Hadoop Ubuntu · 11 min read · Dec 21, 2025
Como Instalar o Apache Hadoop no Ubuntu 22.04

Apache Hadoop é um framework de código aberto para processamento e armazenamento de grandes dados. Nas indústrias de hoje, o Hadoop se tornou o framework padrão para grandes dados. O Hadoop é projetado para ser executado em sistemas distribuídos com centenas ou até milhares de computadores agrupados ou servidores dedicados. Com isso em mente, o Hadoop pode lidar com grandes conjuntos de dados com alto volume e complexidade, tanto para dados estruturados quanto não estruturados.
Cada implantação do Hadoop contém os seguintes componentes:
- Hadoop Common: As utilidades comuns que suportam os outros módulos do Hadoop.
- Hadoop Distributed File System (HDFS): Um sistema de arquivos distribuído que fornece acesso de alta taxa a dados de aplicativos.
- Hadoop YARN: Um framework para agendamento de tarefas e gerenciamento de recursos do cluster.
- Hadoop MapReduce: Um sistema baseado em YARN para processamento paralelo de grandes conjuntos de dados.
Neste tutorial, instalaremos a versão mais recente do Apache Hadoop em um servidor Ubuntu 22.04. O Hadoop será instalado em um servidor de nó único e criaremos um Modo Pseudo-Distribuído de implantação do Hadoop.
Pré-requisitos
Para completar este guia, você precisará dos seguintes requisitos:
- Um servidor Ubuntu 22.04 - Este exemplo usa um servidor Ubuntu com nome de host ‘hadoop’ e endereço IP ‘192.168.5.100’.
- Um usuário não-root com privilégios de administrador sudo/root.
Instalando o Java OpenJDK
O Hadoop é um grande projeto sob a Apache Software Foundation, e é principalmente escrito em Java. No momento da redação deste documento, a versão mais recente do Hadoop é v3.3.4, que é totalmente compatível com o Java v11.
O Java OpenJDK 11 está disponível por padrão no repositório do Ubuntu, e você o instalará via APT.
Para começar, execute o comando apt abaixo para atualizar e atualizar as listas/repositórios de pacotes em seu sistema Ubuntu.
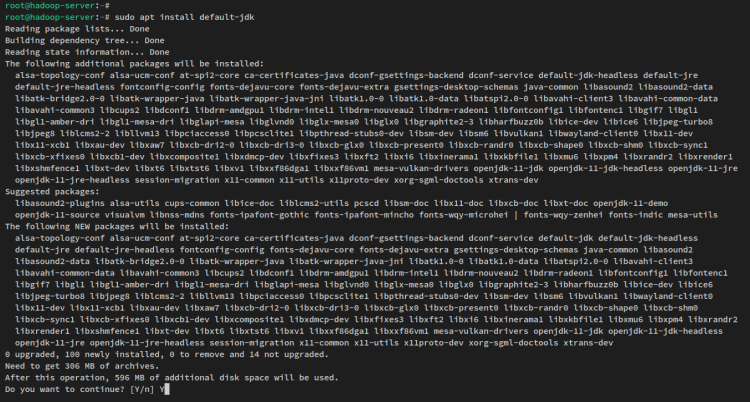
sudo apt updateAgora instale o Java OpenJDK 11 via o comando apt abaixo. No repositório do Ubuntu 22.04, o pacote ‘default-jdk’ refere-se ao Java OpenJDK v11.
sudo apt install default-jdkQuando solicitado, insira y para confirmar e pressione ENTER para prosseguir. E a instalação do Java OpenJDK começará.
Após a instalação do Java, execute o comando abaixo para verificar a versão do Java. Você deve obter o Java OpenJDK 11 instalado em seu sistema Ubuntu.
java -versionAgora que o Java OpenJDK está instalado, você configurará um novo usuário com autenticação SSH sem senha que será usado para executar processos e serviços do Hadoop.
Configurando usuário e Autenticação SSH sem Senha
O Apache Hadoop requer que o serviço SSH esteja em execução no sistema. Isso será usado pelos scripts do Hadoop para gerenciar o daemon remoto do Hadoop no servidor remoto. Nesta etapa, você criará um novo usuário que será usado para executar processos e serviços do Hadoop e, em seguida, configurará a autenticação SSH sem senha.
Caso você não tenha o SSH instalado em seu sistema, execute o comando apt abaixo para instalar o SSH. O pacote ‘pdsh‘ é um cliente de shell remoto multithread que permite executar comandos em vários hosts em modo paralelo.
