AI 훈련 · 8 min read · Sep 12, 2025
당신의 얼굴로 Stable Diffusion AI를 훈련시켜 DreamBooth를 사용하여 예술을 만드는 방법
게스트 포스트: 타루나브 다타.
2021년이 단어 기반 AI 언어 모델의 해였다면, 2022년은 텍스트-이미지 AI 모델로 도약한 해입니다. 오늘날 고품질 이미지를 생성할 수 있는 많은 텍스트-이미지 AI 모델이 있습니다. Stable Diffusion은 가장 인기 있고 잘 알려진 옵션 중 하나입니다. 빠르고 안정적인 모델로 일관된 결과를 생성합니다.

이미지 생성 과정은 여전히 다소 신비롭지만, Stable Diffusion이 뛰어난 결과를 생성한다는 것은 분명합니다. 텍스트에서 이미지를 생성하거나 기존 이미지를 변경하는 데 사용할 수 있습니다. 사용 가능한 옵션과 매개변수는 최종 이미지에 대한 많은 사용자 정의 및 제어를 허용합니다.
유명인 및 인기 인물의 이미지를 작업하는 것은 상대적으로 더 쉽지만, 순전히 이미 사용 가능한 이미지 세트 때문입니다. AI가 자신의 얼굴로 작업하도록 하는 것은 그렇게 쉽지 않습니다. 논리는 AI 모델에 자신의 이미지를 제공한 다음 마법을 부리도록 하는 것이지만, 정확히 어떻게 해야 할까요?
이 기사에서는 DreamBooth 텍스트적 반전을 사용하여 Stable Diffusion 모델을 훈련시키는 방법을 시연하려고 합니다. 자신의 얼굴이나 다른 객체의 AI 표현을 구축하고 놀라운 결과, 정밀도 및 일관성을 가진 결과 사진을 생성하는 방법을 보여드리겠습니다. 너무 기술적으로 들린다면, 잠시 기다려 주시면 최대한 초보자 친화적으로 만들도록 하겠습니다.
Stable Diffusion이란?
기본 사항부터 시작합시다. Stable Diffusion 모델은 대규모 이미지 세트에서 훈련된 최첨단 텍스트-이미지 기계 학습 모델입니다. 훈련 비용은 약 660,000달러로 비쌉니다. 그러나 Stable Diffusion 모델은 자연어를 사용하여 예술을 생성하는 데 사용할 수 있습니다.
딥 러닝 텍스트-이미지 AI 모델은 텍스트를 정확하게 이미지로 변환할 수 있는 능력 덕분에 점점 더 인기를 얻고 있습니다. 이 모델은 무료로 사용할 수 있으며 Hugging Face Spaces 및 DreamStudio에서 찾을 수 있습니다. 모델 가중치도 다운로드하여 로컬에서 사용할 수 있습니다.
Stable Diffusion은 “확산”이라는 프로세스를 사용하여 텍스트 프롬프트와 유사한 이미지를 생성합니다.
간단히 말해, Stable Diffusion 알고리즘은 텍스트 설명을 받아 해당 설명을 기반으로 이미지를 생성합니다. 생성된 이미지는 텍스트와 유사하게 보이지만 정확한 복제품은 아닙니다. Stable Diffusion의 대안으로는 OpenAI의 Dall-E와 Google의 Imagen 모델이 있습니다.
관련 읽기: 아이폰 및 안드로이드용 최고의 AI 아트 생성기 앱 9가지
DreamBooth를 사용하여 얼굴로 Stable Diffusion AI 훈련시키기
오늘은 내 얼굴을 초기 참조로 사용하여 매우 일관되고 정확한 스타일로 이미지를 생성하는 Stable Diffusion 모델을 훈련시키는 방법을 시연하겠습니다.
이를 위해 DreamBooth라는 Google Colab을 사용하여 Stable Diffusion을 훈련시킬 것입니다.
이 Google Colab을 시작하기 전에 특정 콘텐츠 자산을 준비해야 합니다.
1단계: 충분한 무료 공간이 있는 Google Drive
이를 위해 최소 9GB의 무료 공간이 있는 Google Drive 계정이 필요합니다.
무료 Google Drive 계정은 15GB의 무료 저장 공간을 제공하므로 이 작업에 충분합니다. 따라서 이 목적을 위해 새 (일회용) Gmail 계정을 만들 수 있습니다.
2단계: AI 훈련을 위한 참조 이미지
둘째, 얼굴이나 목표 객체의 초상화가 최소 12개 이상 준비되어 있어야 합니다.
- 캡처된 이미지에서 얼굴 특징이 잘 보이고 적절하게 조명이 비춰져 있는지 확인하십시오. 특히 얼굴에 강한 그림자를 사용하지 마십시오.
- 또한, 피사체가 카메라를 바라보거나 두 눈과 모든 얼굴 특징이 명확하게 보이는 측면 프로필이어야 합니다.
- 카메라는 고품질 얼굴 특징을 캡처할 수 있어야 합니다. 가장 좋은 옵션은 전문 수준의 DSLR 또는 미러리스 카메라입니다. 품질이 우수한 스마트폰 카메라도 충분할 수 있습니다.
- 구성이 프레임의 중앙에 위치하고 약간의 머리 공간이 있어야 합니다.
- 입력 이미지로는 얼굴의 클로즈업 사진 최소 12장, 머리부터 허리 위까지 포함된 미드샷 사진 5장, 전체 인물 사진 약 3장이 적절합니다.
