네트워크 분석 · 5 min read · Dec 14, 2025
Debian Lenny를 이용한 트래픽 분석
Debian Lenny를 이용한 트래픽 분석
내 네트워크 모니터링 장비를 사용하여 MRTG에서 항상 높은 부하를 받는 링크를 발견했습니다. 이 링크에는 다양한 트래픽이 집계되므로, 누적 트래픽이 어떤 프로토콜과 애플리케이션으로 구성되어 있는지 분석하기로 결정했습니다.
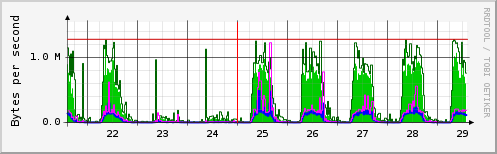
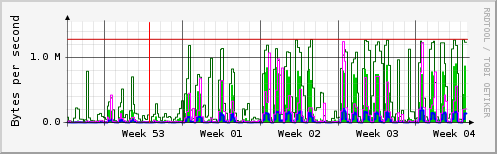
주말과 공휴일을 제외하고 매일 많은 트래픽이 발생하는 것을 쉽게 확인할 수 있습니다.
이 작업을 수행할 수 있는 오픈 소스 애플리케이션 중 하나는 ntop입니다. www.ntop.org의 발췌:
"ntop은 네트워크 사용량을 보여주는 네트워크 트래픽 프로브로, 인기 있는 Unix 명령어 top과 유사합니다. ntop은 libpcap을 기반으로 하며, 모든 Unix 플랫폼과 Win32에서 가상으로 실행될 수 있도록 휴대 가능하게 작성되었습니다. ntop 사용자는 웹 브라우저(예: netscape)를 사용하여 ntop(웹 서버 역할을 함)의 트래픽 정보를 탐색하고 네트워크 상태의 덤프를 얻을 수 있습니다. 후자의 경우, ntop은 내장 웹 인터페이스가 있는 간단한 RMON 유사 에이전트로 볼 수 있습니다."
서론 및 면책 조항
이 기사에서 언급된 것과 같은 작업을 수행하는 것이 일부 국가에서 법적으로 금지될 수 있음을 유의하시기 바랍니다. 법적 권리를 위반하지 않도록 하십시오. 또한 다음 영수증은 우리가 솔루션을 구현한 방법을 설명하며, 귀하에게도 작동한다고 보장하지 않습니다.
1. 링크
링크는 10 MBit/s의 전송 속도를 가지며, 몇 킬로미터 떨어진 두 사이트 간의 라우팅 게이트웨이입니다. 이 링크를 통해 얼마나 많은 데이터가 전송되는지 간단히 계산해본 결과, 하루 약 25 기가바이트 범위에 있어야 한다는 결과가 나왔습니다. 링크 한쪽에는 약 2000개의 시스템이 있고, 다른 쪽에는 약 200개의 시스템이 있으며, 양쪽 간의 약 12개의 통신 관계가 우리에게 관심이 있었습니다. 나중에 우리는 매일 오전 7시부터 오후 5시까지 약 4000만에서 5000만 개의 패킷이 이 링크를 통해 전송된다는 것을 알게 되었습니다.
ntop은 모든 트래픽을 분석하고 통신 관계를 보여주므로, 예를 들어 상위 대화자(top-talkers)와 같은 방식으로, ntop이 모든 통신 관계에 대한 테이블을 구축하기 위해 많은 RAM을 사용할 것이라고 가정했습니다. 따라서 프로브는 가능한 한 많은 RAM을 가져야 한다고 생각했습니다.
2. 프로브
우리는 오래된 사용하지 않는 박스를 사용하기로 결정하고, Debian Lenny의 최소 설치를 수행하여 ntop 프로브로 사용했습니다. 우리는 X11이나 이 사용 사례에 쓸모없는 다른 애플리케이션을 위해 귀중한 RAM을 낭비하고 싶지 않았기 때문에 최소 설치만 수행했습니다. 우리는 Debian을 사용하기로 결정했는데, 이는 우리의 필요에 쉽게 적응할 수 있고 안정성으로 알려져 있기 때문입니다. 그러나 여기 설명된 대로 프로브를 구축하는 것은 익숙한 다른 Linux 배포판으로도 가능합니다. *BSD도 좋은 기반이 될 수 있습니다.
우리는 이 프로브를 링크를 처리하는 라우터 근처에 배치하고, 전체 트래픽에 접근하기 위해 미러 포트를 구성하기로 결정했습니다.
