Kubernetes · 27 min read · Nov 03, 2025
Componentes principais de um Cluster Kubernetes

Kubernetes é uma plataforma de código aberto para gerenciar cargas de trabalho e serviços em contêineres que facilita a configuração declarativa e a automação. O nome Kubernetes teve origem no grego, significando timoneiro ou piloto. É portátil, assim como extensível, e possui um ecossistema em rápido crescimento. Os serviços e ferramentas do Kubernetes estão amplamente disponíveis.
Neste artigo, vamos passar por uma visão geral de 10.000 pés dos principais componentes do Kubernetes, desde do que cada contêiner é composto até como um contêiner em um pod é implantado e agendado entre cada um dos trabalhadores. É crucial entender todos os detalhes do cluster Kubernetes para poder implantar e projetar uma solução baseada no Kubernetes como um orquestrador para aplicações em contêineres.
Aqui está um resumo das coisas que vamos cobrir neste artigo:
- Componentes do painel de controle
- Componentes do trabalhador Kubernetes
- Pods como blocos de construção básicos
- Serviços Kubernetes, balanceadores de carga e controladores Ingress
- Implantações Kubernetes e Conjuntos de Demônios
- Armazenamento persistente no Kubernetes
O Plano de Controle do Kubernetes
Os nós mestres do Kubernetes são onde os serviços principais do plano de controle residem; nem todos os serviços precisam residir no mesmo nó; no entanto, para centralização e praticidade, eles costumam ser implantados dessa forma. Isso, obviamente, levanta questões sobre a disponibilidade dos serviços; no entanto, elas podem ser facilmente superadas tendo vários nós e fornecendo solicitações de balanceamento de carga para alcançar um conjunto de nós mestres altamente disponíveis.
Os nós mestres são compostos por quatro serviços básicos:
- O kube-apiserver
- O kube-scheduler
- O kube-controller-manager
- O banco de dados etcd
Os nós mestres podem ser executados em servidores bare metal, máquinas virtuais ou em uma nuvem privada ou pública, mas não é recomendado executar cargas de trabalho em contêineres neles. Veremos mais sobre isso mais adiante.
O diagrama a seguir mostra os componentes dos nós mestres do Kubernetes:
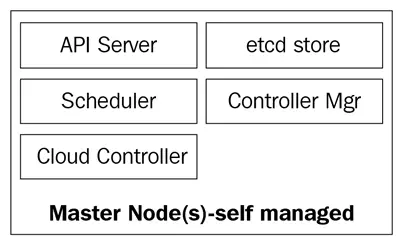
O kube-apiserver
O servidor de API é o que conecta tudo. É a API REST frontend do cluster que recebe manifestos para criar, atualizar e excluir objetos de API, como serviços, pods, Ingress e outros.
O kube-apiserver é o único serviço com o qual devemos nos comunicar; é também o único que grava e se comunica com o banco de dados etcd para registrar o estado do cluster. Com o comando kubectl, enviaremos comandos para interagir com ele. Esta será nossa ferramenta multifuncional quando se trata de Kubernetes.
O kube-controller-manager
O daemon kube-controller-manager, em resumo, é um conjunto de laços de controle infinitos que são enviados por simplicidade em um único binário. Ele observa o estado desejado definido do cluster e garante que ele seja alcançado e satisfeito movendo todas as partes necessárias para isso. O kube-controller-manager não é apenas um controlador; contém vários laços diferentes que observam diferentes componentes no cluster. Alguns deles são o controlador de serviço, o controlador de namespace, o controlador de conta de serviço e muitos outros. Você pode encontrar cada controlador e sua definição no repositório do Kubernetes no GitHub: https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
O kube-scheduler
O kube-scheduler agenda seus pods recém-criados para nós com espaço suficiente para satisfazer as necessidades de recursos dos pods. Basicamente, ele escuta o kube-apiserver e o kube-controller-manager em busca de pods recém-criados que são colocados em uma fila e, em seguida, agendados para um nó disponível pelo agendador. A definição do kube-scheduler pode ser encontrada aqui: https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Além dos recursos de computação, o kube-scheduler também lê as regras de afinidade e anti-afinidade dos nós para descobrir se um nó pode ou não executar aquele pod.