- 최소 20장의 참조 사진이 이 목적에 충분해야 합니다.
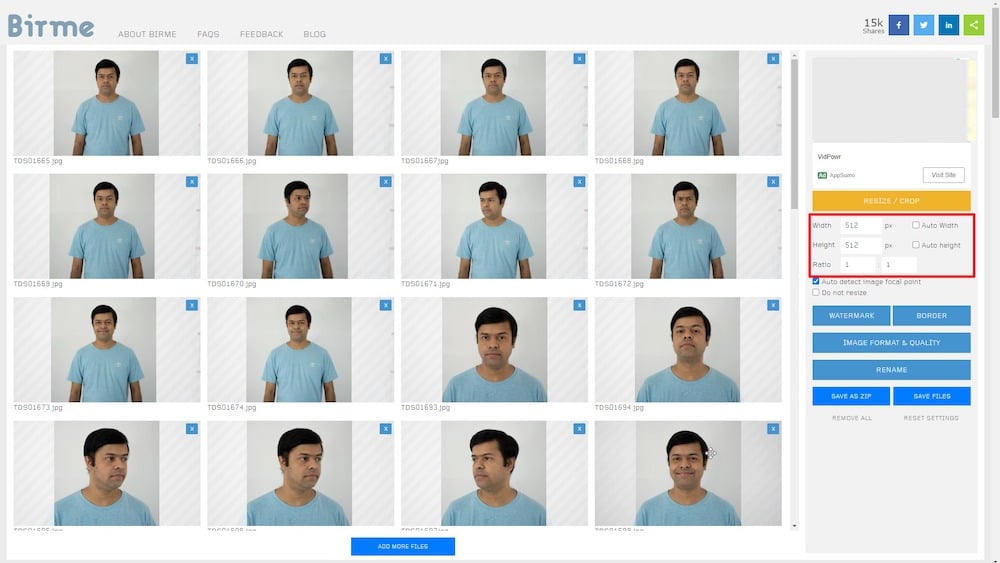
제 경우에는 약 50개의 셀프 포트레이트를 촬영하고 수집했으며, 온라인 도구인 Birme를 사용하여 512 x 512 픽셀로 자른 상태입니다. 이 목적을 위해 다른 이미지 편집기를 사용할 수도 있습니다.
최종 출력 이미지는 웹에 최적화되어야 하며 품질 손실을 최소화하면서 파일 크기가 줄어들어야 합니다.
3단계: Google Colab
이제 Google Colab 런타임을 실행할 수 있습니다.
Google Colab 플랫폼에는 무료 및 유료 버전이 있습니다. Dreambooth는 무료 버전에서 실행할 수 있지만, Colab Pro(유료) 버전에서 성능이 훨씬 더 빠르고 일관적이며, 고속 GPU의 사용을 우선시하고 최소 15GB의 VRAM을 작업에 할당합니다.
몇 달러를 지출하는 것이 괜찮다면, 매달 100개의 컴퓨트 유닛이 포함된 $10의 Colab Pro 구독이 이 세션에 충분합니다.
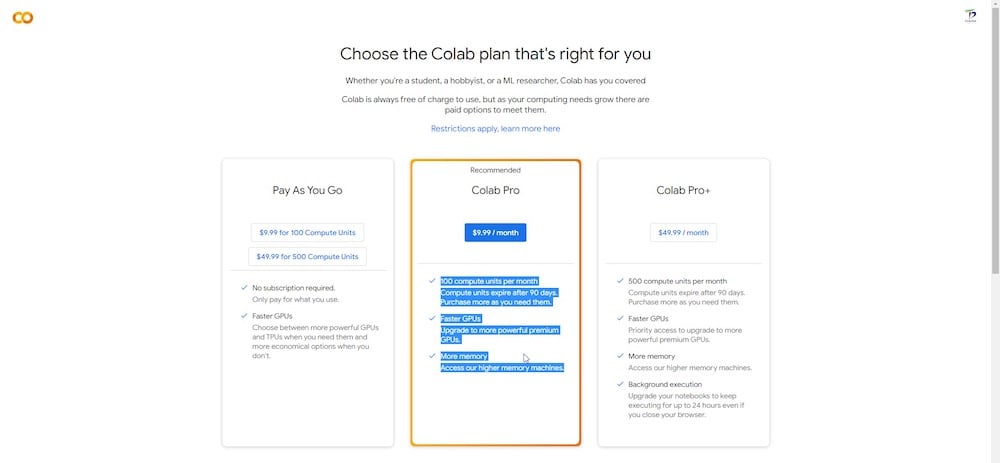
추가 메모리 RAM과 상대적으로 더 강력하고 빠른 GPU에 액세스할 수 있습니다.
다시 말하지만, 이 Colab을 실행하기 위해 기술 전문가일 필요는 없습니다. 사전 코딩 경험도 필요하지 않습니다.
Google Colab에 가입한 후(무료 또는 유료 버전), 자격 증명으로 로그인하고 이 링크로 이동하여 DreamBooth Stable Diffusion을 엽니다.
Google Colab에는 왼쪽에 클릭 가능한 재생 버튼이 있는 “런타임” 섹션 또는 셀들이 순차적으로 배열되어 있습니다. 상단에서 시작하여 런타임을 실행하려면 재생 버튼을 하나씩 클릭하면 됩니다. 각 섹션은 실행해야 하는 런타임으로 구성되어 있습니다. 재생 버튼을 클릭하면 해당 섹션이 런타임으로 실행됩니다. 시간이 지나면 재생 버튼 왼쪽에 녹색 체크 표시가 나타나 런타임이 성공적으로 실행되었음을 나타냅니다.