우리는 트래픽 캡처를 위해 하나의 NIC가 필요했기 때문에 프로브에 두 번째 NIC를 장착했습니다. 그리고 SSH를 통해 원격으로 프로브를 관리할 수 있도록 하고 싶었습니다. 첫 번째 NIC(eth0)는 IP 주소 없이 구성되었으며, 이는 라우터의 미러 포트에서 트래픽을 캡처하는 데만 사용되며, 어떤 활성 통신에도 사용되지 않습니다. 또한 eth0는 모든 트래픽을 보기 위해 프로미스큐어스 모드로 설정해야 하며, 이는 libpcap에 의해 수행됩니다. 두 번째 NIC(eth1)는 원격 관리에만 사용되며 정적 IP 주소로 구성되었습니다.
다행히도 프로브로 사용된 오래된 박스는 2GB RAM(충분함), AMD Athlon(tm) 64 Processor 3800+, 그리고 로컬 80GB 디스크가 장착되어 있었습니다. 디스크는 다음과 같이 파티셔닝되었습니다:
# fdisk -l디스크 /dev/sda: 80.0 GB, 80026361856 바이트
255 헤드, 63 섹터/트랙, 9729 실린더
단위 = 16065 * 512 = 8225280 바이트의 실린더
디스크 식별자: 0x37aa37aa
장치 부팅 시작 끝 블록 Id 시스템
/dev/sda1 1 131 1052226 83 Linux
/dev/sda2 132 162 249007+ 82 Linux swap / Solaris
/dev/sda3 163 9729 76846927+ 5 Extended
/dev/sda5 163 9729 76846896 83 Linux/dev/sda1은 Lenny를 위한 1GB 파티션이고, /dev/sda2는 작은 스왑 파티션이며, /dev/sda5는 캡처 파일에 사용됩니다. 파일 시스템은 ext3이지만, xfs도 이러한 대용량 파일에 적합한 후보가 될 수 있습니다.
3. 오프라인 보고
ntop은 실시간으로 트래픽을 분석할 수 있으며, 나중에 분석 및 보고를 위해 pcap 파일을 읽을 수도 있습니다.
우리는 먼저 오프라인 접근 방식을 사용하여 tcpdump로 오전 7시부터 오후 5시까지 링크의 트래픽을 캡처하고, 두 번째 단계에서 분석을 수행하기로 결정했습니다.
쉘 스크립트는 Sys-V 초기화 스크립트와 비슷하게 보입니다:
#!/bin/sh
PATH=/sbin:/usr/sbin:/bin:/usr/bin
do_start() {
ifconfig eth0 up;
tcpdump -i eth0 -w /media/capture/`date +%F_%R`_tcpdump.pcap &
}
do_stop() {
pkill -SIGTERM tcpdump;
ifconfig eth0 down;
}
case "$1" in
start)
do_start 2>&1
;;
stop)
do_stop
;;
*)
echo "Usage: $0 start|stop" >&2
exit 3
;;
esac
오전 7시부터 오후 5시까지 트래픽을 캡처하면 약 30GB 크기의 파일이 생성됩니다:
-rw-r--r-- 1 root root 32725662515 Jan 14 17:00 2020-01-14_07:00_tcpdump.pcap캡처 파일을 읽는 것은 다음과 같이 수행됩니다:
ntop -m 10.80.192.0/18,10.81.20.0/24 -f /media/capture/2010-01-13_10\:30_tcpdump.pcap -n -4 -w3000 --w3c -p /etc/ntop/protocol.listntop의 명령줄 스위치 및 매개변수에 대한 자세한 설명은 매뉴얼 페이지를 참조하시고, 필요에 맞게 조정하십시오.
그런 다음 ntop의 보고서를 ntop이 실행되고 있는 시스템의 포트 3000에서 웹 브라우저로 확인할 수 있습니다.
4. 온라인 보고
ntop을 사용하는 또 다른 방법은 ntop이 자체적으로 eth0에서 트래픽을 캡처하고 실시간으로 보고하는 것입니다. 이를 통해 몇 초 후에 무슨 일이 일어나고 있는지 확인할 수 있으며(활성화된 rrd 플러그인과 함께) 마우스로 확대할 수 있는 정말 멋진(관리 친화적인!) 그래프를 얻을 수 있습니다.
