Alta Disponibilidade · 12 min read · Nov 10, 2025
Como implantar um cluster tolerante a falhas com disponibilidade contínua ou alta disponibilidade
Algumas empresas não podem permitir que seus serviços fiquem fora do ar. Em caso de uma falha no servidor, um operador de celular pode experimentar a inatividade do sistema de cobrança, causando perda de conexão para todos os seus clientes. A admissão do impacto potencial de tais situações leva à ideia de sempre ter um plano B.
Neste artigo, estamos esclarecendo diferentes maneiras de proteção contra falhas de servidor, bem como arquiteturas usadas para a implantação do VMmanager Cloud, um painel de controle para construir um cluster de Alta Disponibilidade.

Prefácio
A terminologia na área de tolerância a clusters difere de site para site. Para evitar a mistura de diferentes termos e definições, vamos delinear os que serão usados no artigo:
- Tolerância a Falhas (FT) é a capacidade de um sistema de continuar sua operação após a falha de um de seus componentes.
- Cluster é um grupo de servidores (nós do cluster) conectados através de canais de comunicação.
- Cluster Tolerante a Falhas (FTC) é um cluster onde a falha de um servidor não resulta na indisponibilidade completa de todo o cluster. As funções do nó falhado são automaticamente reatribuídas entre os nós restantes.
- Disponibilidade Contínua (CA) significa que um usuário pode utilizar o serviço sem experimentar qualquer tempo de inatividade. Não importa quanto tempo passou desde que o nó falhou.
- Alta Disponibilidade (HA) significa que um usuário pode experimentar tempos de inatividade do serviço caso um dos nós fique fora do ar; no entanto, o sistema será recuperado automaticamente com o mínimo de inatividade.
- Cluster CA é um cluster de Disponibilidade Contínua.
- Cluster HA é um cluster de Alta Disponibilidade.
Suponha que seja necessário implantar um cluster consistindo de 10 nós com máquinas virtuais rodando em cada nó. O objetivo é proteger as máquinas virtuais após a falha do servidor. Servidores com CPU dupla são usados para maximizar a densidade de cálculo dos racks.
À primeira vista, a opção mais atraente para uma empresa é implantar um cluster de Disponibilidade Contínua quando um serviço ainda é fornecido após a falha do equipamento. De fato, a Disponibilidade Contínua é imprescindível se você precisar manter a operação de um sistema de cobrança ou automatizar um processo de produção contínuo. No entanto, essa abordagem também tem suas armadilhas e armadilhas que são abordadas abaixo.
Disponibilidade Contínua
A continuidade de um serviço só é viável se uma cópia exata de uma máquina física ou virtual com esse serviço for construída, que esteja disponível a qualquer momento. Esse modelo de redundância é chamado de 2N. Criar uma cópia do servidor após a falha do equipamento levaria tempo, causando tempo de inatividade do serviço. Além disso, nesse caso, não seria possível recuperar o despejo de RAM do servidor falhado, o que significa que todas as informações contidas ali estariam perdidas.
Existem dois métodos usados para fornecer CA: em uma camada de hardware e em uma camada de software. Vamos nos concentrar em cada um deles em maior detalhe.
O método de hardware representa um servidor duplo onde todos os componentes são duplicados e os cálculos são executados simultaneamente e de forma independente. A sincronização é alcançada usando um nó dedicado que verifica os resultados provenientes de ambas as partes. Se o nó detectar qualquer discrepância, ele tenta definir o problema e corrigir os erros. Se o erro não puder ser corrigido, o sistema desliga o módulo falhado.
A Stratus, um fabricante de servidores CA, garante que o tempo total de inatividade do sistema não exceda 32 segundos por ano. Esses resultados podem ser alcançados usando equipamentos especiais. De acordo com representantes da Stratus, o custo de um servidor CA com CPUs duplas para cada módulo sincronizado é de cerca de $160.000, dependendo das especificações. O preço total para todo o cluster CA, nesse caso, seria de $1.600.000.
O método de software
A ferramenta de software mais popular para a implantação de um cluster de Disponibilidade Contínua no momento do artigo é o VMware vSphere. A tecnologia de Disponibilidade Contínua deste produto é chamada de Tolerância a Falhas.
