IA e Arte · 13 min read · Sep 12, 2025
Como Treinar a IA de Difusão Estável com Seu Rosto para Criar Arte Usando DreamBooth
Postagem de Convidado por Tarunabh Dutta.
Se 2021 foi o ano dos modelos de linguagem baseados em palavras, 2022 deu um salto para os modelos de IA de Texto para Imagem. Existem muitos modelos de IA de texto para imagem disponíveis hoje que podem produzir imagens de alta qualidade. A Difusão Estável é uma das opções mais populares e conhecidas. É um modelo rápido e estável que produz resultados consistentes.

O processo de geração de imagens ainda é um tanto misterioso, mas é claro que a Difusão Estável produz resultados excelentes. Pode ser usada para gerar imagens a partir de texto ou para alterar imagens existentes. As opções e parâmetros disponíveis permitem muita personalização e controle sobre a imagem final.
Embora seja relativamente mais fácil trabalhar com imagens de celebridades e figuras populares, puramente por causa do conjunto de imagens já disponível, não é tão fácil fazer a IA trabalhar com seu próprio rosto. A lógica diz para alimentar o modelo de IA com suas imagens e deixá-lo fazer sua mágica, mas como exatamente alguém pode fazer isso?
Neste artigo, tentaremos demonstrar como treinar um modelo de Difusão Estável usando a inversão textual do DreamBooth em uma referência de imagem para construir representações de IA do seu próprio rosto ou de qualquer outro objeto e gerar fotos de resultados incríveis, precisão e consistência. Se isso soa muito técnico, fique por aqui, e tentaremos torná-lo o mais amigável possível para iniciantes.
O que é Difusão Estável?
Vamos esclarecer o básico. O modelo de Difusão Estável é um modelo de aprendizado de máquina de texto para imagem de última geração treinado em um grande conjunto de imagens. É caro para treinar, custando cerca de $660.000. No entanto, o modelo de Difusão Estável pode ser usado para gerar arte usando linguagem natural.
Modelos de IA de Texto para Imagem de aprendizado profundo estão se tornando cada vez mais populares devido à sua capacidade de traduzir texto com precisão em imagens. Este modelo é gratuito para usar e pode ser encontrado no Hugging Face Spaces e DreamStudio. Os pesos do modelo também podem ser baixados e usados localmente.
A Difusão Estável usa um processo chamado “difusão” para gerar imagens que se parecem com o prompt de texto.
Em resumo, o algoritmo de Difusão Estável pega uma descrição textual e gera uma imagem com base nessa descrição. A imagem gerada parecerá semelhante ao texto, mas não será uma réplica exata. As alternativas à Difusão Estável incluem os modelos Dall-E da OpenAI e Imagen do Google.
Leitura Relacionada: 9 Melhores Aplicativos de Gerador de Arte de IA para iPhone e Android
Guia para Treinar a IA de Difusão Estável com Seu Rosto para Criar Imagens Usando DreamBooth
Hoje, vou demonstrar como treinar um modelo de Difusão Estável usando meu rosto como referência inicial para gerar imagens com um estilo altamente consistente e preciso que é original e fresco.
Portanto, para esse propósito, usaremos um Google Colab chamado DreamBooth para treinar a Difusão Estável.
Antes de lançar este Google Colab, devemos preparar certos ativos de conteúdo.
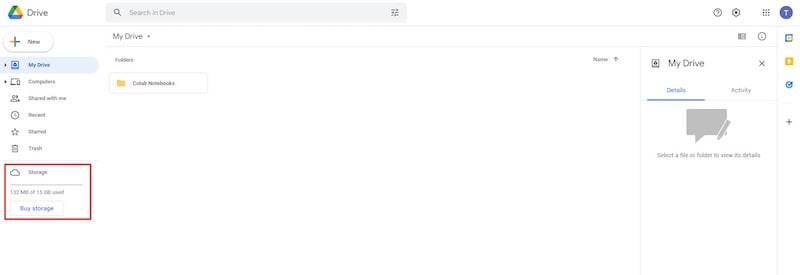
Etapa 1: Google Drive com espaço livre suficiente
Para isso, você precisa de uma conta do Google Drive com pelo menos 9 GB de espaço livre.
Uma conta gratuita do Google Drive vem com 15 GB de espaço de armazenamento gratuito, o que é suficiente para esta tarefa. Portanto, você pode criar uma nova conta do Gmail (descartável) apenas para esse propósito.
Etapa 2: Imagens de Referência para Treinar a IA
Em segundo lugar, você deve ter pelo menos uma dúzia de retratos do seu rosto ou de qualquer objeto-alvo prontos para serem usados como referências.
- Certifique-se de que as características faciais estejam visíveis e adequadamente iluminadas nas imagens capturadas. Evite usar sombras fortes, particularmente no rosto.
- Além disso, o sujeito deve estar de frente para a câmera ou ter um perfil lateral em que ambos os olhos e todas as características faciais estejam claramente visíveis.
- A câmera deve ser capaz de capturar características faciais de alta qualidade. A melhor opção é uma câmera DSLR ou mirrorless de nível profissional. Uma câmera de smartphone de excelente qualidade também pode ser suficiente.
- A composição deve estar posicionada no centro do quadro com um pouco de espaço acima da cabeça.
- Como imagens de entrada, um mínimo de doze fotos de close-up do rosto, cinco fotos de plano médio cobrindo da cabeça até acima da cintura, e cerca de três fotos de corpo inteiro devem ser adequadas.
- Um mínimo de vinte fotografias de referência deve ser suficiente para esse propósito.