O banco de dados etcd
O banco de dados etcd é um armazenamento de chave-valor consistente e muito confiável que é usado para armazenar o estado do cluster Kubernetes. Ele contém o status atual dos pods em que o nó está sendo executado, quantos nós o cluster possui atualmente, qual é o estado desses nós, quantas réplicas da implantação estão em execução, nomes de serviços e outros.
Como mencionamos antes, apenas o kube-apiserver se comunica com o banco de dados etcd. Se o kube-controller-manager precisar verificar o estado do cluster, ele passará pelo servidor de API para obter o estado do banco de dados etcd, em vez de consultar diretamente o armazenamento etcd. O mesmo acontece com o kube-scheduler se o agendador precisar informar que um pod foi interrompido ou alocado para outro nó; ele informará o servidor de API, e o servidor de API armazenará o estado atual no banco de dados etcd.
Com o etcd, cobrimos todos os principais componentes para nossos nós mestres do Kubernetes, para que estejamos prontos para gerenciar nosso cluster. Mas um cluster não é composto apenas por mestres; ainda precisamos dos nós que realizarão o trabalho pesado executando nossas aplicações.
Nós Trabalhadores do Kubernetes
Os nós trabalhadores que realizam essa tarefa no Kubernetes são simplesmente chamados de nós. Anteriormente, por volta de 2014, eles eram chamados de minions, mas esse termo foi posteriormente substituído apenas por nós, pois o nome era confuso com as terminologias do Salt e fazia as pessoas pensarem que o Salt estava desempenhando um papel importante no Kubernetes.
Esses nós são o único lugar onde você executará cargas de trabalho, pois não é recomendado ter contêineres ou cargas nos nós mestres, pois eles precisam estar disponíveis para gerenciar todo o cluster. Os nós são muito simples em termos de componentes; eles apenas requerem três serviços para cumprir sua tarefa:
- Kubelet
- Kube-proxy
- Tempo de execução de contêiner
Vamos explorar esses três componentes em um pouco mais de profundidade.
O kubelet
O kubelet é um componente Kubernetes de baixo nível e um dos mais importantes depois do kube-apiserver; ambos esses componentes são essenciais para o provisionamento de pods/contêineres no cluster. O kubelet é um serviço que é executado nos nós Kubernetes e escuta o servidor de API para a criação de pods. O kubelet é responsável apenas por iniciar/parar e garantir que os contêineres em pods estejam saudáveis; o kubelet não será capaz de gerenciar quaisquer contêineres que não foram criados por ele.
O kubelet atinge seus objetivos conversando com o tempo de execução de contêiner via interface de tempo de execução de contêiner (CRI). A CRI fornece plugabilidade ao kubelet através de um cliente gRPC, que é capaz de se comunicar com diferentes tempos de execução de contêiner. Como mencionamos anteriormente, o Kubernetes suporta múltiplos tempos de execução de contêiner para implantar contêineres, e é assim que ele alcança esse suporte diversificado para diferentes motores.
Você pode verificar o código-fonte do kubelet em https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
O kube-proxy
O kube-proxy é um serviço que reside em cada nó do cluster e é o responsável por tornar as comunicações entre pods, contêineres e nós possíveis. Este serviço observa o kube-apiserver em busca de alterações em serviços definidos (serviço é uma espécie de balanceador de carga lógico no Kubernetes; vamos nos aprofundar mais em serviços mais adiante neste artigo) e mantém a rede atualizada através de regras iptables que encaminham o tráfego para os pontos finais corretos. O kube-proxy também configura regras em iptables que fazem balanceamento de carga aleatório entre pods atrás de um serviço.
Aqui está um exemplo de uma regra iptables que foi criada pelo kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment –comment “default/example: não tem pontos finais” -m tcp –dport 80 -j REJECT –reject-with icmp-port-unreachable
Note que este é um serviço sem pontos finais (sem pods atrás dele).
Tempo de execução de contêiner
Para poder iniciar contêineres, precisamos de um tempo de execução de contêiner. Este é o motor base que criará os contêineres no kernel dos nós para nossos pods serem executados. O kubelet se comunicará com esse tempo de execução e iniciará ou parará nossos contêineres sob demanda.