Ao contrário do método de hardware, essa tecnologia tem certos requisitos, como os seguintes:
- CPU no host físico: - Intel com arquitetura Sandy Bridge (ou mais recente). Avoton não é suportado.
- AMD Bulldozer (ou mais recente).
- Máquinas com Tolerância a Falhas devem estar conectadas a uma rede de 10 Gb com baixa latência. A VMware recomenda fortemente o uso de uma rede dedicada.
- Não mais que 4 CPUs virtuais por VM.
- Não mais que 8 CPUs virtuais por host físico.
- Não mais que 4 máquinas virtuais por host físico.
- Capturas de máquina virtual não estão disponíveis.
- Storage vMotion não está disponível.
A lista completa de limitações e incompatibilidades pode ser encontrada na documentação oficial.
A licença do vSphere é baseada em CPUs físicas. O preço começa em $1750 por licença + $550 para assinatura anual e suporte. A automação da gestão do cluster também requer o VMware vCenter Server, que custa mais de $8000. O modelo 2N é usado para fornecer Disponibilidade Contínua, portanto, é necessário comprar 10 servidores replicados com licenças para cada um deles a fim de construir um cluster com 10 nós com máquinas virtuais.
O custo total do software seria 2[ Número de CPUs por servidor ](10[ Número de nós com máquinas virtuais ]+10[ Número de nós replicados ])(1750+550)[ Custo da licença por cada CPU ]+8000[ Custo do VMware vCenter Server ]=$100.000. Todos os preços são arredondados.
Configurações específicas de nós não são descritas neste artigo, pois os componentes do servidor sempre diferem dependendo do propósito do cluster. O equipamento de rede também não é descrito, pois deve ser idêntico em todos os casos. Este artigo se concentra naqueles componentes que definitivamente variariam, que é o custo da licença.
É também importante mencionar os produtos que não estão mais em desenvolvimento e suporte.
O produto chamado Remus é baseado na virtualização Xen. É uma solução gratuita de código aberto que utiliza a tecnologia de micro snapshot. Infelizmente, sua documentação não foi atualizada há muito tempo: O guia de instalação fornece instruções para Ubuntu 12.10, cujo fim de vida foi anunciado em 2014. Mesmo a busca no Google não encontrou nenhuma empresa que estivesse usando o Remus para suas operações.
Foram feitas tentativas de modificar o QEMU para construir clusters de Disponibilidade Contínua com essa tecnologia. Existem dois projetos que anunciaram seu trabalho nessa direção.
O primeiro é o Kemari, um produto de código aberto liderado por Yoshiaki Tamura. Este projeto pretendia usar migração ao vivo do QEMU. O último commit foi feito em fevereiro de 2011, o que sugere que o desenvolvimento chegou a um impasse e não será continuado.
O segundo produto é o Micro Checkpointing, um projeto de código aberto fundado por Michael Hines. Nenhuma atividade foi encontrada em seu changelog no último ano, o que se assemelha ao projeto Kemari.
Esses fatos nos permitem concluir que simplesmente não há possibilidade de Disponibilidade Contínua na virtualização KVM até a presente data.
Apesar de todas as vantagens dos sistemas de Disponibilidade Contínua, existem muitos impedimentos para implantar e operar tais soluções. No entanto, em alguns casos, a Tolerância a Falhas pode ser necessária, mas sem a necessidade de estar continuamente disponível. Esses cenários permitem o uso de clusters com Alta Disponibilidade.
Alta Disponibilidade
Um cluster de Alta Disponibilidade fornece Tolerância a Falhas detectando automaticamente se o hardware está fora do ar e, subsequentemente, lançando o serviço no nó disponível.
A Alta Disponibilidade não suporta a sincronização de CPUs lançadas em nós e nem sempre permite sincronizar discos locais. Com isso em mente, é recomendado localizar os drives usados pelos nós em um armazenamento independente separado, como o armazenamento em rede.