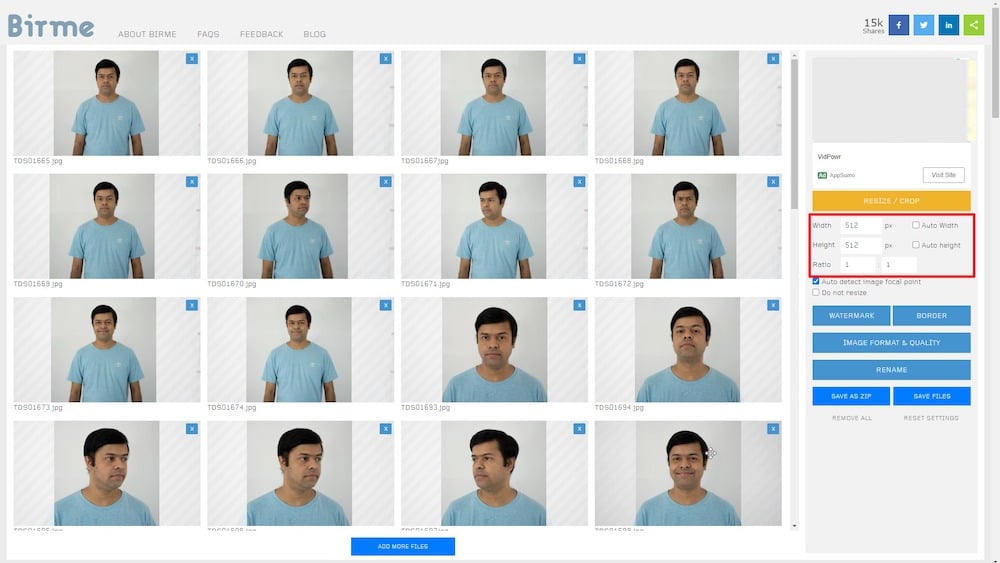
No meu caso, tirei e reuni uma coleção de aproximadamente 50 autorretratos, que recortei para 512 x 512 pixels usando a ferramenta online – Birme. Você também pode usar qualquer editor de imagem alternativo para esse propósito.
Por favor, tenha em mente que a imagem final de saída deve ser otimizada para a web e reduzida em tamanho de arquivo com perda mínima de qualidade.
Etapa 3: Google Colab
O tempo de execução do Google Colab pode agora ser executado.
Existem versões gratuitas e pagas da plataforma Google Colab. O Dreambooth pode ser executado na versão gratuita, mas o desempenho é significativamente mais rápido e mais consistente na versão Colab Pro (paga), que prioriza o uso de uma GPU de alta velocidade e atribui pelo menos 15 GB de VRAM à tarefa em questão.
Se você não se importar em gastar alguns dólares, uma assinatura do Colab Pro de $10 que inclui 100 unidades de computação por mês é mais do que adequada para esta sessão.
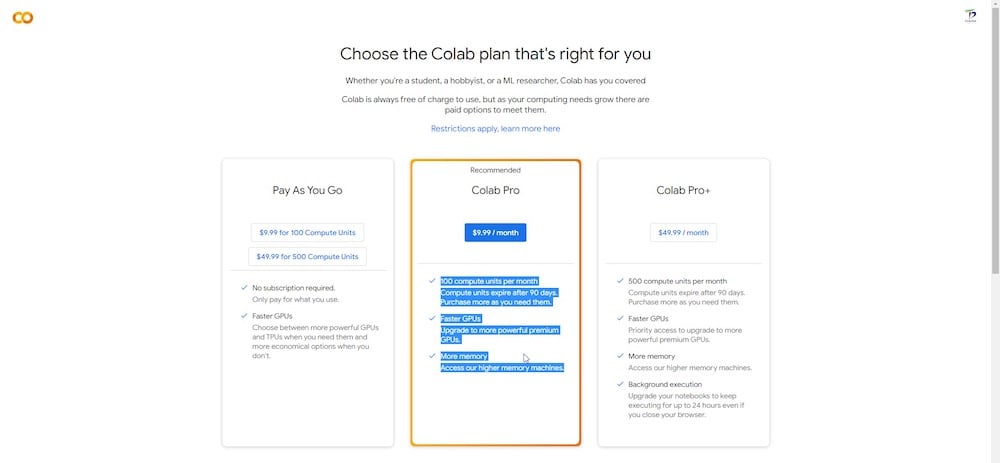
Você também terá acesso a memória RAM extra e GPUs que são relativamente mais poderosas e rápidas.
Deixe-me reiterar isso: Você NÃO precisa ser um especialista técnico para executar este Colab. Você também não precisa de nenhuma experiência anterior em codificação.
Uma vez que você se inscreva no Google Colab (versão gratuita ou paga), faça login com suas credenciais e vá para este link para abrir DreamBooth Stable Diffusion.
Um Google Colab tem seções ou células de “tempo de execução” com botões de reprodução clicáveis no lado esquerdo, que estão organizados sequencialmente. Para reproduzir o tempo de execução começando de cima, basta clicar nos botões de reprodução um por um. Cada segmento consiste em um tempo de execução que deve ser executado. Quando você clica em um botão de reprodução, a seção correspondente é executada como um tempo de execução. Após algum tempo, uma marca de verificação verde aparecerá à esquerda do botão de reprodução para indicar que o tempo de execução foi executado com sucesso.
Por favor, certifique-se de que você execute manualmente apenas um tempo de execução por vez e vá para a próxima seção de “tempo de execução” somente quando o tempo de execução atual tiver terminado.
Na parte superior da barra de menu do tempo de execução, você tem a opção de executar todos os tempos de execução simultaneamente. No entanto, isso não é recomendado.

Abaixo disso, há uma opção rotulada “Alterar tipo de tempo de execução”. Se você estiver inscrito em uma assinatura pro, poderá escolher e salvar uma GPU “premium” e alta RAM para sua execução.