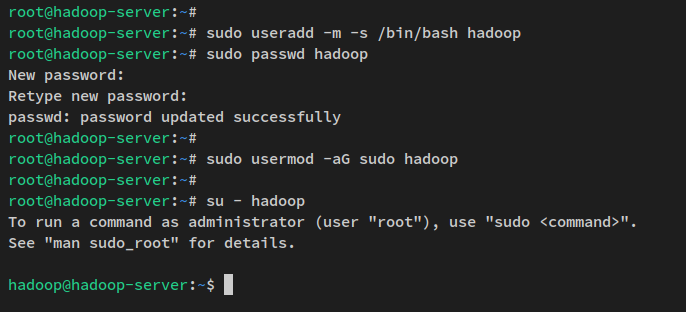
sudo apt install openssh-server openssh-client pdshAgora execute o comando abaixo para criar um novo usuário ‘hadoop’ e configurar a senha para o usuário ‘hadoop’.
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoopInsira a nova senha para o usuário ‘hadoop‘ e repita a senha.
Em seguida, adicione o usuário ‘hadoop’ ao grupo ‘sudo‘ via o comando usermod abaixo. Isso permite que o usuário ‘hadoop’ execute o comando ‘sudo’.
sudo usermod -aG sudo hadoopAgora que o usuário ‘hadoop’ foi criado, faça login no usuário ‘hadoop‘ via o comando abaixo.
su - hadoopApós fazer login, seu prompt se tornará assim: “hadoop@hostname..“.
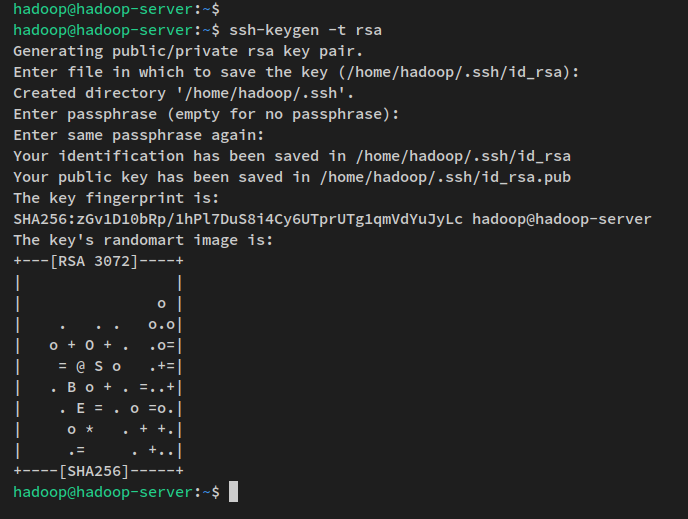
Em seguida, execute o comando abaixo para gerar a chave pública e privada SSH. Quando solicitado a configurar a senha para a chave, pressione ENTER para pular.
ssh-keygen -t rsaA chave SSH agora é gerada no diretório ~/.ssh. O id_rsa.pub é a chave pública SSH e o arquivo ‘id_rsa’ é a chave privada.
Você pode verificar a chave SSH gerada via o seguinte comando.
ls ~/.ssh/Em seguida, execute o comando abaixo para copiar a chave pública SSH ‘id_rsa.pub‘ para o arquivo ‘authorized_keys‘ e alterar a permissão padrão para 600.
No SSH, o arquivo ‘authorized_keys‘ é onde você armazena a chave pública SSH, que pode conter várias chaves públicas. Qualquer um com a chave pública armazenada no arquivo ‘authorized_keys‘ e com a chave privada correta poderá se conectar ao servidor como um usuário ‘hadoop‘ sem uma senha.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys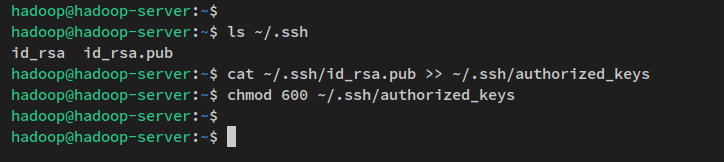
Com a configuração SSH sem senha concluída, você pode verificar conectando-se à máquina local via o comando ssh abaixo.
ssh localhostInsira yes para confirmar e adicionar a impressão digital SSH e você estará conectado ao servidor sem autenticação por senha.