Atualmente, o Kubernetes suporta qualquer tempo de execução de contêiner compatível com OCI, como Docker, rkt, runc, runsc, e assim por diante.
Você pode consultar isso https://github.com/opencontainers/runtime-spec para saber mais sobre todas as especificações da página Git-Hub da OCI.
Agora que exploramos todos os componentes principais que formam um cluster, vamos dar uma olhada no que pode ser feito com eles e como o Kubernetes nos ajudará a orquestrar e gerenciar nossas aplicações em contêineres.
Objetos Kubernetes
Os objetos Kubernetes são exatamente isso: eles são objetos lógicos persistentes ou abstrações que representarão o estado do seu cluster. Você é quem está encarregado de dizer ao Kubernetes qual é o seu estado desejado desse objeto para que ele possa trabalhar para mantê-lo e garantir que o objeto exista.
Para criar um objeto, há duas coisas que ele precisa ter: um status e seu spec. O status é fornecido pelo Kubernetes, e é o estado atual do objeto. O Kubernetes gerenciará e atualizará esse status conforme necessário para estar de acordo com seu estado desejado. O campo spec, por outro lado, é o que você fornece ao Kubernetes, e é o que você diz a ele para descrever o objeto que deseja. Por exemplo, a imagem que você deseja que o contêiner esteja executando, o número de contêineres dessa imagem que você deseja executar, e assim por diante.
Cada objeto tem campos de especificação específicos para o tipo de tarefa que eles realizam, e você fornecerá essas especificações em um arquivo YAML que é enviado ao kube-apiserver com kubectl, que o transforma em JSON e o envia como uma solicitação de API. Vamos nos aprofundar em cada objeto e seus campos de especificação mais adiante neste artigo.
Aqui está um exemplo de um YAML que foi enviado ao kubectl:
cat << EOF | kubectl create -f -kind: ServiceapiVersion: v1metadata: Name: frontend-servicespec: selector: web: frontend ports: - protocol: TCP port: 80 targetPort: 9256EOF
Os campos básicos da definição do objeto são os primeiros, e estes não variarão de objeto para objeto e são muito autoexplicativos. Vamos dar uma rápida olhada neles:
- kind: O campo kind diz ao Kubernetes que tipo de objeto você está definindo: um pod, um serviço, uma implantação, e assim por diante
- apiVersion: Como o Kubernetes suporta várias versões de API, precisamos especificar um caminho de API REST que queremos enviar nossa definição
- metadata: Este é um campo aninhado, o que significa que você tem vários subcampos em metadata, onde você escreverá definições básicas, como o nome do seu objeto, atribuindo-o a um namespace específico e também etiquetando um rótulo para relacionar seu objeto a outros objetos Kubernetes
Assim, agora passamos pelos campos mais usados e seus conteúdos; você pode aprender mais sobre as convenções da API do Kubernetes em https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Alguns dos campos do objeto podem ser modificados posteriormente, após o objeto ter sido criado, mas isso dependerá do objeto e do campo que você deseja modificar.
A seguir está uma lista curta dos vários objetos Kubernetes que você pode criar:
- Pod
- Volume
- Serviço
- Implantação
- Ingress
- Segredo
- ConfigMap
E há muitos mais.
Vamos dar uma olhada mais de perto em cada um desses itens.
Pods – a base do Kubernetes
Pods são os objetos mais básicos no Kubernetes e também os mais importantes. Tudo gira em torno deles; podemos dizer que o Kubernetes é para os pods! Todos os outros objetos estão aqui para servi-los, e todas as tarefas que eles realizam são para fazer os pods alcançarem seu estado desejado.
Então, o que é um pod e por que os pods são tão importantes?
Um pod é um objeto lógico que executa um ou mais contêineres juntos no mesmo namespace de rede, a mesma comunicação entre processos (IPC) e, às vezes, dependendo da versão do Kubernetes, o mesmo namespace de ID de processo (PID). Isso ocorre porque eles são os que vão executar nossos contêineres e, portanto, serão o centro das atenções. O objetivo do Kubernetes é ser um orquestrador de contêineres, e com os pods, tornamos a orquestração possível.