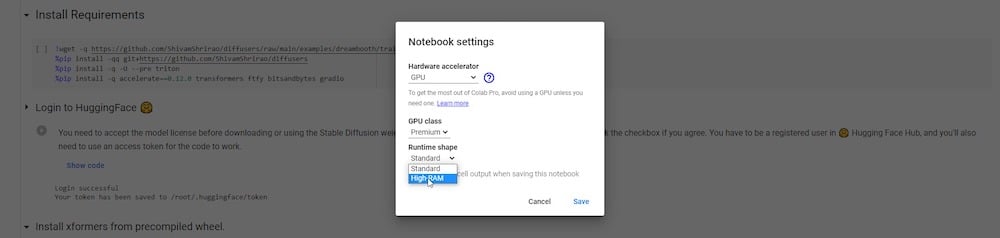
Agora você está pronto para começar o Colab do DreamBooth.

10 Passos para Completar com Sucesso um Modelo de IA Treinado no DreamBooth
PASSO 1: Decida sobre a GPU e VRAM
O primeiro passo é determinar o tipo de GPU e VRAM disponíveis. Usuários Pro terão acesso a GPU rápida e VRAM aprimorada que é mais estável.
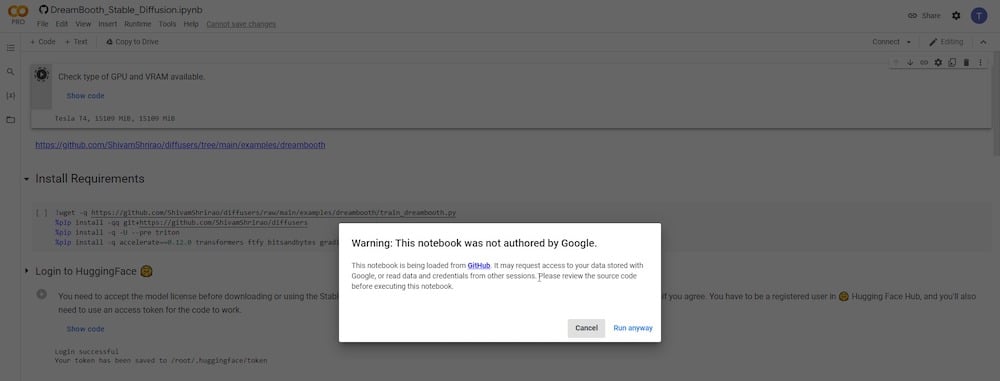
Uma vez que você clique no botão de reprodução, será exibido um aviso porque o GitHub, o site de origem do desenvolvedor, está sendo acessado. Você só precisa clicar em “ Executar de Qualquer Maneira ” para continuar.
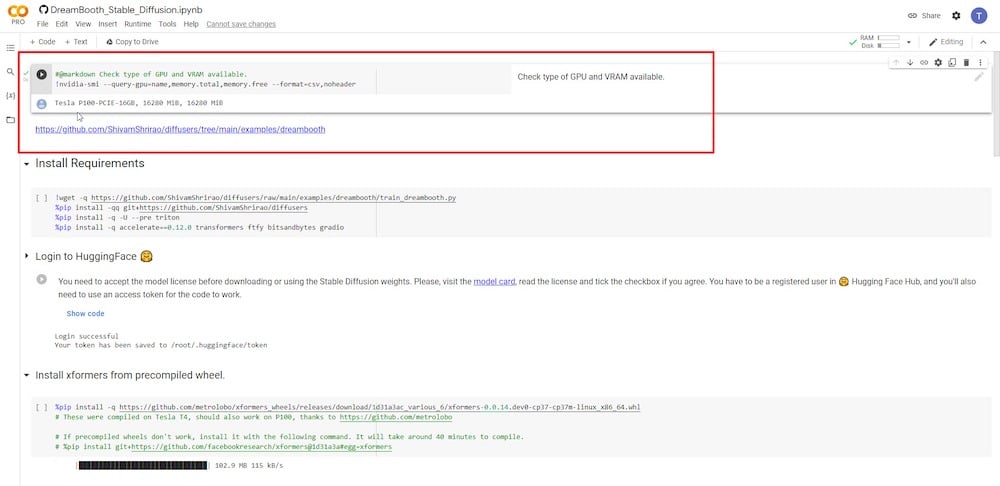
PASSO 2: Executar DreamBooth
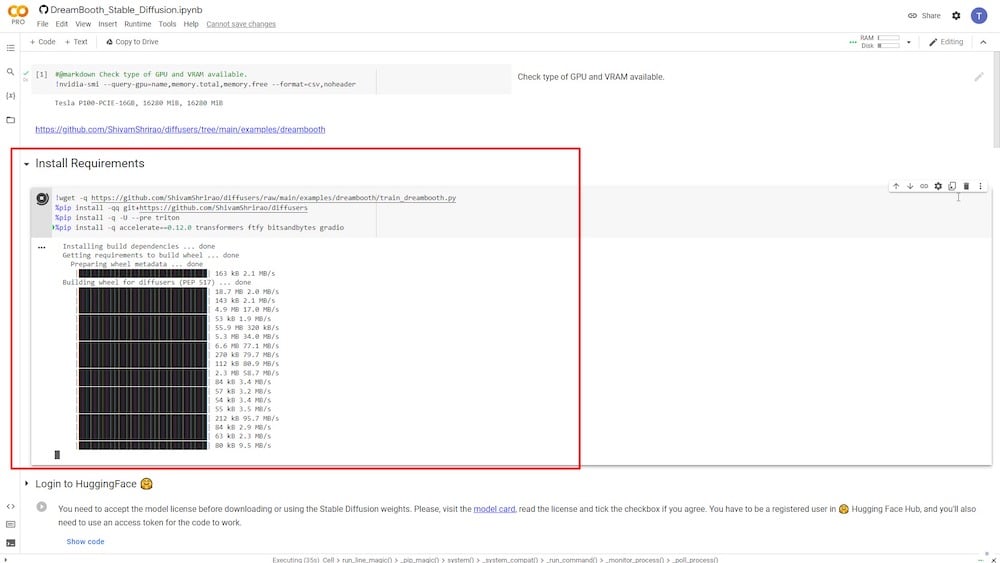
Na próxima etapa, você deve instalar certos requisitos e dependências. Você só precisa clicar no botão de reprodução e deixá-lo rodar.