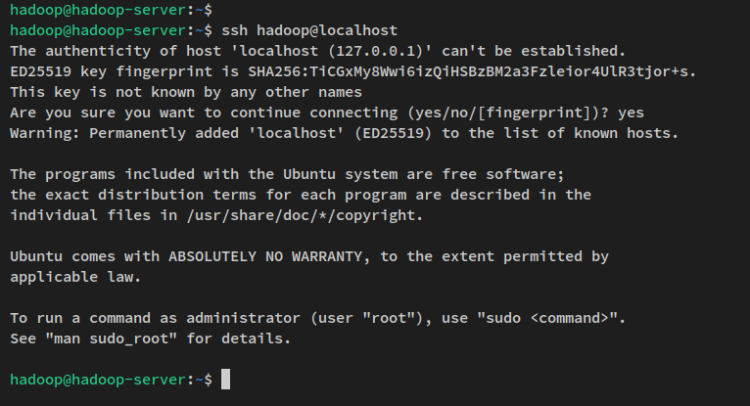
Agora que o usuário ‘hadoop‘ foi criado e a autenticação SSH sem senha configurada, você irá prosseguir com a instalação do Hadoop baixando o pacote binário do Hadoop.
Baixando o Hadoop
Após criar um novo usuário e configurar a autenticação SSH sem senha, você pode agora baixar o pacote binário do Apache Hadoop e configurar o diretório de instalação para ele. Neste exemplo, você baixará o Hadoop v3.3.4 e o diretório de instalação alvo será o diretório ‘/usr/local/hadoop‘.
Execute o comando wget abaixo para baixar o pacote binário do Apache Hadoop para o diretório de trabalho atual. Você deve obter o arquivo ‘hadoop-3.3.4.tar.gz‘ em seu diretório de trabalho atual.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gzEm seguida, extraia o pacote Apache Hadoop ‘hadoop-3.3.4.tar.gz’ via o comando tar abaixo. Depois, mova o diretório extraído para ‘/usr/local/hadoop‘.
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoopPor último, altere a propriedade do diretório de instalação do Hadoop ‘/usr/local/hadoop’ para o usuário ‘hadoop‘ e grupo ‘hadoop‘.
sudo chown -R hadoop:hadoop /usr/local/hadoop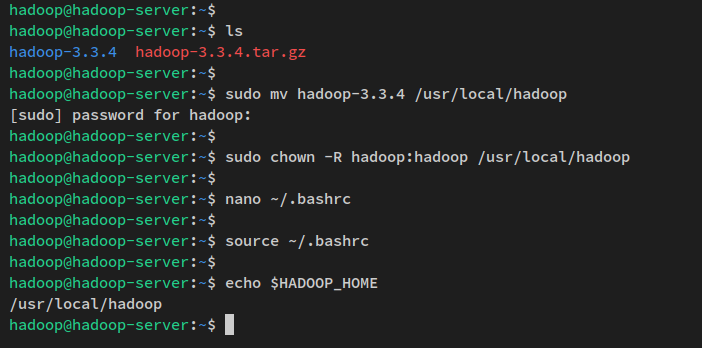
Nesta etapa, você baixou o pacote binário do Apache Hadoop e configurou o diretório de instalação do Hadoop. Com isso em mente, você pode agora começar a configurar a instalação do Hadoop.
Configurando Variáveis de Ambiente do Hadoop
Abra o arquivo de configuração ‘~/.bashrc‘ via o comando do editor nano abaixo.
nano ~/.bashrcAdicione as seguintes linhas ao arquivo. Certifique-se de colocar as seguintes linhas no final do arquivo.
# Variáveis de ambiente do Hadoop
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Salve o arquivo e saia do editor quando terminar.
Em seguida, execute o comando abaixo para aplicar as novas alterações no arquivo ‘~/.bashrc‘.
source ~/.bashrcApós a execução do comando, as novas variáveis de ambiente serão aplicadas. Você pode verificar verificando cada variável de ambiente via o comando abaixo. E você deve obter a saída de cada variável de ambiente.
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTSEm seguida, você também configurará a variável de ambiente JAVA_HOME no script ‘hadoop-env.sh‘.
Abra o arquivo ‘hadoop-env.sh’ usando o seguinte comando do editor nano. O arquivo ‘hadoop-env.sh’ está disponível no diretório ‘$HADOOP_HOME‘, que se refere ao diretório de instalação do Hadoop ‘/usr/local/hadoop‘.