Como mencionamos antes, contêineres no mesmo pod vivem em uma “bolha” onde podem se comunicar entre si via localhost, pois são locais uns para os outros. Um contêiner em um pod tem o mesmo endereço IP que o outro contêiner porque eles estão compartilhando um namespace de rede, mas na maioria dos casos, você estará executando em uma base um-a-um, ou seja, um único contêiner por pod. Múltiplos contêineres por pod são usados apenas em cenários muito específicos, como quando uma aplicação requer um ajudante, como um empurrador de dados ou um proxy que precisa se comunicar de forma rápida e resiliente com a aplicação principal.
A maneira como você define um pod é a mesma que você faria para qualquer outro objeto Kubernetes: via um YAML que contém todas as especificações e definições do pod:
kind: PodapiVersion: v1metadata:name: hello-podlabels: hello: podspec: containers: - name: hello-container image: alpine args: - echo - “Hello World”
Vamos passar pelas definições básicas do pod necessárias sob o campo spec para criar nosso pod:
- Containers: Um contêiner é um array; portanto, temos um conjunto de vários subcampos sob ele. Basicamente, é o que define os contêineres que vão estar em execução no pod. Podemos especificar um nome para o contêiner, a imagem da qual ele será um desdobramento e os argumentos ou comandos que precisamos que ele execute. A diferença entre argumentos e comandos é a mesma que a diferença entre CMD e ENTRYPOINT. Note que todos os campos que acabamos de passar são para o array de contêineres. Eles não fazem parte diretamente do spec do pod.
- restartPolicy: Este campo é exatamente isso: ele diz ao Kubernetes o que fazer com um contêiner, e se aplica a todos os contêineres no pod no caso de um código de saída zero ou não zero. Você pode escolher entre as opções, Nunca, Em Falha ou Sempre. Sempre será o padrão caso uma restartPolicy não seja definida.
Essas são as especificações mais básicas que você vai declarar em um pod; outras especificações exigirão que você tenha um pouco mais de conhecimento sobre como usá-las e como elas interagem com vários outros objetos Kubernetes. Vamos revisitá-las mais adiante neste artigo; algumas delas são as seguintes:
- Volume
- Env
- Ports
- dnsPolicy
- initContainers
- nodeSelector
- Limites e solicitações de recursos
Para visualizar os pods que estão atualmente em execução em seu cluster, você pode executar kubectl get pods:
dsala@MININT-IB3HUA8:~$ kubectl get podsNAME READY STATUS RESTARTS AGEbusybox 1/1 Running 120 5d
Alternativamente, você pode executar kubectl describe pods sem especificar nenhum pod. Isso imprimirá uma descrição de cada pod em execução no cluster. Neste caso, será apenas o pod busybox, pois é o único que está atualmente em execução:
dsala@MININT-IB3HUA8:~$ kubectl describe podsName: busyboxNamespace: defaultPriority: 0PriorityClassName:
Os pods são mortais. Uma vez que morrem ou são excluídos, não podem ser recuperados. Seu IP e os contêineres que estavam em execução nele desaparecerão; eles são totalmente efêmeros. Os dados nos pods que estão montados como um volume podem ou não sobreviver, dependendo de como você configurou. Se nossos pods morrerem e os perdermos, como garantimos que todos os nossos microsserviços estejam em execução? Bem, implantações são a resposta.
Implantações
Pods por si só não são muito úteis, pois não é muito eficiente ter mais de uma única instância de nossa aplicação em execução em um único pod. Provisionar centenas de cópias de nossa aplicação em diferentes pods sem ter um método para procurá-las todas rapidamente se tornará insustentável muito rapidamente.
É aqui que as implantações entram em cena. Com implantações, podemos gerenciar nossos pods com um controlador. Isso nos permite não apenas decidir quantos queremos executar, mas também gerenciar atualizações alterando a versão da imagem ou a própria imagem que nossos contêineres estão executando. As implantações são com as quais você trabalhará na maior parte do tempo. Com implantações, assim como pods e quaisquer outros objetos que mencionamos antes, eles têm sua própria definição dentro de um arquivo YAML:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deployment labels: deployment: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
Vamos começar a explorar sua definição.
No início do YAML, temos campos mais gerais, como apiVersion, kind e metadata. Mas sob spec é onde encontraremos as opções específicas para este Objeto API.