PASSO 3: Faça login no Hugging Face
Após clicar no botão de reprodução, a próxima etapa exigirá que você faça login na sua conta do Hugging Face. Você pode criar uma conta gratuita se ainda não tiver uma. Uma vez logado, navegue até sua página de Configurações no canto superior direito.
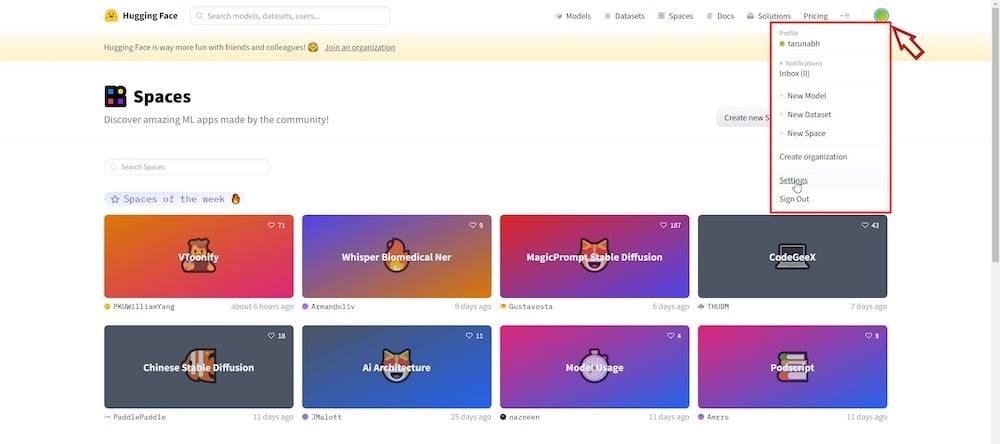
Em seguida, clique na seção ‘ Tokens de Acesso ‘ e no botão ‘ Criar Novo ‘ para gerar um novo “token de acesso” e renomeá-lo como desejar.
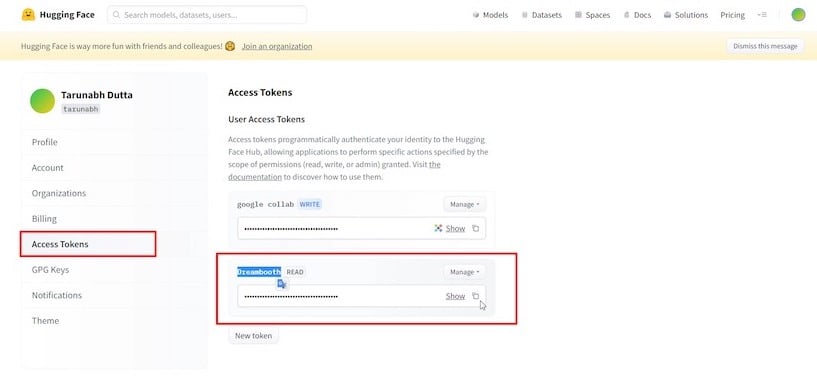
Copie o token de acesso, depois volte para a aba do Colab e insira-o no campo fornecido, em seguida clique em “ Login.”
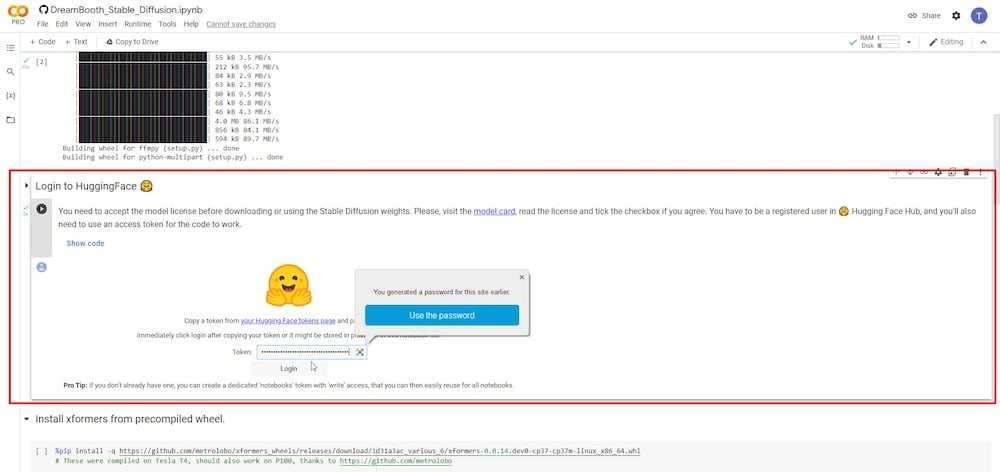
PASSO 4: Instalar xformers
Nesta etapa, você pode clicar no tempo de execução para instalar xformers simplesmente clicando no botão de reprodução.