반드시 한 번에 하나의 런타임만 수동으로 실행하고 현재 런타임이 완료된 후에 다음 “런타임” 섹션으로 이동해야 합니다.
상단 메뉴 바의 런타임 부분에서 모든 런타임을 동시에 실행할 수 있는 옵션이 있습니다. 그러나 이는 권장하지 않습니다.

그 아래에는 “런타임 유형 변경”이라는 레이블이 붙은 옵션이 있습니다. 프로 구독에 가입한 경우 실행을 위해 “프리미엄” GPU와 높은 RAM을 선택하고 저장할 수 있습니다.
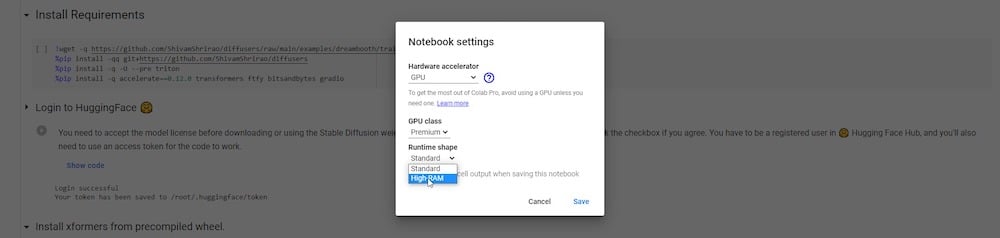
이제 DreamBooth Colab을 시작할 준비가 되었습니다.

DreamBooth에서 훈련된 AI 모델을 성공적으로 완료하기 위한 10단계
1단계: GPU 및 VRAM 결정
첫 번째 단계는 사용 가능한 GPU 및 VRAM 유형을 결정하는 것입니다. 프로 사용자는 빠른 GPU와 더 안정적인 향상된 VRAM에 액세스할 수 있습니다.
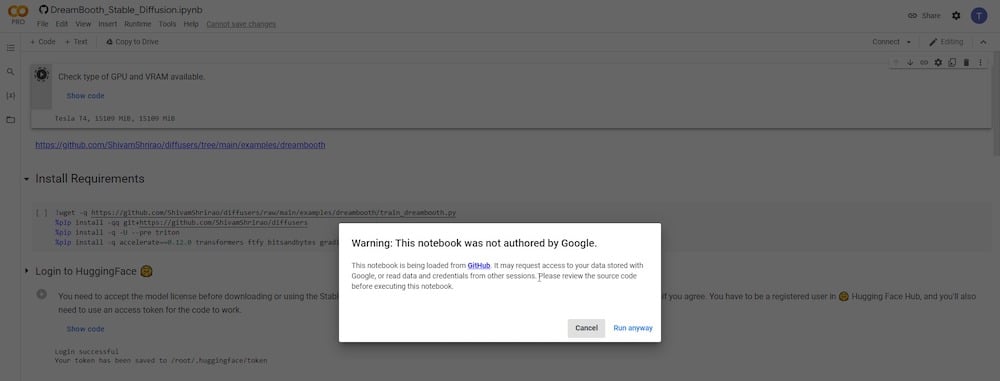
재생 버튼을 클릭하면 GitHub, 개발자의 소스 웹사이트에 접근하고 있다는 경고가 표시됩니다. 계속하려면 “ 계속 실행 ”을 클릭하면 됩니다.
