 nano 편집기 명령을 사용하여 ‘hadoop-env.sh’ 파일을 엽니다. ‘hadoop-env.sh’ 파일은 하둡 설치 디렉토리 ‘/usr/local/hadoop ‘에 해당하는 ‘ $HADOOP_HOME ‘ 디렉토리에 있습니다.
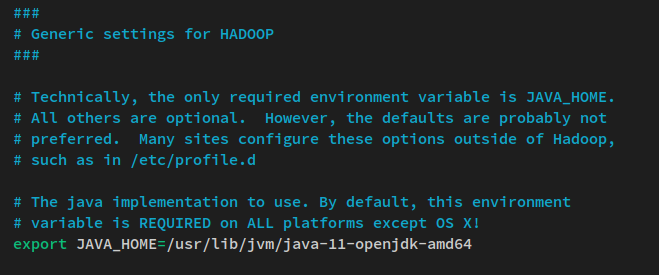
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shJAVA_HOME 환경 줄의 주석을 제거하고 값을 자바 OpenJDK 설치 디렉토리 ‘ /usr/lib/jvm/java-11-openjdk-amd64 ‘로 변경합니다.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64파일을 저장하고 편집기를 종료합니다.
환경 변수 구성이 완료되었으므로 아래 명령을 실행하여 시스템의 하둡 버전을 확인합니다. 시스템에 Apache Hadoop 3.3.4가 설치되어 있어야 합니다.
hadoop version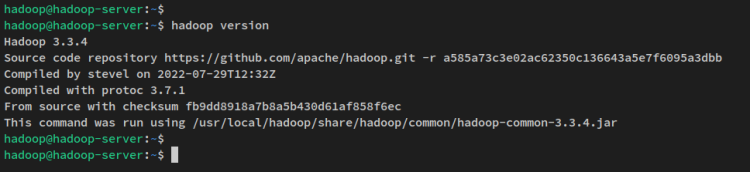
이제 하둡 클러스터를 설정하고 구성할 준비가 되었습니다. 이는 여러 모드로 배포할 수 있습니다.
아파치 하둡 클러스터 설정: 의사 분산 모드
하둡에서는 세 가지 다른 모드로 클러스터를 생성할 수 있습니다:
- 로컬 모드 (독립형) - 기본 하둡 설치로, 단일 Java 프로세스로 실행되며 비분산 모드입니다. 이를 통해 하둡 프로세스를 쉽게 디버그할 수 있습니다.
- 의사 분산 모드 - 단일 노드/서버만으로도 분산 모드로 하둡 클러스터를 실행할 수 있습니다. 이 모드에서는 하둡 프로세스가 별도의 Java 프로세스에서 실행됩니다.
- 완전 분산 모드 - 여러 대 또는 수천 대의 노드/서버가 있는 대규모 하둡 배포입니다. 프로덕션에서 하둡을 실행하려면 완전 분산 모드에서 하둡을 사용해야 합니다.
이 예제에서는 단일 우분투 서버에서 의사 분산 모드로 아파치 하둡 클러스터를 설정합니다. 이를 위해 일부 하둡 구성 파일을 변경합니다:
- core-site.xml - 하둡 클러스터의 NameNode를 정의하는 데 사용됩니다.
- hdfs-site.xml - 하둡 클러스터의 DataNode를 정의하는 데 사용되는 구성입니다.
- mapred-site.xml - 하둡 클러스터의 맵리듀스 구성입니다.
- yarn-site.xml - 하둡 클러스터의 ResourceManager 및 NodeManager 구성입니다.
NameNode 및 DataNode 설정
먼저 하둡 클러스터의 NameNode 및 DataNode를 설정합니다.
아래의 nano 편집기를 사용하여 ‘ $HADOOP_HOME/etc/hadoop/core-site.xml ‘ 파일을 엽니다.
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml파일에 아래 줄을 추가합니다. NameNode IP 주소를 변경하거나 ‘0.0.0.0’으로 대체하여 모든 인터페이스와 IP 주소에서 NameNode가 실행되도록 할 수 있습니다.
fs.defaultFS
hdfs://192.168.5.100:9000
파일을 저장하고 편집기를 종료합니다.
다음으로 아래 명령을 실행하여 하둡 클러스터의 DataNode에 사용될 새 디렉토리를 생성합니다. 그런 다음 DataNode 디렉토리의 소유권을 ‘ hadoop ‘ 사용자에게 변경합니다.
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs그 후 아래의 nano 편집기 명령을 사용하여 ‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’ 파일을 엽니다.
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml파일에 다음 구성을 추가합니다. 이 예제에서는 단일 노드에서 하둡 클러스터를 설정하므로 ‘dfs.replication’ 값을 ‘1’로 변경해야 합니다. 또한 DataNode에 사용될 디렉토리를 지정해야 합니다.
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
파일을 저장하고 편집기를 종료합니다.