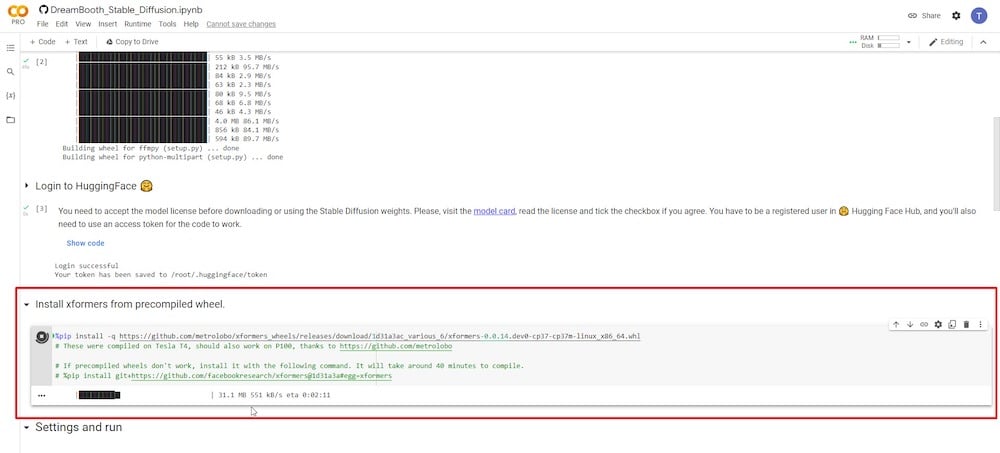
PASSO 5: Conectar Google Drive
Após clicar no botão reproduzir, você será solicitado em uma nova janela pop-up a permitir o acesso à sua conta do Google Drive. Clique em “Permitir” quando solicitado por permissões.
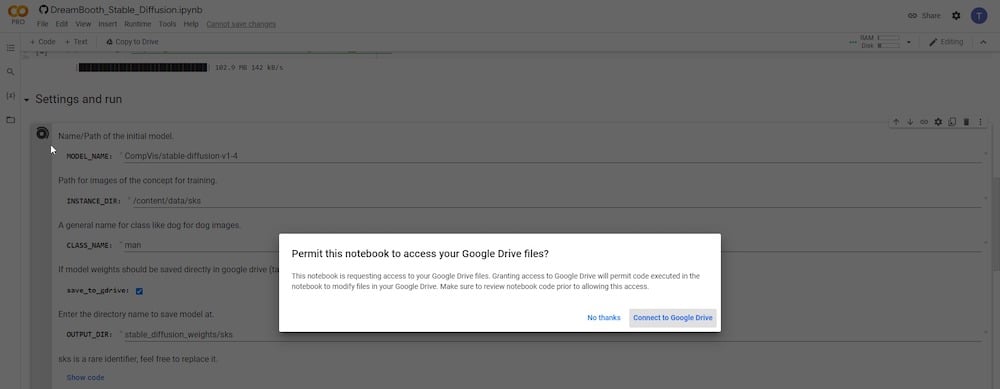
Após conceder permissões, você deve confirmar que “ salvar no Google Drive ” está selecionado. Você também deve definir um novo nome para a variável ‘ NOME DA CLASSE ‘. Se você deseja enviar imagens de referência de uma pessoa, basta colocar ‘pessoa’, ‘homem’ ou ‘mulher’. Se suas imagens de referência forem de um cachorro, digite ‘cachorro’ e assim por diante. Você pode manter os demais campos inalterados. Alternativamente, você pode renomear o diretório de entrada—’DIRETÓRIO DE INSTÂNCIA’ ou o diretório de saída—’DIRETÓRIO DE SAÍDA.’
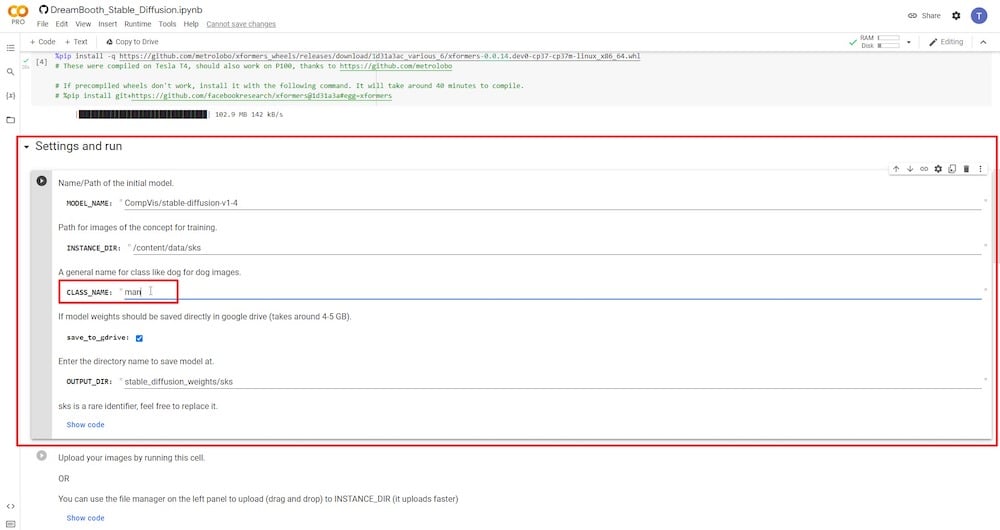
PASSO 6: Carregar fotos de referência
Após clicar no botão de reprodução na etapa anterior, você verá a opção de carregar e adicionar todas as suas fotos de referência.
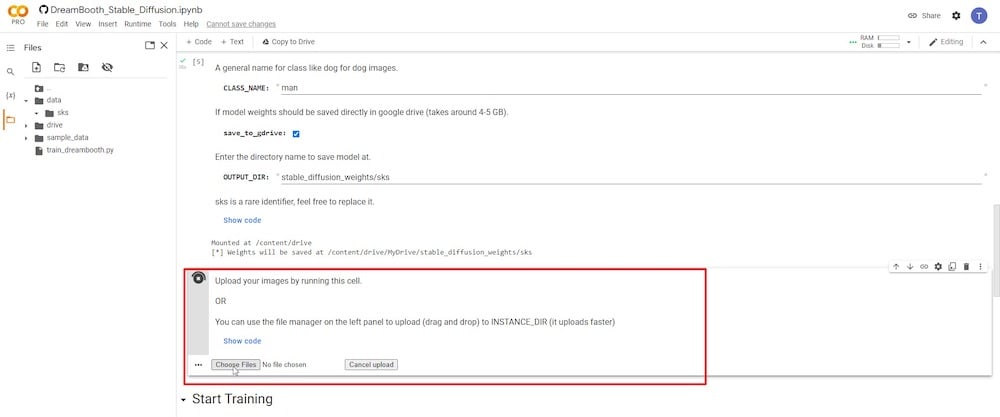
Eu recomendaria um mínimo de 6 e um máximo de 20 fotografias. Consulte “ETAPA 2” acima para uma explicação concisa de como selecionar a melhor imagem de referência com base em como o sujeito é capturado.