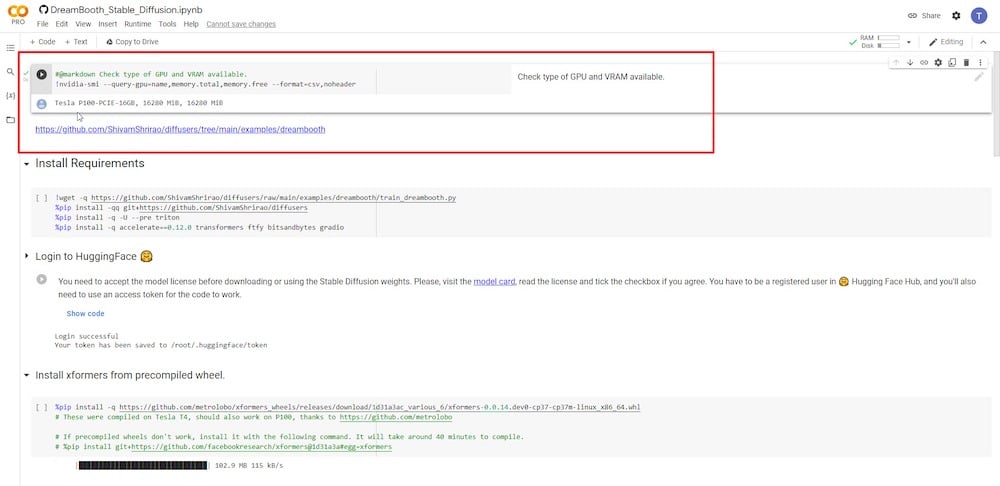
2단계: DreamBooth 실행
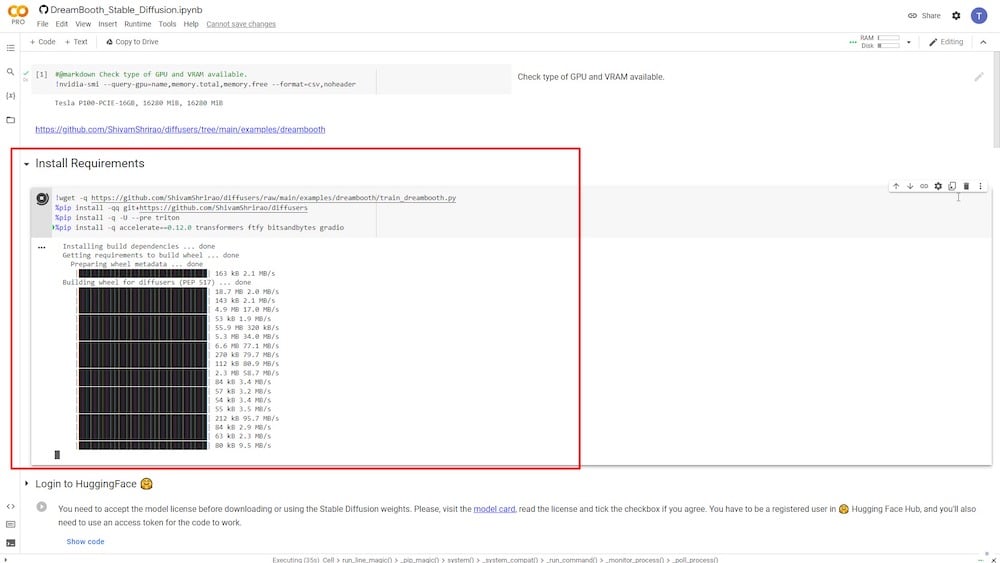
다음 단계에서는 특정 요구 사항과 종속성을 설치해야 합니다. 재생 버튼을 클릭하고 실행되도록 두기만 하면 됩니다.
3단계: Hugging Face에 로그인
재생 버튼을 클릭한 후 다음 단계에서는 Hugging Face 계정에 로그인해야 합니다. 계정이 없으면 무료 계정을 만들 수 있습니다. 로그인한 후 오른쪽 상단 모서리에서 설정 페이지로 이동합니다.
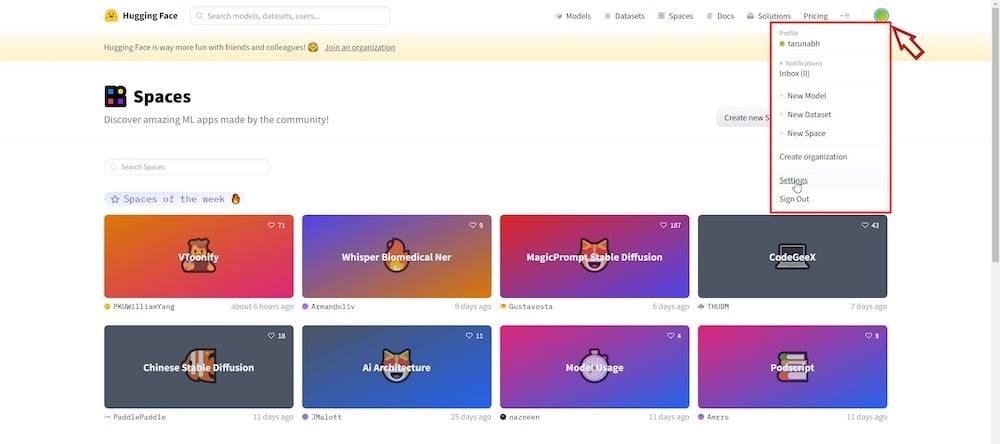
그런 다음 ‘ 액세스 토큰 ‘ 섹션과 ‘ 새로 만들기 ‘ 버튼을 클릭하여 새 “액세스 토큰”을 생성하고 원하는 대로 이름을 바꿉니다.
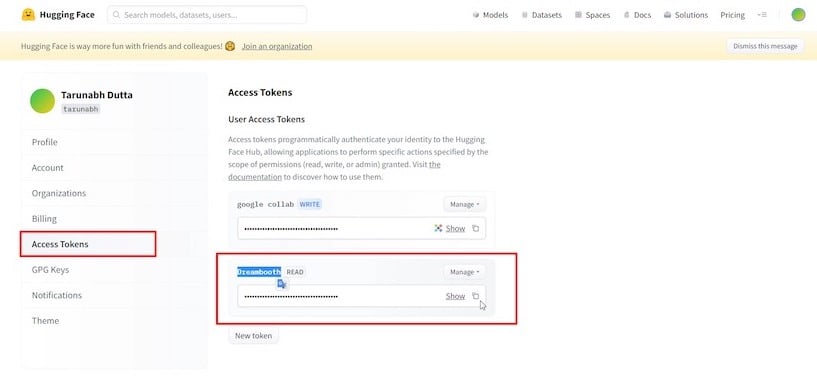
액세스 토큰을 복사한 후 Colab 탭으로 돌아가서 제공된 필드에 입력한 다음 “ 로그인”을 클릭합니다.