Sob spec, podemos adicionar os seguintes campos:
Selector: Com o campo Selector, a implantação saberá quais pods direcionar quando as alterações forem aplicadas. Existem dois campos que você usará sob o seletor: matchLabels e matchExpressions. Com matchLabels, o seletor usará os rótulos dos pods (pares chave/valor). É importante notar que todos os rótulos que você especificar aqui serão ANDed. Isso significa que o pod exigirá que tenha todos os rótulos que você especificar sob matchLabels.
Replicas: Isso indicará o número de pods que a implantação precisa manter em execução através do controlador de replicação; por exemplo, se você especificar três réplicas, e um dos pods morrer, o controlador de replicação observará o spec de réplicas como o estado desejado e informará ao agendador para agendar um novo pod, já que o status atual agora é 2, uma vez que o pod morreu.
RevisionHistoryLimit: Cada vez que você faz uma alteração na implantação, essa alteração é salva como uma revisão da implantação, que você pode posteriormente reverter para aquele estado anterior ou manter um registro do que foi alterado. Você pode consultar seu histórico com kubectl rollout history deployment/
Strategy: Isso permitirá que você decida como deseja lidar com qualquer atualização ou escala horizontal de pods. Para sobrescrever o padrão, que é rollingUpdate, você precisa escrever a chave type, onde pode escolher entre dois valores: recreate ou rollingUpdate.
Enquanto recreate é uma maneira rápida de atualizar sua implantação, ele excluirá todos os pods e os substituirá por novos, mas implicará que você terá que considerar que um tempo de inatividade do sistema estará em vigor para esse tipo de estratégia. O rollingUpdate, por outro lado, é mais suave e mais lento e é ideal para aplicações stateful que podem reequilibrar seus dados. O rollingUpdate abre a porta para mais dois campos, que são maxSurge e maxUnavailable.
O primeiro será quantos pods acima do total que você deseja ao realizar uma atualização; por exemplo, uma implantação com 100 pods e um maxSurge de 20% crescerá até um máximo de 120 pods durante a atualização. A próxima opção permitirá que você selecione quantos pods na porcentagem você está disposto a matar para substituí-los por novos em um cenário de 100 pods. Nos casos em que há 20% maxUnavailable, apenas 20 pods serão mortos e substituídos por novos antes de continuar a substituir o restante da implantação.
Template: Este é apenas um campo de especificação de pod aninhado onde você incluirá todas as especificações e metadados dos pods que a implantação irá gerenciar.
Vimos que, com implantações, gerenciamos nossos pods, e elas nos ajudam a mantê-los em um estado que desejamos. Todos esses pods ainda estão em algo chamado rede do cluster, que é uma rede fechada na qual apenas os componentes do cluster Kubernetes podem se comunicar entre si, mesmo tendo seu próprio conjunto de intervalos de IP. Como nos comunicamos com nossos pods do lado de fora? Como chegamos à nossa aplicação? É aqui que os serviços entram em cena.
Serviços:
O nome serviço não descreve totalmente o que os serviços realmente fazem no Kubernetes. Os serviços Kubernetes são o que roteia o tráfego para nossos pods. Podemos dizer que os serviços são o que conecta os pods.
Vamos imaginar que temos um típico aplicativo do tipo frontend/backend onde temos nossos pods frontend se comunicando com nossos pods backend através dos endereços IP dos pods. Se um pod no backend morrer, perderemos a comunicação com nosso backend. Isso não é apenas porque o novo pod não terá o mesmo endereço IP do pod que morreu, mas agora também teremos que reconfigurar nosso aplicativo para usar o novo endereço IP. Esse problema e problemas semelhantes são resolvidos com serviços.
Um serviço é um objeto lógico que diz ao kube-proxy para criar regras iptables com base em quais pods estão atrás do serviço. Os serviços configuram seus pontos finais, que é como os pods atrás de um serviço são chamados, da mesma forma que as implantações sabem quais pods controlar, o campo seletor e os rótulos dos pods.