A razão é clara: O nó não pode ser alcançado após sua falha, e as informações de seu dispositivo de armazenamento não podem ser recuperadas. O sistema de armazenamento de dados também deve ser tolerante a falhas, caso contrário, não há possibilidade de Alta Disponibilidade. Como resultado, o cluster de Alta Disponibilidade consiste em dois sub-clusters:
- Cluster de computação consistindo em nós com máquinas virtuais
- Cluster de armazenamento com discos que são usados pelos nós de computação.
No momento, existem as seguintes soluções usadas para implementar clusters de Alta Disponibilidade com máquinas virtuais em nós de cluster:
- Heartbeat, versão 1.? com DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Windows Server Failover Clustering com função de servidor Hyper-V;
- VMmanager Cloud.
Vamos dar uma olhada mais de perto no VMmanager Cloud.
VMmanager Cloud
VMmanager Cloud é um produto que permite implantar clusters de Alta Disponibilidade e usa virtualização QEMU-KVM. Esta tecnologia foi selecionada porque está ativamente desenvolvida e suportada e permite instalar qualquer sistema operacional em uma máquina virtual. O produto usa Corosync para detectar a disponibilidade do cluster. Se um dos servidores estiver fora do ar, o VMmanager distribui suas máquinas virtuais entre os nós restantes uma a uma.
De forma simplificada, esse mecanismo funciona da seguinte maneira:
- O sistema identifica o nó do cluster com o menor número de máquinas virtuais.
- Ele verifica se há RAM suficiente para alocar a máquina.
- Se houver memória suficiente em um nó para a máquina pertinente, o VMmanager cria uma nova máquina virtual nesse nó.
- Se não houver memória suficiente, o sistema verifica os outros nós com mais máquinas virtuais.
Testando algumas configurações de hardware e consultando muitos usuários atuais do VMmanager Cloud, identificou-se que normalmente leva de 45 a 90 segundos para distribuir e restaurar a operação de todas as VMs do nó falhado, dependendo do desempenho do equipamento.
Recomenda-se dedicar um ou alguns nós como uma salvaguarda contra situações de emergência e não implantar VMs nesses nós durante a operação rotineira. Isso minimiza as chances de falta de recursos nos nós do cluster ativo para adicionar máquinas virtuais do nó falhado. Caso apenas um nó de backup seja usado, esse modelo de segurança é chamado de N+1.
O VMmanager Cloud suporta os seguintes tipos de armazenamento: sistema de arquivos, LVM, Network LVM, iSCSI e Ceph [em particular RBD (RADOS Block Device), uma das implementações do Ceph]. Os três últimos são usados para Alta Disponibilidade.
Uma licença vitalícia para dez nós operacionais e um nó de backup custa €3520, ou $3865 até a presente data (uma licença custa €320 por nó, independentemente do número de CPUs). A licença inclui um ano de atualizações gratuitas; a partir do segundo ano, as atualizações são fornecidas por meio de um modelo de assinatura ao preço de €880 por ano para todo o cluster.
Vamos verificar como o VMmanager Cloud já foi usado para a implantação de clusters de Alta Disponibilidade.
FirstByte
A FirstByte começou a fornecer hospedagem em nuvem em fevereiro de 2016. Inicialmente, seu cluster foi construído no OpenStack; no entanto, a falta de especialistas para esse sistema em termos de disponibilidade e custo os impediu de procurar uma solução alternativa. O novo sistema para construir um cluster de Alta Disponibilidade deveria atender aos seguintes requisitos:
- Capacidade de implantar máquinas virtuais KVM.
- Integração com Ceph.
- Integração com um sistema de cobrança para oferecer os serviços existentes.
- Custo de licença acessível.
- Suporte do desenvolvedor de software.
O VMmanager Cloud atendeu a todos os requisitos.
Características distintivas do cluster FirstByte:
- A transferência de dados é baseada na tecnologia Ethernet e equipamentos Cisco.
- O roteamento é realizado usando Cisco ASR9001. O cluster utiliza cerca de 50000 endereços IPv6.
- A velocidade de link entre nós de computação e switches é de 10 Gbps.
- A velocidade de transferência de dados entre switches e nós de armazenamento é de 20 Gbps, com dois canais combinados de 10 Gbps cada.