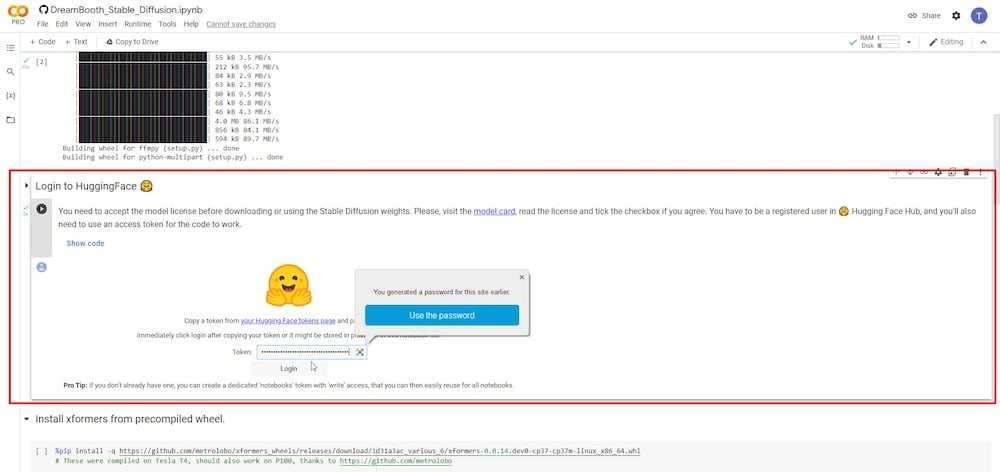
4단계: xformers 설치
이 단계에서는 재생 버튼을 눌러 xformers를 설치할 수 있습니다.
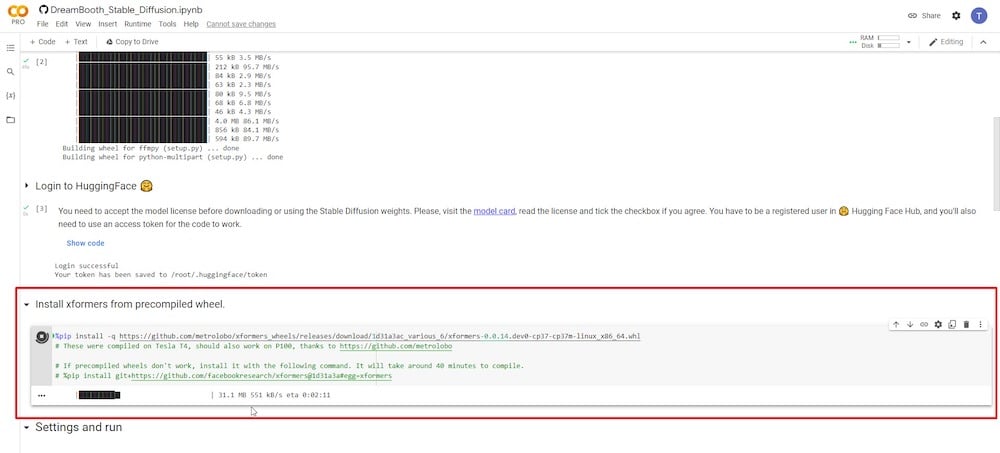
5단계: Google Drive 연결
재생 버튼을 클릭한 후 새 팝업 창에서 Google Drive 계정에 대한 액세스 권한을 요청받습니다. 권한 요청 시 “허용”을 클릭합니다.
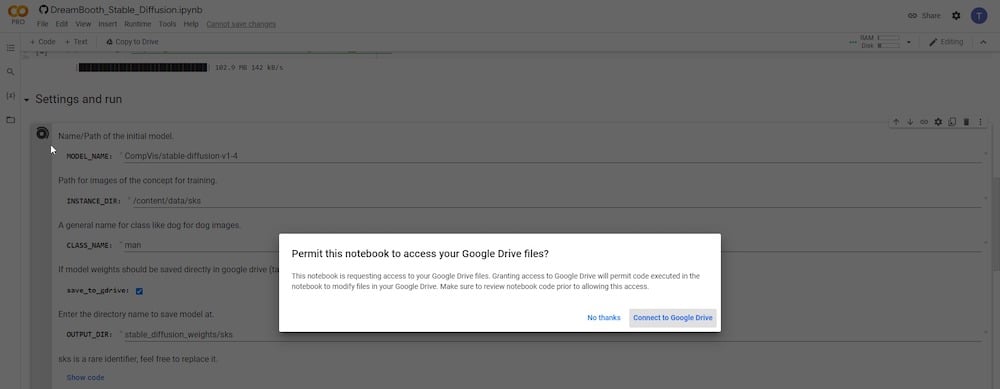
권한을 부여한 후 “ Google Drive에 저장 ”가 선택되었는지 확인해야 합니다. 또한 ‘ CLASS NAME ‘ 변수에 대한 새 이름을 설정해야 합니다. 사람의 참조 이미지를 제출하려면 ‘person’, ‘man’ 또는 ‘woman’이라고 입력하십시오. 참조 이미지가 개의 경우 ‘dog’라고 입력하십시오. 나머지 필드는 변경하지 않아도 됩니다. 또는 입력 디렉토리—’INSTANCE DIR’ 또는 출력 디렉토리—’OUTPUT DIR’의 이름을 바꿀 수 있습니다.