Este diagrama mostra como os serviços usam rótulos para gerenciar o tráfego:
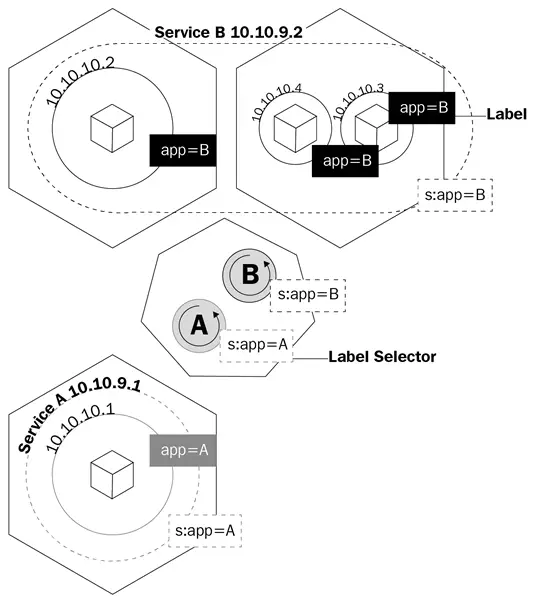
Os serviços não apenas farão com que o kube-proxy crie regras para rotear o tráfego; também acionará algo chamado kube-dns.
Kube-dns é um conjunto de pods com contêineres SkyDNS que são executados no cluster que fornece um servidor DNS e encaminhador, que criará registros para serviços e, às vezes, pods para facilitar o uso. Sempre que você cria um serviço, um registro DNS apontando para o endereço IP interno do cluster do serviço será criado na forma service-name.namespace.svc.cluster.local. Você pode aprender mais sobre as especificações DNS do Kubernetes aqui: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Voltando ao nosso exemplo, agora teremos que configurar nosso aplicativo para se comunicar com o nome de domínio totalmente qualificado (FQDN) do serviço para se comunicar com nossos pods backend. Dessa forma, não importará qual endereço IP os pods e serviços têm. Se um pod atrás do serviço morrer, o serviço cuidará de tudo usando o registro A, pois seremos capazes de dizer ao nosso frontend para rotear todo o tráfego para my-svc. A lógica do serviço cuidará de todo o resto.
Existem vários tipos de serviço que você pode criar sempre que estiver declarando o objeto a ser criado no Kubernetes. Vamos passar por eles para ver qual será o mais adequado para o tipo de trabalho que precisamos:
ClusterIP: Este é o serviço padrão. Sempre que você cria um serviço ClusterIP, ele criará um serviço com um endereço IP interno do cluster que só será roteável dentro do cluster Kubernetes. Este tipo é ideal para pods que precisam apenas se comunicar entre si e não sair do cluster.
NodePort: Quando você cria esse tipo de serviço, por padrão, uma porta aleatória de 30000 a 32767 será alocada para encaminhar tráfego para os pods de ponto final do serviço. Você pode substituir esse comportamento especificando uma porta de nó no array de portas. Uma vez que isso esteja definido, você poderá acessar seus pods através de
LoadBalancer: Na maioria das vezes, você estará executando o Kubernetes em um provedor de nuvem. O tipo LoadBalancer é ideal para essas situações, pois você poderá alocar endereços IP públicos para seu serviço através da API do seu provedor de nuvem. Este é o serviço ideal quando você deseja se comunicar com seus pods do lado de fora do seu cluster. Com LoadBalancer, você poderá não apenas alocar um endereço IP público, mas também, usando o Azure, alocar um endereço IP privado da sua rede privada virtual. Assim, você pode se comunicar com seus pods pela internet ou internamente na sua sub-rede privada.
Vamos revisar a definição YAML de um serviço:
apiVersion: v1kind: Servicemetadata: name: my-servicespec: selector: app: front-end type: NodePort ports: - name: http port: 80 targetPort: 8080 nodePort: 30024 protocol: TCP
O YAML de um serviço é muito simples, e as especificações variarão, dependendo do tipo de serviço que você está criando. Mas a coisa mais importante que você deve levar em conta são as definições de porta. Vamos dar uma olhada nelas:
- port: Esta é a porta do serviço que está exposta
- targetPort: Esta é a porta nos pods para onde o serviço está enviando tráfego
- nodePort: Esta é a porta que será exposta
Embora agora entendamos como podemos nos comunicar com os pods em nosso cluster, ainda precisamos entender como vamos gerenciar o problema de perder nossos dados toda vez que um pod é encerrado. É aqui que os Volumes Persistentes (PV) entram em uso.