NameNode와 DataNode가 구성되었으므로 아래 명령을 실행하여 하둡 파일 시스템을 포맷합니다.
hdfs namenode -format다음과 같은 출력을 받게 됩니다:
이제 다음 명령을 통해 NameNode와 DataNode를 시작합니다. NameNode는 ‘core-site.xml’ 파일에서 구성한 서버 IP 주소에서 실행됩니다.
start-dfs.sh다음과 같은 출력을 보게 됩니다:
이제 NameNode와 DataNode가 실행되고 있으므로 웹 인터페이스를 통해 두 프로세스를 확인합니다.
하둡 NameNode 웹 인터페이스는 포트 ‘ 9870 ‘에서 실행되고 있습니다. 따라서 웹 브라우저를 열고 서버 IP 주소 뒤에 포트 9870을 추가하여 방문합니다(예: http://192.168.5.100:9870/).
이제 다음 스크린샷과 같은 페이지를 보게 됩니다 - NameNode가 현재 활성 상태입니다.
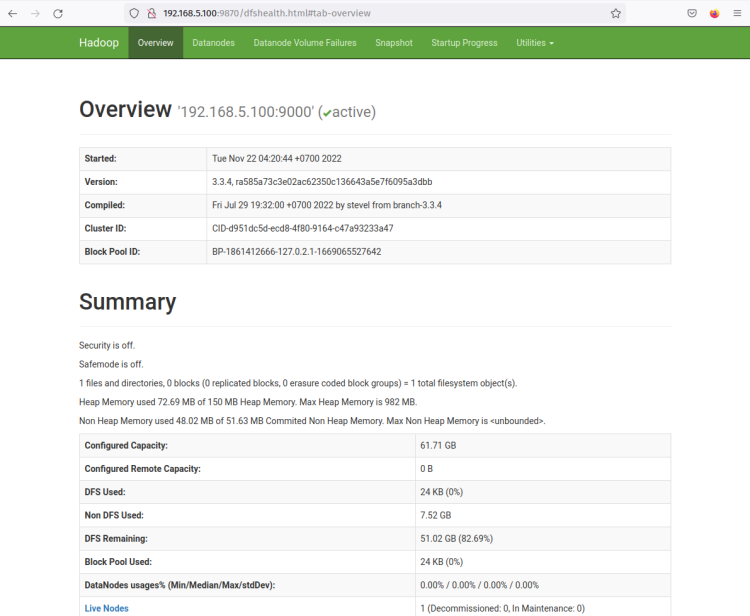
‘Datanodes’ 메뉴를 클릭하면 하둡 클러스터에서 현재 활성 상태인 DataNode를 확인할 수 있습니다. 다음 스크린샷은 하둡 클러스터에서 포트 ‘ 9864 ‘에서 DataNode가 실행되고 있음을 확인합니다.
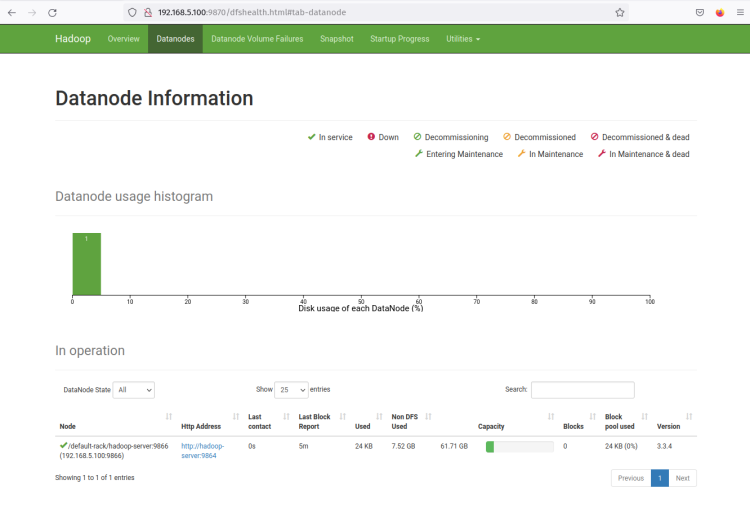
DataNode ‘ Http Address ‘를 클릭하면 DataNode에 대한 자세한 정보가 포함된 새 페이지가 열립니다. 다음 스크린샷은 DataNode가 볼륨 디렉토리 ‘ /home/hadoop/hdfs/datanode ‘에서 실행되고 있음을 확인합니다.