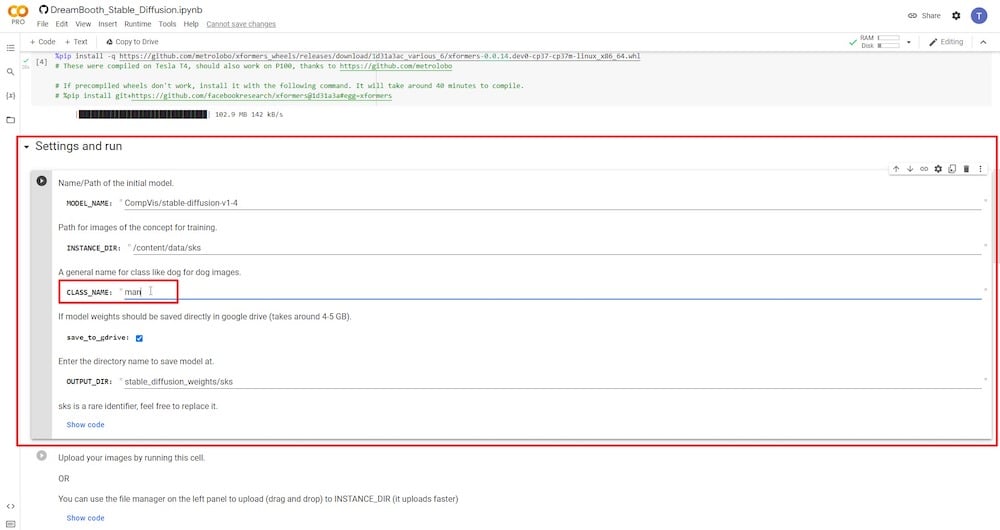
6단계: 참조 사진 업로드
이전 단계에서 재생 버튼을 클릭한 후 모든 참조 사진을 업로드하고 추가할 수 있는 옵션이 표시됩니다.
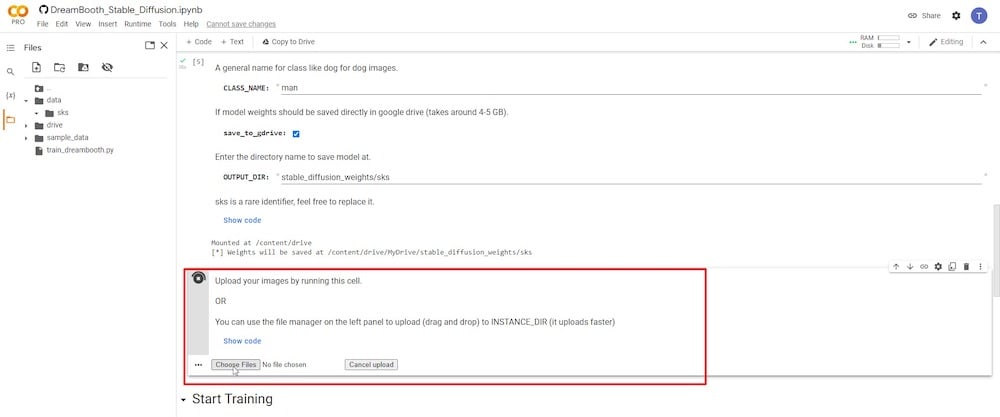
최소 6장, 최대 20장의 사진을 추천합니다. 피사체가 어떻게 캡처되었는지에 따라 최상의 참조 사진을 선택하는 방법에 대한 간략한 설명은 “2단계”를 참조하십시오.
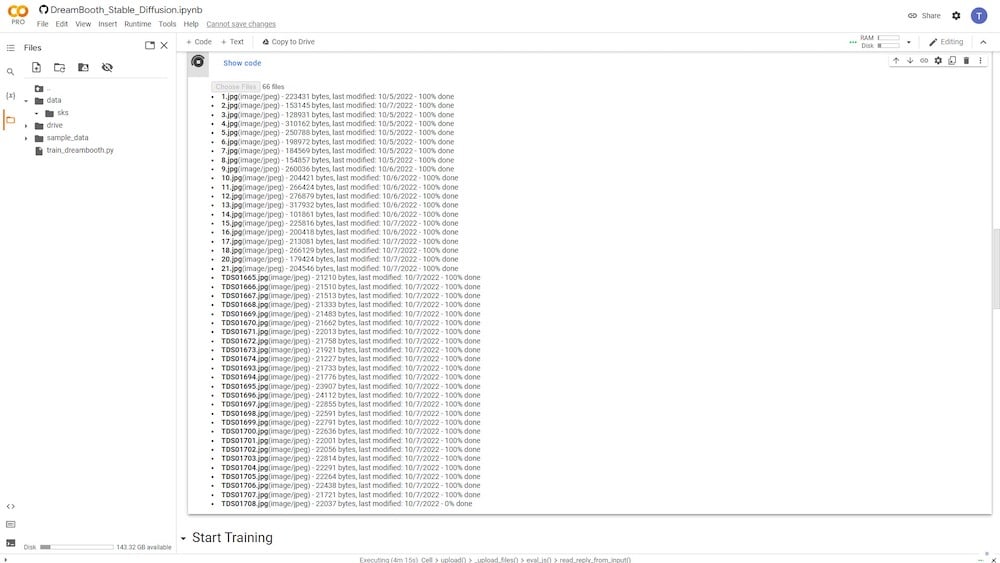
모든 이미지를 업로드하면 왼쪽 열에서 볼 수 있습니다. 폴더 아이콘이 있습니다. 클릭하면 현재 데이터가 저장된 폴더와 하위 폴더를 볼 수 있습니다.
데이터 디렉토리 아래에서 모든 업로드된 사진이 저장된 입력 디렉토리를 볼 수 있습니다. 제 경우에는 “sks”라는 이름으로 알려져 있습니다(기본 이름).
또한 이 콘텐츠는 Google Drive가 아닌 Google Colab 저장소에 임시로 저장된다는 점에 유의하십시오.