Uma vez que todas as suas imagens tenham sido carregadas, você pode visualizá-las na coluna da esquerda. Há um ícone de pasta. Assim que você clicar nele, poderá visualizar as pastas e subpastas nas quais seus dados estão atualmente armazenados.
Sob o diretório de dados, você pode visualizar seu diretório de entrada, onde todas as suas fotos carregadas estão armazenadas. No meu caso, é conhecido como “sks” (nome padrão).
Além disso, observe que este conteúdo é armazenado temporariamente apenas no seu armazenamento do Google Colab e não no Google Drive.
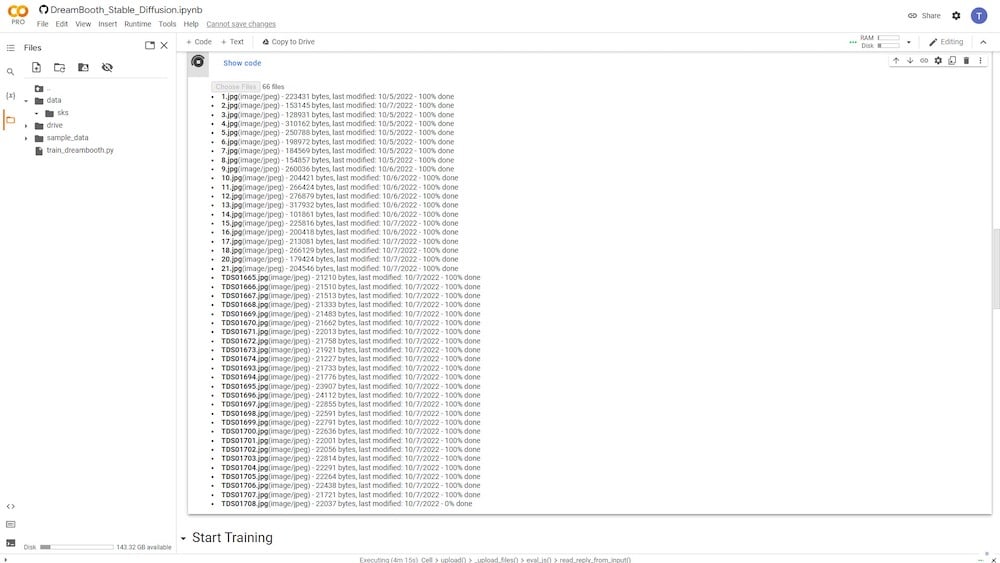
PASSO 7: Treinar o modelo de IA com DreamBooth
Este é o passo mais crucial, pois você estará treinando um novo modelo de IA com base em todas as suas fotos de referência carregadas usando o DreamBooth.
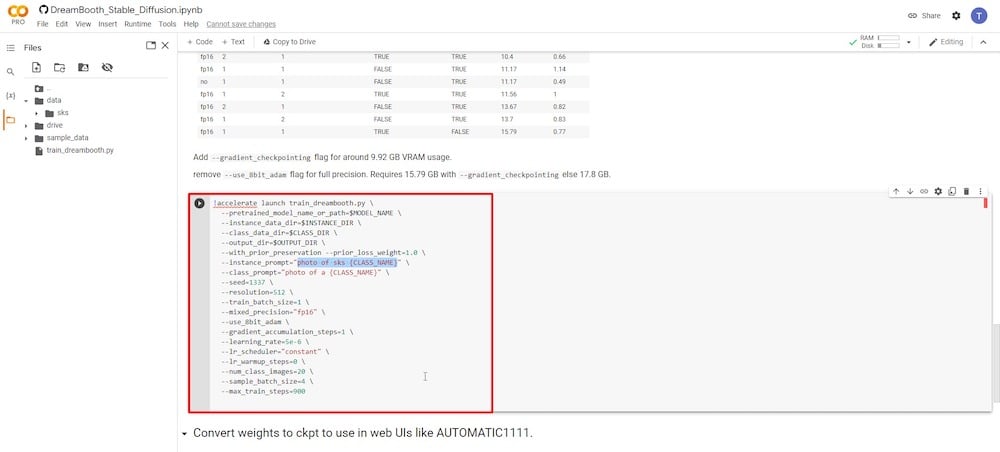
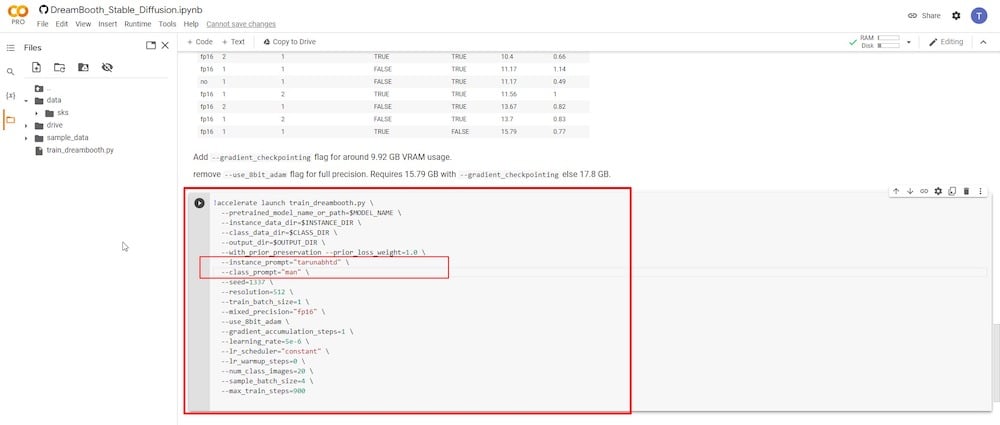
Você deve se concentrar apenas em dois campos de entrada. O primeiro parâmetro é “—instance prompt.” Aqui, você deve inserir um nome muito único. No meu caso, usarei meu primeiro nome seguido das minhas iniciais. A ideia é manter o nome completo único e preciso.