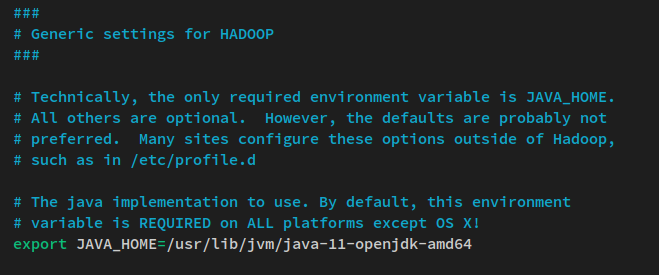
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shDescomente a linha de ambiente JAVA_HOME e altere o valor para o diretório de instalação do Java OpenJDK ‘/usr/lib/jvm/java-11-openjdk-amd64‘.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64Salve o arquivo e saia do editor quando terminar.
Com a configuração das variáveis de ambiente, execute o comando abaixo para verificar a versão do Hadoop em seu sistema. Você deve ver Apache Hadoop 3.3.4 instalado em seu sistema.
hadoop version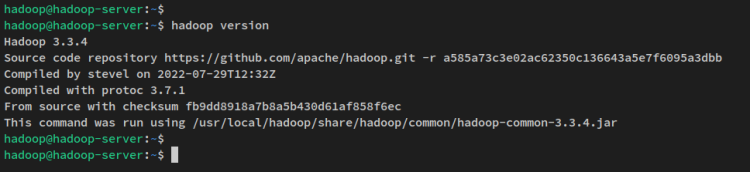
Neste ponto, você está pronto para configurar e configurar o cluster Hadoop, que pode ser implantado em vários modos.
Configurando o Cluster Apache Hadoop: Modo Pseudo-Distribuído
No Hadoop, você pode criar um cluster em três modos diferentes:
- Modo Local (Standalone) - instalação padrão do Hadoop, que é executada como um único processo Java e modo não distribuído. Com isso, você pode facilmente depurar o processo do Hadoop.
- Modo Pseudo-Distribuído - Isso permite que você execute um cluster Hadoop em modo distribuído mesmo com apenas um único nó/servidor. Neste modo, os processos do Hadoop serão executados em processos Java separados.
- Modo Totalmente Distribuído - grande implantação do Hadoop com múltiplos ou até milhares de nós/servidores. Se você deseja executar o Hadoop em produção, deve usar o Hadoop em modo totalmente distribuído.
Neste exemplo, você configurará um cluster Apache Hadoop com modo Pseudo-Distribuído em um único servidor Ubuntu. Para isso, você fará alterações em algumas das configurações do Hadoop:
- core-site.xml - Isso será usado para definir o NameNode para o cluster Hadoop.
- hdfs-site.xml - Esta configuração será usada para definir o DataNode no cluster Hadoop.
- mapred-site.xml - A configuração do MapReduce para o cluster Hadoop.
- yarn-site.xml - Configuração do ResourceManager e NodeManager para o cluster Hadoop.
Configurando NameNode e DataNode
Primeiro, você configurará o NameNode e o DataNode para o cluster Hadoop.
Abra o arquivo ‘$HADOOP_HOME/etc/hadoop/core-site.xml‘ usando o seguinte editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlAdicione as linhas abaixo ao arquivo. Certifique-se de alterar o endereço IP do NameNode, ou você pode substituí-lo por ‘0.0.0.0’ para que o NameNode seja executado em todas as interfaces e endereços IP.
fs.defaultFS
hdfs://192.168.5.100:9000
Salve o arquivo e saia do editor quando terminar.
Em seguida, execute o seguinte comando para criar novos diretórios que serão usados para o DataNode no cluster Hadoop. Depois, altere a propriedade dos diretórios do DataNode para o usuário ‘hadoop‘.
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsDepois disso, abra o arquivo ‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’ usando o comando do editor nano abaixo.
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlAdicione a seguinte configuração ao arquivo. Neste exemplo, você configurará o cluster Hadoop em um único nó, então deve alterar o valor de ‘dfs.replication’ para ‘1’. Além disso, você deve especificar o diretório que será usado para o DataNode.
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
Salve o arquivo e saia do editor quando terminar.
Com o NameNode e o DataNode configurados, execute o comando abaixo para formatar o sistema de arquivos do Hadoop.
hdfs namenode -formatVocê receberá uma saída como esta:
Em seguida, inicie o NameNode e o DataNode via o seguinte comando. O NameNode será executado no endereço IP do servidor que você configurou no arquivo ‘core-site.xml’.
start-dfs.shVocê verá uma saída como esta:
Agora que o NameNode e o DataNode estão em execução, você irá verificar ambos os processos via a interface web.