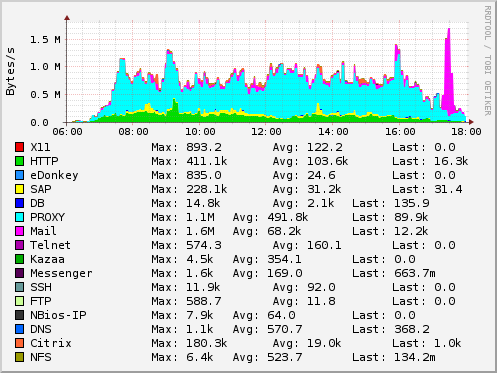
5. 첫 번째 결론
예상대로 전체 트래픽의 약 70%가 하나의 시스템인 인터넷 프록시에서 발생하는 것을 보았습니다. 생산 애플리케이션과 관련된 트래픽은 3-5% 범위에 있었습니다. 상황을 악화시키는 것은 이 생산 트래픽이 Citrix, Telnet 및 SAP와 같은 대화형 애플리케이션과 관련이 있다는 것입니다. 우리는 다음 단계로 (예를 들어) diffserv 또는 TOS 맹글링을 통해 트래픽의 우선 순위를 정하거나 모양을 조정하기로 결정했습니다.
6. ngrep
우리는 이제 프록시 관련 트래픽을 분석하기로 결정했습니다. 어떤 웹사이트가 가장 많이 방문되는지 확인합니다. 이러한 심층 분석은 ntop으로는 불가능하지만, ngrep을 사용하면 특정 시스템으로 가는 트래픽이나 특정 포트로 가는 트래픽만 캡처하는 것이 쉽습니다. Ngrep은 페이로드에서 표현식을 검색할 수 있는 기능도 있으므로, 다음 접근 방식은 ngrep을 사용하여 인터넷 프록시 관련 트래픽만 캡처하고 추가 분석하는 것이었습니다.
이는 간단히 다음과 같이 수행됩니다:
ngrep -d eth0 host 10.89.1.17 -O /media/capture/snap.pcap이러한 간단한 캡처 방식은 tcpdump로도 수행할 수 있습니다.
오전 7시부터 오후 5시까지 수행하면 약 14GB 크기의 파일이 생성될 수 있습니다:
-rw-r--r-- 1 root root 14223354675 Jan 25 16:26 snap.pcap이제 이 파일을 분석해야 합니다. 아이디어는 다음과 같습니다:
- tcpdump로 파일을 읽고, stdout으로 덤프합니다,
- “get http://“를 grep합니다,
- 사이트의 FQDN을 잘라냅니다,
- 짧은 시리즈에 있는 중복 항목을 제거합니다(이는 브라우저에서 클릭으로 인해 발생할 수 있는 연속적인 get의 줄에 속할 수 있습니다),
- 그리고 이 데이터를 발생 빈도에 따라 세고 정렬합니다.
이는 여러 단계에서 중간 파일을 사용하거나 여러 명령줄 도구를 파이프하여 하나의 명령으로 수행할 수 있습니다:
tcpdump -r snap.pcap -A | grep -i "get http://" | awk '/http/ { print $2 }' | cut -d/ -f1-3 | grep http | sed '$!N; /^\(.*
\\1$/!P; D' | sort | uniq -c | sort -r > urls.txt이 명령은 실행되는 동안 캡처 파일에서 발견된 사이트가 얼마나 자주 방문되는지를 내림차순으로 정렬된 파일을 생성합니다. 위에서 만든 모든 가정이 올바르게 처리되었는지 100% 확신할 수는 없지만, 파일의 숫자는 그럴듯해 보입니다.
13418 http://www.gxxxxx.dx
10184 http://www.gxxxxx-axxxxxxxx.cxx
8281 http://www.fxxxxxxx.dx
5470 http://www.bxxx.dx
4269 http://www.sxxxxxx.dx
2550 http://www.gxxx.cxx
2047 http://www.bxxxxxxx-zxxxxxx.dx
2044 http://www.fxxxxxxx.cxx
1618 http://www.exxxxxxx.dx
1410 http://www.lx-bx.dx
....방문한 웹사이트에 대한 보고서를 얻는 또 다른 방법은 인터넷 프록시의 로그 파일을 해석하는 것입니다. 아마도 Calamaris를 사용하여(Squid의 경우 또는 Calamaris로 처리할 수 있는 로그를 생성하는 프록시의 경우) 그렇게 할 수 있습니다. 프록시 로그가 없으면 그러한 보고서를 생성할 수 있는 방법을 알지 못합니다.
마지막으로, 우리는 이 프로젝트에서 사용자 관련 정보가 평가되지 않았음을 강조하고 싶습니다.
7. URL
Debian
네트워크 모니터링 장비
MRTG
Ntop
tcpdump + libpcap
RRD
ngrep
Squid
Calamaris
AWK 1 라인
SED 1 라인
새 게시물을 받은 편지함에서 받기
스팸은 없습니다. 언제든지 구독 해지 가능합니다.