O segundo campo de entrada crucial é o parâmetro ‘—class prompt’. Você deve renomeá-lo para corresponder ao que usou no ‘PASSO 4’. No meu caso, usei o termo “homem.” Então, vou reescrevê-lo neste campo e sobrescrever qualquer entrada anterior.
Os demais campos podem ser deixados inalterados. Observei usuários experimentando alterando campos como ‘—num class images’ para 12 e ‘—max train steps’ para 1000, 2000 ou até mais. No entanto, lembre-se de que modificar esses campos pode fazer com que o Colab fique sem memória e trave, exigindo que você reinicie do início. Portanto, é aconselhável não editá-los na tentativa inicial. Você pode experimentar com eles no futuro, após ganhar experiência suficiente.
Uma vez que você execute este tempo de execução clicando no botão de reprodução, o Colab começará a baixar os arquivos executáveis necessários e então poderá treinar usando suas fotos de referência.
Treinar o modelo levará de 15 minutos a mais de uma hora. Você deve ser paciente e acompanhar o progresso até que o tempo de execução seja concluído. Se o seu Google Colab ficar ocioso por muito tempo, pode ser reiniciado. Portanto, continue verificando o progresso e clicando na aba ocasionalmente.
PASSO 8: Converter o modelo de IA para o formato ckpt
Após o treinamento ser concluído, você terá a opção de converter o modelo treinado para um arquivo no formato ckpt, que é diretamente compatível com a Difusão Estável.
A conversão pode ser realizada em duas fases de tempo de execução. A primeira é “ Download script,” e a segunda é “ Run conversion,” onde você tem a opção de reduzir o tamanho do download do modelo treinado. No entanto, fazer isso degradará significativamente a qualidade da imagem resultante.
Portanto, para manter o tamanho original, a opção ‘ fp16 ‘ deve permanecer desmarcada.
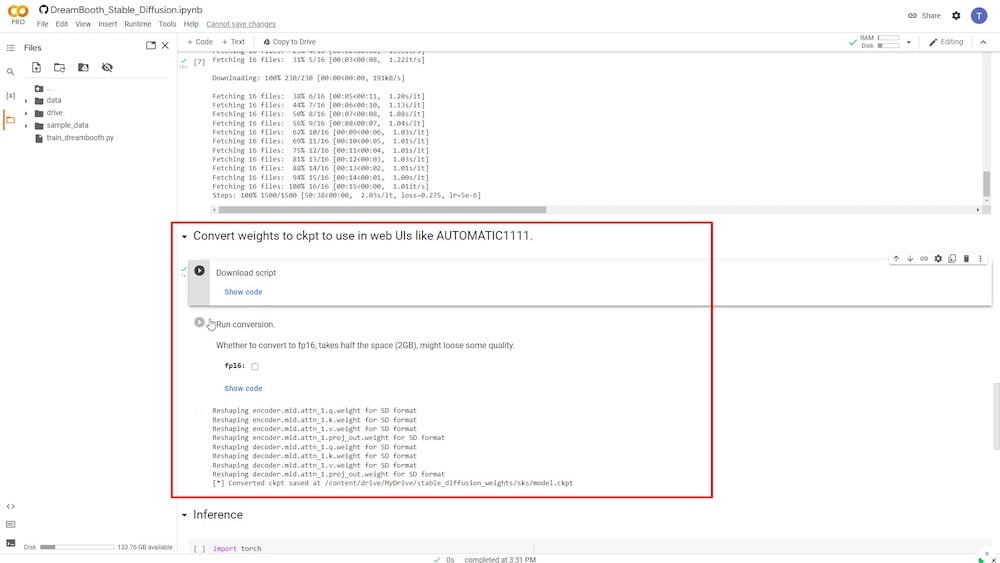
No final deste tempo de execução específico, um arquivo chamado “ model.ckpt ” será salvo no seu Google Drive conectado.
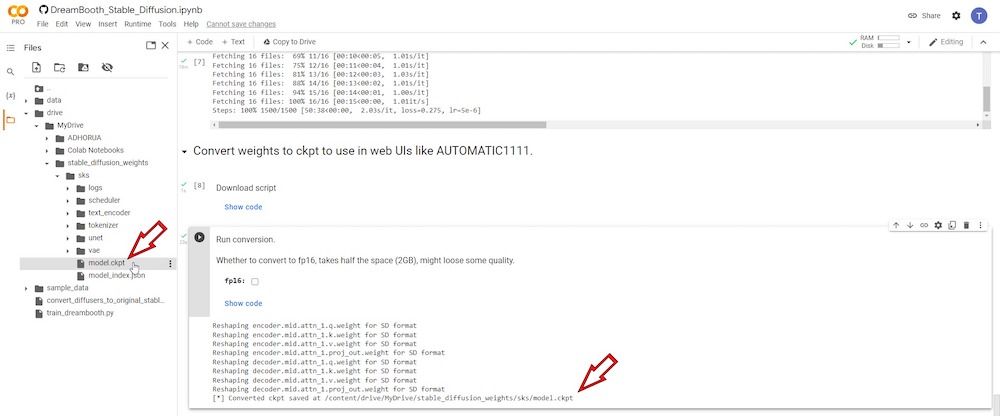
Podemos salvar este arquivo para uso futuro, pois seus tempos de execução são imediatamente excluídos quando você fecha a aba do navegador do DreamBooth Colab. Quando você reabrir a versão do Colab do DreamBooth mais tarde, terá que começar do zero.