7단계: DreamBooth로 AI 모델 훈련
가장 중요한 단계로, 업로드한 모든 참조 사진을 사용하여 새로운 AI 모델을 DreamBooth로 훈련시키는 것입니다.
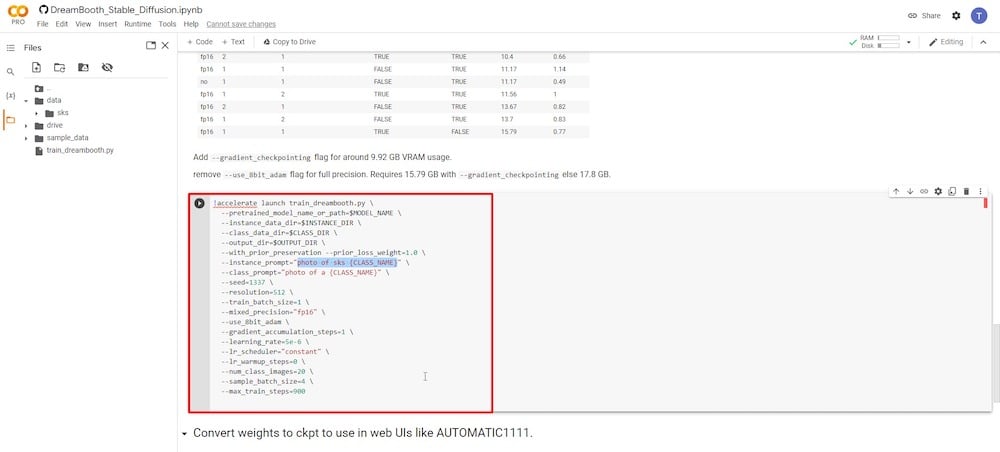
두 개의 입력 필드에만 집중해야 합니다. 첫 번째 매개변수는 “—instance prompt”입니다. 여기에는 매우 독특한 이름을 입력해야 합니다. 제 경우에는 이름 뒤에 이니셜을 붙일 것입니다. 전체 아이디어는 전체 이름을 독특하고 정확하게 유지하는 것입니다.
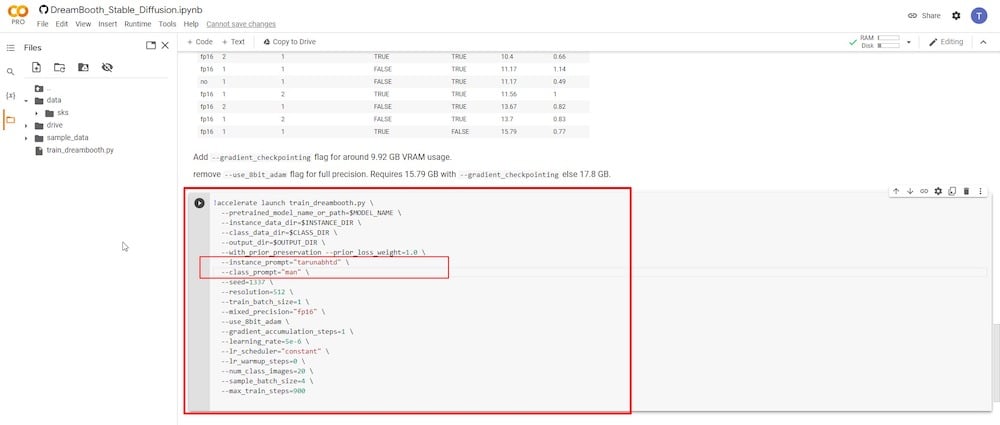
두 번째 중요한 입력 필드는 ‘—class prompt’ 매개변수입니다. ‘4단계’에서 사용한 것과 일치하도록 이름을 바꿔야 합니다. 제 경우에는 “man”이라는 용어를 사용했으므로 이 필드에 다시 입력하고 이전 항목을 덮어씁니다.
나머지 필드는 그대로 두어도 됩니다. 사용자가 ‘—num class images’를 12로, ‘—max train steps’를 1000, 2000 또는 더 높게 변경하는 것을 관찰했습니다. 그러나 이러한 필드를 수정하면 Colab이 메모리 부족으로 충돌할 수 있으므로 처음 시도에서는 수정하지 않는 것이 좋습니다. 충분한 경험을 쌓은 후에 나중에 실험해 볼 수 있습니다.
이 런타임을 재생 버튼을 클릭하여 실행하면 Colab이 필요한 실행 파일을 다운로드하기 시작하고 참조 사진을 사용하여 훈련할 수 있습니다.
모델 훈련은 15분에서 1시간 이상 걸릴 수 있습니다. 인내심을 가지고 진행 상황을 추적해야 하며 런타임이 완료될 때까지 기다려야 합니다. Google Colab이 너무 오랫동안 유휴 상태일 경우 초기화될 수 있으므로 진행 상황을 수시로 확인하고 탭을 클릭해야 합니다.
8단계: AI 모델을 ckpt 형식으로 변환
훈련이 완료되면 훈련된 모델을 Stable Diffusion과 직접 호환되는 ckpt 형식의 파일로 변환할 수 있는 옵션이 제공됩니다.
변환은 두 개의 런타임 단계에서 수행할 수 있습니다. 첫 번째는 “ 다운로드 스크립트”이고, 두 번째는 “ 변환 실행”으로, 훈련된 모델의 다운로드 크기를 줄일 수 있는 옵션이 있습니다. 그러나 그렇게 하면 결과 이미지 품질이 크게 저하됩니다.