A interface web do NameNode do Hadoop está rodando na porta ‘9870‘. Portanto, abra seu navegador e visite o endereço IP do servidor seguido pela porta 9870 (ou seja: http://192.168.5.100:9870/).
Você deve agora obter a página como a captura de tela a seguir - O NameNode está atualmente ativo.
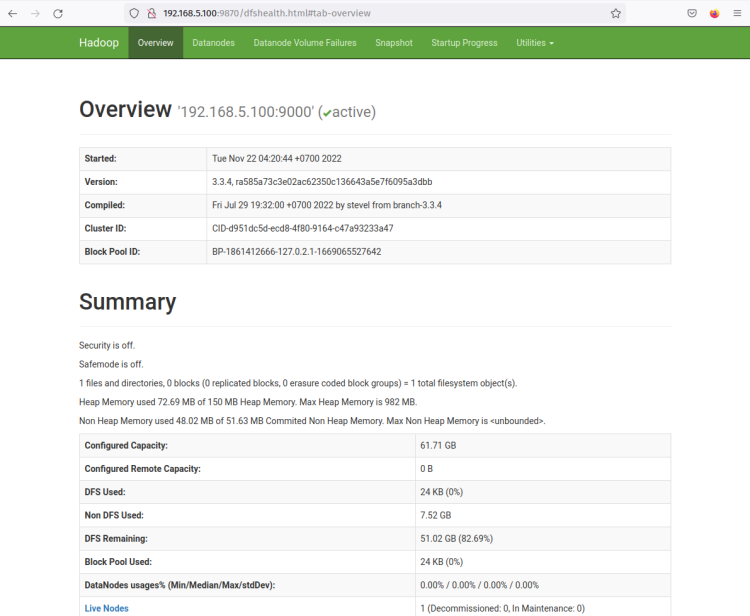
Agora clique no menu ‘Datanodes’ e você deve obter o DataNode atual que está ativo no cluster Hadoop. A captura de tela a seguir confirma que o DataNode está em execução na porta ‘9864‘ no cluster Hadoop.
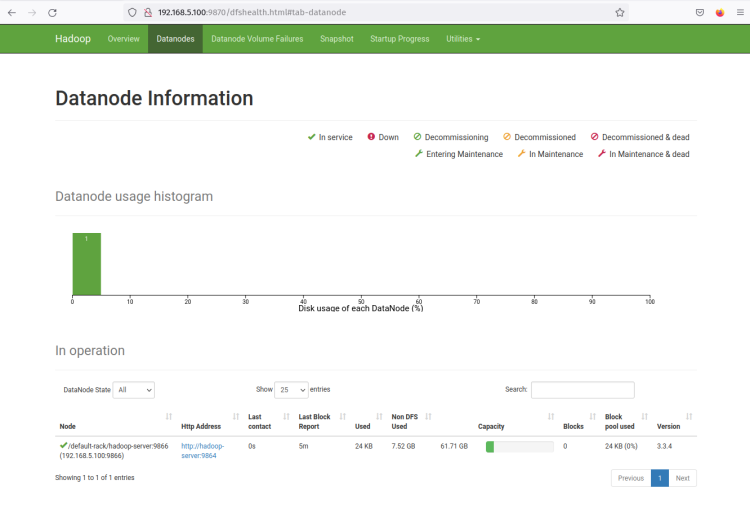
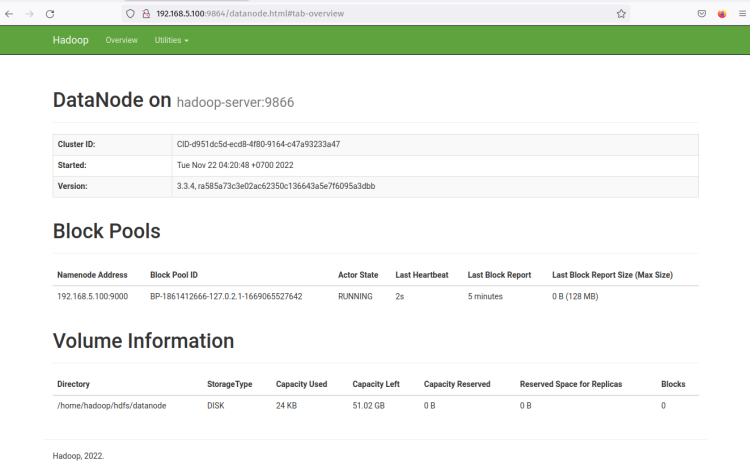
Clique no ‘Endereço Http’ do DataNode ‘*’ e você deve obter uma nova página com informações detalhadas sobre o DataNode. A captura de tela a seguir confirma que o DataNode está em execução com o diretório de volume ‘/home/hadoop/hdfs/datanode*’.
