리눅스 명령어 · 4 min read · Sep 19, 2025
리눅스 uniq 명령어 초보자 튜토리얼 (10가지 예제)
리눅스 명령어 라인 사용자라면 텍스트 파일을 다루는 작업이 포함되어 있을 것이고, 다양한 상황에서 큰 도움이 될 수 있는 많은 명령어 유틸리티가 있다는 것을 알고 있어야 합니다. 예를 들어, 파일에서 반복된 줄을 보고하거나 삭제하는 ‘uniq’라는 도구가 있습니다.
이 기사에서는 이해하기 쉬운 예제를 통해 ‘uniq’에 대해 논의할 것입니다. 하지만 그 전에, 이 튜토리얼에서 언급된 모든 예제와 지침은 Ubuntu 16.04LTS에서 테스트되었다는 점을 언급할 가치가 있습니다.
리눅스 uniq 명령어
앞서 언급했듯이, uniq 명령어는 반복된 줄을 보고하거나 생략합니다. 이 명령어의 일반적인 구문은 다음과 같습니다:
uniq [OPTION]... [INPUT [OUTPUT]]유틸리티의 매뉴얼 페이지에 따르면: “인접한 일치하는 줄을 INPUT(또는 표준 입력)에서 필터링하고, OUTPUT(또는 표준 출력)에 작성합니다. 옵션이 없으면, 일치하는 줄은 첫 번째 발생으로 병합됩니다.”
다음은 도구를 더 잘 이해하는 데 도움이 될 몇 가지 예제입니다.
1. uniq 명령어를 사용하여 반복된 줄 삭제하기
파일에 다음과 같은 줄이 포함되어 있다고 가정해 보겠습니다:
명확히 각 줄이 반복됩니다. 이제 이 파일에서 uniq를 실행해 보겠습니다. 어떤 일이 일어나는지 보겠습니다.
uniq file1보시다시피, 명령어가 생성한 출력에는 반복된 줄이 없습니다. 원본 파일인 ‘file1’은 영향을 받지 않음을 유의하십시오. 도구의 출력을 다른 파일로 리디렉션하여 저장하고 작업할 수 있습니다.
2. 각 줄의 반복 횟수 표시하기
원하신다면, uniq가 출력에서 줄이 반복된 횟수를 표시하도록 할 수 있습니다. 이는 -c 명령어 옵션을 사용하여 수행할 수 있습니다. 예를 들어, 다음 명령어:
uniq -c file1다음과 같은 출력을 생성합니다:
보시다시피, 각 줄의 반복 횟수가 출력에서 그 앞에 접두사로 붙어 있습니다.
3. 중복된 줄만 출력하기
uniq가 중복된 줄만 출력하도록 하려면, -D 명령어 옵션을 사용하십시오. 예를 들어, file1에 이제 아래쪽에 추가 줄이 포함되어 있다고 가정합니다(이 줄은 반복되지 않습니다).
이제 다음 명령어를 실행하면:
uniq -D file1다음과 같은 출력이 생성됩니다:
보시다시피, -D 옵션은 uniq가 출력에서 모든 반복된 줄을 표시하도록 하며, 모든 반복을 포함합니다. 더 잘 구분하기 위해, 반복된 줄 그룹마다 빈 줄을 추가할 수 있으며, 이는 –all-repeated 옵션을 사용하여 수행할 수 있습니다.
uniq --all-repeated[=METHOD] file1이 옵션은 사용자가 입력해야 하는 방법 이름이 필요합니다. 값은 prepend (빈 줄을 앞에 추가) 또는 separate (빈 줄을 뒤에 추가)일 수 있습니다. 예를 들어, prepend 방법으로 이 옵션을 사용하는 예는 다음과 같습니다.

계속해서, 도구가 그룹당 중복된 줄을 하나만 표시하도록 하려면, -d 옵션을 사용할 수 있습니다. 다음은 그 예입니다:
명확히 각 그룹에서 하나의 반복된 줄만 출력에 표시되었습니다.
4. uniq가 처음 몇 개의 필드를 비교하지 않도록 만들기
때때로 상황에 따라 두 줄의 유사성은 그 줄의 작은 부분에 의해 정의됩니다. 예를 들어, 다음 파일의 내용을 고려해 보십시오:
이제 줄이 두 번째 필드(HTF 또는 FF)에 따라 유사하거나 다르다고 간주되며, 이를 uniq에 전달하고 싶다면, -f 명령어 옵션을 사용하여 수행할 수 있습니다.
uniq -f [건너뛸 필드 수] [파일 이름]-f 옵션은 명령어가 건너뛸 필드 수를 나타내는 숫자를 전달해야 합니다. 예를 들어, 우리의 경우, uniq가 건너뛰기를 원하는 필드는 첫 번째 필드이므로 ‘1’을 -f의 인수로 전달할 수 있습니다.
uniq -f 1 file1출력은 uniq가 각각의 두 번째 필드를 기준으로 첫 번째와 세 번째 줄을 반복된 것으로 간주했음을 명확히 보여줍니다.