따라서 원래 크기를 유지하려면 ‘ fp16 ‘ 옵션을 선택 해제해야 합니다.
이 특정 런타임의 끝에서 “ model.ckpt ”라는 파일이 연결된 Google Drive에 저장됩니다.
이 파일은 나중에 사용할 수 있도록 저장할 수 있습니다. DreamBooth Colab 브라우저 탭을 닫으면 런타임이 즉시 삭제됩니다. 나중에 DreamBooth의 Colab 버전을 다시 열면 처음부터 시작해야 합니다.
훈련된 모델 파일을 Google Drive에 저장하면 나중에 로컬에 설치된 Stable Diffusion GUI, DreamBooth 또는 “model.ckpt” 파일을 로드하여 런타임이 효과적으로 작동하는 데 필요한 Stable Diffusion Colab 노트북과 함께 사용할 수 있습니다. 나중에 사용할 수 있도록 로컬 하드 디스크에 저장할 수도 있습니다.
9단계: 텍스트 프롬프트 준비
“추론” 카테고리 아래의 다음 두 런타임 프로세스는 이미지 생성을 위해 사용되는 텍스트 프롬프트에 대해 새로 훈련된 모델을 준비합니다. 각 런타임의 재생 버튼을 누르면 몇 분 내에 완료됩니다.
10단계: AI 이미지 생성
마지막 단계로, 텍스트 프롬프트를 입력하면 AI 이미지가 생성됩니다.
‘instance_prompt’와 ‘–class_prompt’를 STEP 6에서와 같이 텍스트 프롬프트의 시작 부분에 정확히 사용해야 합니다. 예를 들어, 제 경우에는 “타루나브티디 남자의 초상화, 디지털 페인팅”을 사용하여 나 자신을 닮은 새로운 AI 이미지를 생성했습니다.
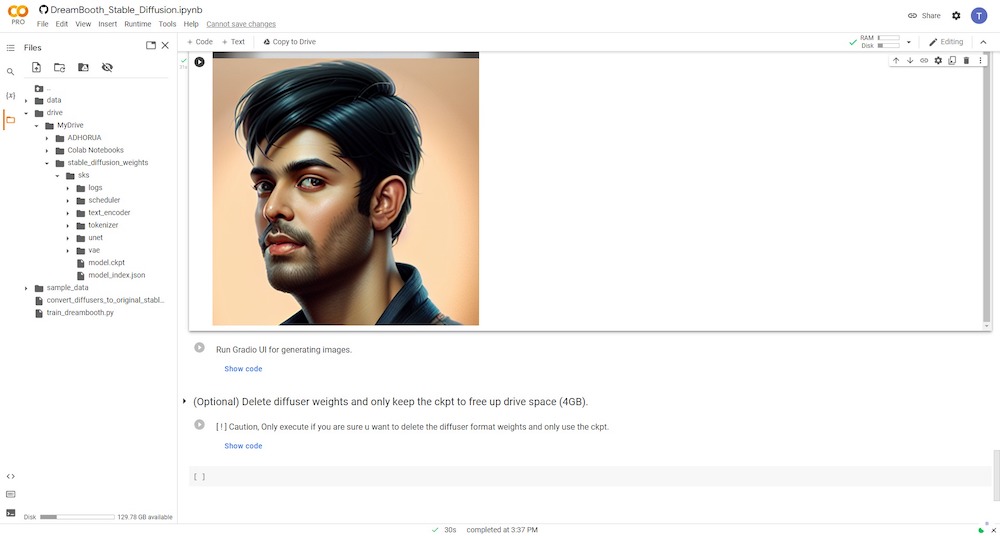
아래에서 DreamBooth의 훈련된 모델로 생성된 이미지 결과를 확인할 수 있습니다.

최상의 출력을 얻기 위한 프롬프트 실험
위에 설명된 단계를 주의 깊게 따르면 참조 이미지의 얼굴 특징과 유사한 AI 이미지를 생성할 수 있습니다. 이 방법은 텍스트적 반전을 위한 AI 기술의 업그레이드된 버전을 실행하기 위해 온라인 Google Colab 플랫폼만 필요합니다.
더 나은 텍스트 프롬프트 아이디어를 얻으려면 다음과 같은 사이트를 확인할 수 있습니다 –
- OpenArt AI
- Krea AI
- Lexica art
다양한 예술 스타일과 조합을 사용하여 더 나은 텍스트 프롬프트를 만드는 기술도 배워야 합니다. 좋은 출발점은 Stable Diffusion SubReddit입니다.
Reddit에는 Stable Diffusion에 전념하는 대규모 커뮤니티가 있습니다. 또한 새로운 Stable Diffusion의 길을 탐구하고 공유하는 여러 Facebook 그룹과 Discord 커뮤니티가 있습니다.
아래는 YouTube에서 시청할 수 있는 몇 가지 DreamBooth 튜토리얼 비디오 링크를 공유합니다 –
이 가이드가 유용하길 바랍니다. 질문이 있으시면 아래에 댓글을 남겨 주시면 도와드리겠습니다.
저자: 타루나브 다타는 독립 배너 ‘TD Film Studio’ 아래에서 16년 동안 45개 이상의 프로젝트를 완료한 수상 경력의 영화 제작자입니다.
새 게시물을 받은 편지함에서 받기
스팸은 없습니다. 언제든지 구독 해지 가능합니다.