- Um link separado de 20 Gbps é usado entre racks com nós de armazenamento para replicação.
- Discos SAS em combinação com SSDs estão instalados em todos os nós de armazenamento.
- O tipo de armazenamento é RBD.
O layout do sistema é apresentado abaixo:
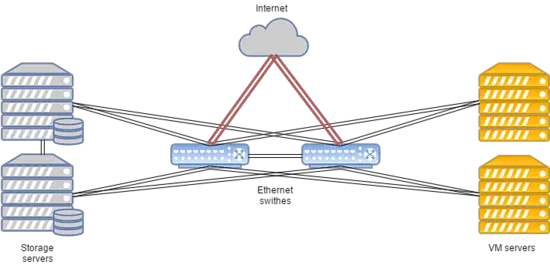
Essa configuração funciona para hospedar sites populares, servidores de jogos e bancos de dados com carga acima da média.
FirstVDS
A FirstVDS fornece os serviços de cluster tolerante a falhas que foi iniciado em setembro de 2015.
O VMmanager Cloud foi escolhido para este cluster devido aos seguintes fatores:
- Sólida experiência no uso de painéis de controle ISPsystem.
- Integração com BILLmanager por padrão.
- Alta qualidade do suporte técnico.
- Integração com Ceph.
O cluster deles possui as seguintes características:
- A transferência de dados é baseada na rede Infiniband com velocidade de conexão de 56 Gbps;
- A rede Infiniband é construída com equipamentos Mellanox;
- Os nós de armazenamento possuem drives SSD;
- O tipo de armazenamento é RBD.
O sistema pode ser disposto da seguinte maneira:
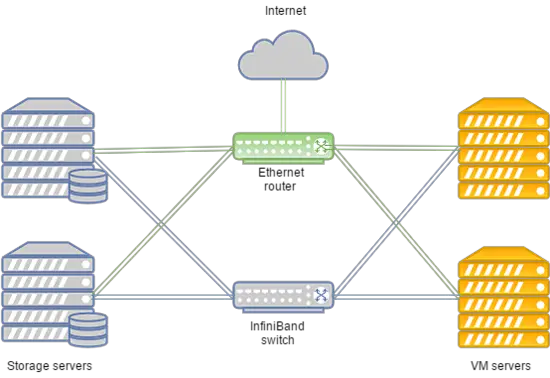
Em caso de falha na rede Infiniband, a conexão entre o armazenamento de disco VM e os servidores de computação é estabelecida por meio da rede Ethernet implantada em equipamentos Juniper. A nova conexão é configurada automaticamente.
Devido à alta velocidade de comunicação com o armazenamento, esse cluster funciona perfeitamente para hospedar sites com tráfego ultralto, streaming de vídeo e conteúdo, bem como grandes volumes de dados.
Conclusão
Vamos resumir as principais conclusões do artigo.
O cluster de Disponibilidade Contínua é imprescindível quando cada segundo de inatividade traz perdas substanciais. Se for permitido ter uma interrupção de 5 minutos enquanto as máquinas virtuais estão sendo implantadas em um nó de backup, o cluster de Alta Disponibilidade pode ser uma boa opção para reduzir custos de hardware e software.
É também importante lembrar que a única maneira de alcançar a Tolerância a Falhas é a excessividade. Certifique-se de replicar seus servidores, equipamentos de comunicação de dados e links, canais de acesso à Internet e energia. Replicar tudo o que você puder. Essas medidas tornam possível eliminar gargalos e pontos potenciais de falha que podem causar a inatividade de todo o sistema. Ao tomar as medidas acima, você pode ter certeza de que possui um cluster tolerante a falhas resistente a falhas.
Se você acha que o modelo de Alta Disponibilidade se encaixa em seus requisitos e o VMmanager Cloud é uma boa ferramenta para realizá-lo, consulte o manual de instalação e a documentação para saber mais sobre o sistema. Desejo a você operações sem falhas e contínuas!**
Receba novas postagens na sua caixa de entrada
Sem spam. Cancele a assinatura a qualquer momento.