Kubernetes e armazenamento persistente
O armazenamento persistente no mundo dos contêineres é um problema sério. O único armazenamento que é persistente entre as execuções de contêiner é as camadas da imagem, e elas são somente leitura. A camada onde o contêiner é executado é leitura/escrita, mas todos os dados nessa camada são excluídos assim que o contêiner para. Com os pods, isso é o mesmo. Quando um contêiner morre, os dados gravados nele desaparecem.
O Kubernetes possui um conjunto de objetos para lidar com armazenamento entre pods. O primeiro que vamos discutir são volumes.
Volumes
Volumes resolvem um dos maiores problemas quando se trata de armazenamento persistente. Primeiro de tudo, volumes não são realmente objetos, mas uma definição do spec de um pod. Quando você cria um pod, pode definir um volume sob o campo spec do pod. Contêineres nesse pod poderão montar o volume em seu namespace de montagem, e o volume estará disponível entre reinicializações ou falhas de contêiner. No entanto, os volumes estão ligados aos pods, e se o pod for excluído, o volume também desaparecerá. A persistência dos dados no volume é outra história; a persistência dos dados dependerá do backend desse volume.
O Kubernetes suporta vários tipos de volumes ou fontes de volume e como são chamados nas especificações da API, que vão desde mapeamentos de sistema de arquivos do nó local, discos virtuais de provedores de nuvem e volumes baseados em armazenamento definido por software. Montagens de sistema de arquivos locais são as mais comuns que você verá quando se trata de volumes regulares. É importante notar que a desvantagem de usar o sistema de arquivos do nó local é que os dados não estarão disponíveis em todos os nós do cluster, apenas naquele nó onde o pod foi agendado.
Vamos examinar como um pod com um volume é definido em YAML:
apiVersion: v1kind: Podmetadata: name: test-pdspec: containers: - image: k8s.gcr.io/test-webserver name: test-container volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: path: /data type: Directory
Note como há um campo chamado volumes sob spec e depois há outro chamado volumeMounts.
O primeiro campo (volumes) é onde você define o volume que deseja criar para aquele pod. Este campo sempre exigirá um nome e, em seguida, uma fonte de volume. Dependendo da fonte, os requisitos serão diferentes. Neste exemplo, a fonte seria hostPath, que é o sistema de arquivos local de um nó. hostPath suporta vários tipos de mapeamentos, que vão desde diretórios, arquivos, dispositivos de bloco e até mesmo soquetes Unix.
Sob o segundo campo, volumeMounts, temos mountPath, que é onde você define o caminho dentro do contêiner onde deseja montar seu volume. O parâmetro name é como você especifica ao pod qual volume usar. Isso é importante porque você pode ter vários tipos de volumes definidos sob volumes, e o nome será a única maneira para o pod saber qual
Você pode aprender mais sobre os diferentes tipos de volumes aqui https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes e no documento de referência da API do Kubernetes ( https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.11/#volume-v1-core).
Ter volumes que morrem com os pods não é ideal. Precisamos de armazenamento que persista, e é assim que surgiu a necessidade de PVs.
Volumes Persistentes, Reclamações de Volumes Persistentes e Classes de Armazenamento
A principal diferença entre volumes e PVs é que, ao contrário dos volumes, os PVs são realmente objetos da API do Kubernetes, então você pode gerenciá-los individualmente como entidades separadas, e, portanto, eles persistem mesmo após um pod ser excluído.
Você pode estar se perguntando por que esta subseção tem PV, reclamações de volumes persistentes (PVCs) e classes de armazenamento misturadas. Isso ocorre porque todos eles dependem uns dos outros, e é crucial entender como eles interagem entre si para provisionar armazenamento para nossos pods.
Vamos começar com PVs e PVCs. Assim como os volumes, os PVs têm uma fonte de armazenamento, então o mesmo mecanismo que os volumes têm se aplica aqui. Você terá um cluster de armazenamento definido por software fornecendo um número lógico de unidade (LUN), um provedor de nuvem fornecendo discos virtuais ou até mesmo um sistema de arquivos local para o nó Kubernetes, mas aqui, em vez de serem chamados fontes de volume, eles são chamados de tipos de volume persistente.