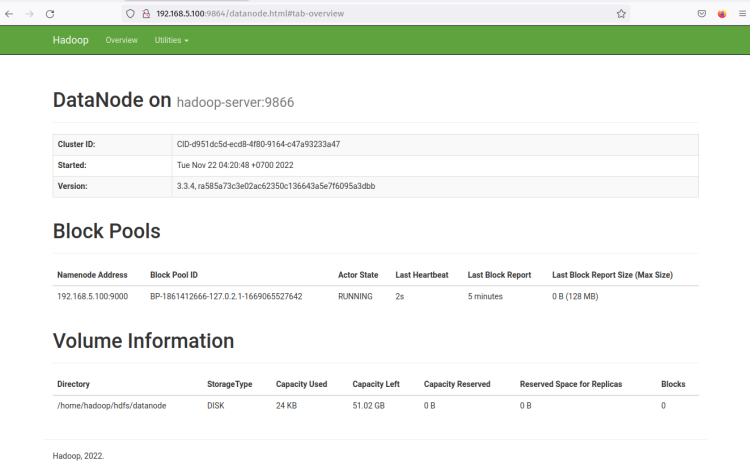
NameNode와 DataNode가 실행되고 있으므로 다음으로 Yarn 관리자에서 MapReduce를 설정하고 실행합니다 (Yet Another ResourceManager 및 NodeManager).
Yarn 관리자
의사 분산 모드에서 Yarn에서 MapReduce를 실행하려면 구성 파일에 몇 가지 변경을 해야 합니다.
아래의 nano 편집기 명령을 사용하여 ‘$HADOOP_HOME/etc/hadoop/mapred-site.xml ‘ 파일을 엽니다.
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml파일에 아래 줄을 추가합니다. mapreduce.framework.name을 ‘yarn’으로 변경해야 합니다.
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
파일을 저장하고 편집기를 종료합니다.
다음으로 아래의 nano 편집기 명령을 사용하여 Yarn 구성 ‘ $HADOOP_HOME/etc/hadoop/yarn-site.xml ‘을 엽니다.
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml기본 구성을 다음 설정으로 변경합니다.
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
파일을 저장하고 편집기를 종료합니다.
이제 아래 명령을 실행하여 Yarn 데몬을 시작합니다. ResourceManager와 NodeManager가 시작되고 있어야 합니다.
start-yarn.shResourceManager는 기본 포트 8088에서 실행되고 있어야 합니다. 웹 브라우저로 돌아가서 서버 IP 주소 뒤에 ResourceManager 포트 ‘8088’을 추가하여 방문합니다(예: http://192.168.5.100:8088/).
하둡 ResourceManager의 웹 인터페이스가 표시됩니다. 여기에서 하둡 클러스터 내에서 실행 중인 모든 프로세스를 모니터링할 수 있습니다.
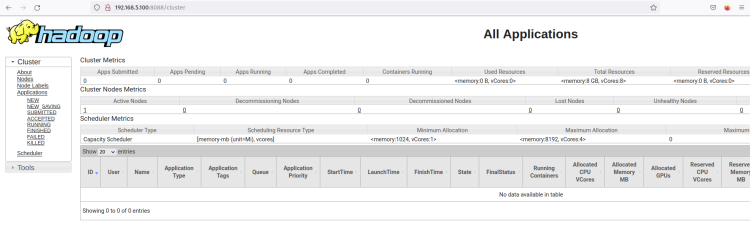
Nodes 메뉴를 클릭하면 하둡 클러스터에서 현재 실행 중인 노드를 확인할 수 있습니다.
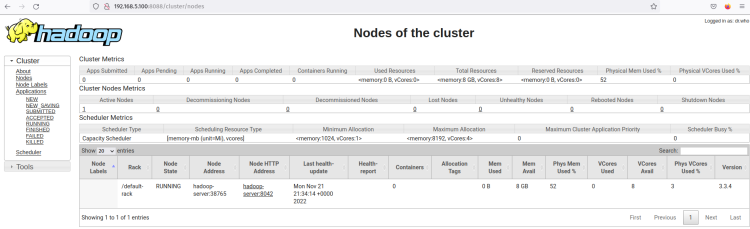
이제 하둡 클러스터가 의사 분산 모드로 실행되고 있습니다. 이는 각 하둡 프로세스가 단일 노드 우분투 서버 22.04에서 단일 프로세스로 실행되고 있음을 의미합니다. 여기에는 NameNode, DataNode, MapReduce 및 Yarn이 포함됩니다.
결론
이 가이드에서는 단일 머신 우분투 22.04 서버에 아파치 하둡을 설치했습니다. 의사 분산 모드가 활성화된 하둡을 설치했으며, 이는 각 하둡 구성 요소가 시스템에서 단일 Java 프로세스로 실행되고 있음을 의미합니다. 이 가이드에서는 자바를 설정하고 시스템 환경 변수를 설정하며 SSH 공개-개인 키를 통해 비밀번호 없는 SSH 인증을 설정하는 방법도 배웠습니다.
이러한 유형의 하둡 배포인 의사 분산 모드는 테스트 용도로만 권장됩니다. 중간 또는 대규모 데이터 세트를 처리할 수 있는 분산 시스템이 필요하다면 클러스터 모드에서 하둡을 배포할 수 있으며, 이는 더 많은 컴퓨팅 시스템이 필요하고 애플리케이션에 대한 높은 가용성을 제공합니다.
새 게시물을 받은 편지함에서 받기
스팸은 없습니다. 언제든지 구독 해지 가능합니다.