5. uniq가 모든 줄을 표시하면서 반복 그룹을 빈 줄로 구분하기
모든 줄을 표시하면서 반복 그룹을 빈 줄로 구분해야 하는 경우, –group 옵션을 사용할 수 있습니다. 앞서 논의한 –all-repeated 옵션과 마찬가지로, –group도 빈 줄의 위치( prepend, append, 또는 both)를 알려주어야 합니다.
예를 들어:
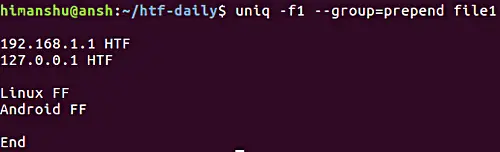
참고: -f 옵션은 이전 섹션에서 이미 논의했습니다.
6. uniq가 비반복 줄만 출력하도록 만들기
이제까지 이해하셨겠지만, 기본적으로 uniq 명령어는 출력에서 반복된 줄만 표시합니다. 그러나 원하신다면, 비반복 또는 고유한 줄만 표시하도록 만들 수 있습니다. 이는 -u 명령어 옵션을 사용하여 수행할 수 있습니다.
uniq -u [파일 이름]따라서, 우리의 경우:
uniq -u file1다음은 그 예입니다:
참고: -f 옵션은 4번 섹션에서 이미 논의했습니다.
7. uniq가 초기 문자 수를 비교하지 않도록 만들기
이전 예제 중 하나에서, uniq가 필드를 건너뛰도록 만드는 방법에 대해 논의했습니다. 그러나 원하신다면, 도구가 초기 문자 수를 건너뛰도록 강제할 수도 있습니다. 이 기능은 -s 명령어 옵션을 사용하여 접근할 수 있습니다.
uniq -s [문자 수] filename예를 들어, 파일에 다음과 같은 줄이 포함되어 있다고 가정해 보겠습니다:
이제 각 줄에서 비교하기 전에 처음 4자를 건너뛰도록 uniq에 지시하려면, 다음과 같이 수행할 수 있습니다:
uniq -s 4 file1위 명령어의 실행 결과는 다음과 같습니다:
보시다시피, 원래 있던 네 번째 줄(faq_forge)은 출력에서 건너뛰어졌습니다. 이는 처음 네 문자를 건너뛴 후, 세 번째와 네 번째 줄이 동일했기 때문에 uniq에 의해 반복된 것으로 간주되었기 때문입니다.
8. 비교를 설정된 문자 수로 제한하기
문자를 건너뛰는 방식과 유사하게, uniq에게 비교를 설정된 문자 수로 제한하도록 요청할 수 있습니다. 이를 위해서는 -w 명령어 옵션을 사용해야 합니다.
uniq -w [문자 수] [파일 이름]예를 들어, 파일에 다음과 같은 줄이 포함되어 있다고 가정해 보겠습니다:
이제 비교를 처음 3자로 제한해야 하는 경우, 다음과 같이 수행할 수 있습니다:
uniq -w 3 file1위 명령어의 실행 결과는 다음과 같습니다:
세 번째와 네 번째 줄의 처음 3자가 동일하므로, 이 줄들은 반복된 것으로 간주되었습니다. 따라서 세 번째 줄만 출력에 표시됩니다.
9. uniq 비교를 대소문자 구분 없이 만들기
기본적으로 uniq가 수행하는 비교는 대소문자를 구분합니다. 그러나 -i 명령어 옵션을 사용하여 프로세스를 대소문자 구분 없이 만들 수 있습니다.
예를 들어, 이전 섹션에서 논의한 동일한 경우를 고려하되, 네 번째 줄이 대문자 H, O, W로 시작한다고 가정합니다.
이제 이전 섹션에서 사용한 동일한 명령어를 실행하면, 출력이 다르게 나타납니다:
이는 세 번째와 네 번째 줄의 처음 세 문자가 대소문자 때문에 uniq에 의해 다르게 인식되기 때문입니다. 이러한 상황에서는 -i 명령어 옵션을 사용하여 비교를 대소문자 구분 없이 만들 수 있습니다.
10. uniq 출력 NUL로 종료하기
기본적으로 uniq가 생성하는 출력은 줄 바꿈으로 종료됩니다. 그러나 원하신다면, 대신 NUL로 종료된 출력을 가질 수 있습니다(스크립트에서 uniq를 다룰 때 유용합니다). 이는 -z 명령어 옵션을 사용하여 가능합니다.
uniq -z [파일 이름]결론
우리는 uniq 명령어가 제공하는 거의 모든 명령어 옵션을 다루었습니다. 따라서 여기서 논의한 내용을 연습하면 uniq가 어떻게 작동하는지, 어떤 기능을 제공하는지에 대한 확고한 아이디어를 얻을 수 있을 것입니다. 항상 그렇듯이, 질문이나 의문이 있는 경우, 먼저 명령어의 매뉴얼 페이지를 확인하시기 바랍니다.
새 게시물을 받은 편지함에서 받기
스팸은 없습니다. 언제든지 구독 해지 가능합니다.