Os PVs são praticamente como LUNs em uma matriz de armazenamento: você os cria, mas sem um mapeamento; eles são apenas um monte de armazenamento alocado esperando para ser usado. Os PVCs são como mapeamentos de LUN: eles são vinculados ou associados a um PV e também são o que você realmente define, relaciona e torna disponível para o pod que pode então usá-lo para seus contêineres.
A maneira como você usa PVCs em pods é exatamente a mesma que com volumes normais. Você tem dois campos: um para especificar qual PVC deseja usar e o outro para dizer ao pod em qual contêiner usar aquele PVC.
O YAML para uma definição de objeto API PVC deve ter o seguinte código:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: gluster-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi
O YAML para o pod deve ter o seguinte código:
kind: PodapiVersion: v1metadata: name: mypodspec: containers: - name: myfrontend image: nginx volumeMounts: - mountPath: “/mnt/gluster” name: volume volumes: - name: volume persistentVolumeClaim: claimName: gluster-pvc
Quando um administrador do Kubernetes cria um PVC, existem duas maneiras que esse pedido é satisfeito:
- Estático: Vários PVs já foram criados, e então, quando um usuário cria um PVC, qualquer PV disponível que possa satisfazer os requisitos será vinculado a esse PVC.
- Dinâmico: Alguns tipos de PV podem criar PVs com base nas definições de PVC. Quando um PVC é criado, o tipo de PV criará dinamicamente um objeto PV e alocará o armazenamento no backend; isso é provisionamento dinâmico. O detalhe do provisionamento dinâmico é que você requer um terceiro tipo de objeto de armazenamento do Kubernetes, chamado classe de armazenamento.
As classes de armazenamento são como uma maneira de classificar seu armazenamento. Você pode criar uma classe que provisiona volumes de armazenamento lentos, ou outra com discos SSD hiper-rápidos. No entanto, as classes de armazenamento são um pouco mais complexas do que apenas classificação. Como mencionamos nas duas maneiras de criar PVC, as classes de armazenamento são o que torna o provisionamento dinâmico possível. Ao trabalhar em um ambiente de nuvem, você não quer estar criando manualmente cada disco de backend para cada PV. As classes de armazenamento configurarão algo chamado provisionador, que invoca o plug-in de volume que é necessário para se comunicar com a API do seu provedor de nuvem. Cada provisionador tem suas próprias configurações para que possa se comunicar com o provedor de nuvem ou provedor de armazenamento especificado.
Você pode provisionar classes de armazenamento da seguinte maneira; este é um exemplo de uma classe de armazenamento usando Azure-disk como um provisionador de disco:
kind: StorageClassapiVersion: storage.k8s.io/v1metadata: name: my-storage-classprovisioner: kubernetes.io/azure-diskparameters: storageaccounttype: Standard_LRS kind: Shared
Cada provisionador de classe de armazenamento e tipo de PV terá requisitos e parâmetros diferentes, assim como volumes, e já tivemos uma visão geral de como eles funcionam e para que podemos usá-los. Aprender sobre classes de armazenamento específicas e tipos de PV dependerá do seu ambiente; você pode aprender mais sobre cada um deles clicando nos seguintes links:
- https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner
- https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
Neste artigo, aprendemos sobre o que é o Kubernetes, seus componentes e quais são as vantagens de usar a orquestração. Com isso, identificar cada um dos objetos da API do Kubernetes, seu propósito e seus casos de uso deve ser fácil. Agora você deve ser capaz de entender como os nós mestres controlam o cluster e o agendamento dos contêineres nos nós trabalhadores.
Se você achou este artigo útil, ‘ Hands-On Linux for Architects ’ deve ser útil para você. Com este livro, você cobrirá tudo, desde componentes e funcionalidades do Linux até suporte de hardware e software, o que ajudará você a implementar e ajustar soluções baseadas em Linux eficazes. Você será guiado por uma visão geral da metodologia de design do Linux e dos conceitos centrais de design de uma solução. Se você é um administrador de sistema Linux, engenheiro de suporte Linux, engenheiro DevOps, consultor Linux ou qualquer pessoa que procura aprender ou expandir seu conhecimento em arquitetura, este livro é para você.
Receba novas postagens na sua caixa de entrada
Sem spam. Cancele a assinatura a qualquer momento.