Com o NameNode e o DataNode em execução, você irá configurar e executar o MapReduce no gerenciador Yarn (Yet Another ResourceManager e NodeManager).
Gerenciador Yarn
Para executar um MapReduce no Yarn no modo pseudo-distribuído, você precisa fazer algumas alterações nos arquivos de configuração.
Abra o arquivo ‘$HADOOP_HOME/etc/hadoop/mapred-site.xml‘ usando o seguinte comando do editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlAdicione as linhas abaixo ao arquivo. Certifique-se de alterar o mapreduce.framework.name para ‘yarn’.
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
Salve o arquivo e saia do editor quando terminar.
Em seguida, abra a configuração do Yarn ‘$HADOOP_HOME/etc/hadoop/yarn-site.xml‘ usando o seguinte comando do editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlAltere a configuração padrão com as seguintes configurações.
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
Salve o arquivo e saia do editor quando terminar.
Agora execute o comando abaixo para iniciar os daemons do Yarn. E você deve ver tanto o ResourceManager quanto o NodeManager iniciando.
start-yarn.shO ResourceManager deve estar em execução na porta padrão 8088. Volte ao seu navegador e visite o endereço IP do servidor seguido pela porta do ResourceManager ‘8088’ (ou seja: http://192.168.5.100:8088/).
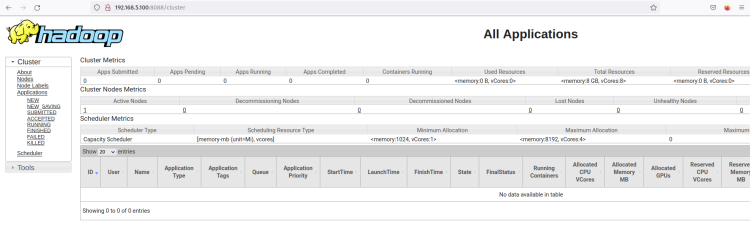
Você deve ver a interface web do ResourceManager do Hadoop. A partir daqui, você pode monitorar todos os processos em execução dentro do cluster Hadoop.
Clique no menu Nós e você deve obter o nó atual em execução no cluster Hadoop.
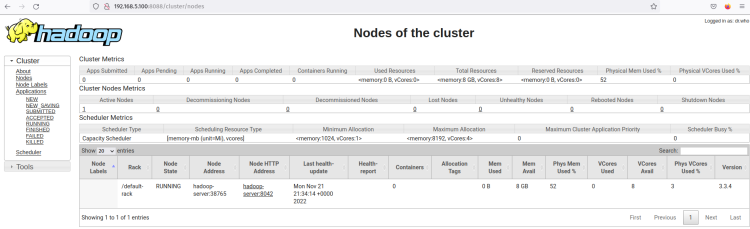
Agora o cluster Hadoop está em execução no modo pseudo-distribuído. Isso significa que cada processo Hadoop está sendo executado como um único processo em um único servidor Ubuntu 22.04, que inclui o NameNode, DataNode, MapReduce e Yarn.
Conclusão
Neste guia, você instalou o Apache Hadoop em um único servidor Ubuntu 22.04. Você instalou o Hadoop com o modo Pseudo-Distribuído habilitado, o que significa que cada componente do Hadoop está sendo executado como um único processo Java no sistema. Neste guia, você também aprendeu como configurar o Java, configurar variáveis de ambiente do sistema e configurar autenticação SSH sem senha via chave pública-privada SSH.
Esse tipo de implantação do Hadoop, modo Pseudo-Distribuído, é recomendado apenas para testes. Se você deseja um sistema distribuído que possa lidar com conjuntos de dados médios ou grandes, pode implantar o Hadoop no modo Clusterizado, que requer mais sistemas de computação e fornece alta disponibilidade para sua aplicação.
Receba novas postagens na sua caixa de entrada
Sem spam. Cancele a assinatura a qualquer momento.