Suponha que você salve o arquivo do modelo treinado no seu Google Drive. Nesse caso, você poderá recuperá-lo mais tarde para usar com sua GUI de Difusão Estável instalada localmente, DreamBooth, ou qualquer caderno do Colab de Difusão Estável que exija que o arquivo “model.ckpt” seja carregado para que o tempo de execução funcione efetivamente. Você também pode salvá-lo em seus discos rígidos locais para uso posterior.
PASSO 9: Preparar para o Prompt Textual
Os próximos dois processos de tempo de execução na categoria “Inferência” preparam o novo modelo treinado para o prompt textual usado para a geração de imagens. Basta pressionar o botão de reprodução para cada tempo de execução, e ele terminará em questão de minutos.
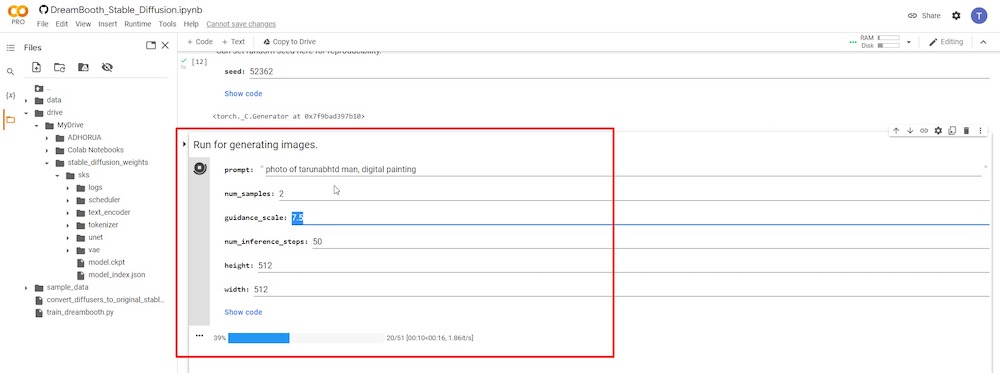
PASSO 10: Gerar Imagens de IA
Este é o passo final, onde você pode digitar os prompts textuais, e as imagens de IA serão geradas.
Você deve usar o nome exato de ‘instance_prompt’ e ‘–class_prompt’ juntos do PASSO 6 no início do prompt de texto. Por exemplo, no meu caso, usei “um retrato do homem tarunabhtd, pintura digital” para gerar novas imagens de IA que se assemelham a mim.
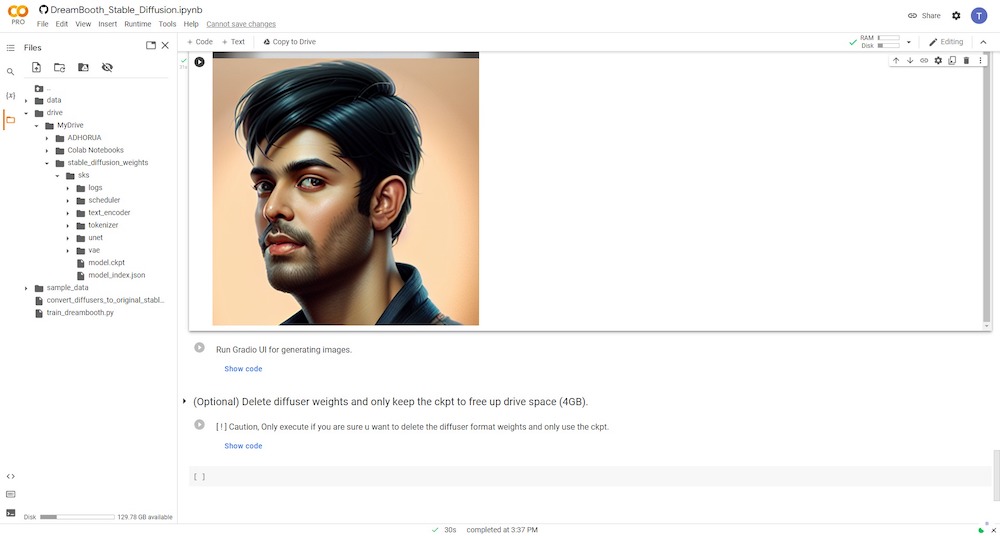
Abaixo você pode ver alguns resultados de imagem gerados com o modelo treinado do DreamBooth.

Brinque com Prompts para Obter os Melhores Resultados
Se você seguir cuidadosamente os passos descritos acima, conseguirá gerar imagens de IA que se assemelham muito às características faciais em suas imagens de referência. Este método requer apenas a plataforma online Google Colab para executar uma versão aprimorada da tecnologia de IA para inversão textual.
Para melhores ideias para prompts de texto, você pode conferir sites como –
- OpenArt AI
- Krea AI
- Lexica art
Você também precisa aprender a arte de criar prompts de texto melhores e mais eficazes usando uma variedade de estilos artísticos e várias combinações. Um bom ponto de partida seria o SubReddit de Difusão Estável.
O Reddit tem uma grande comunidade dedicada à Difusão Estável. Também existem vários grupos no Facebook e comunidades no Discord discutindo, compartilhando e explorando novas avenidas da Difusão Estável.
Abaixo, também estou compartilhando links para alguns vídeos tutoriais do DreamBooth que você pode assistir no Youtube –
Espero que você ache este guia útil. Se você tiver alguma dúvida, sinta-se à vontade para comentar abaixo, e tentaremos ajudá-lo.
Autor: Tarunabh Dutta é um cineasta premiado que completou mais de 45 projetos nos últimos 16 anos, incluindo longas-metragens, curtas-metragens, videoclipes, documentários e anúncios comerciais, sob sua bandeira independente ‘TD Film Studio’.
Receba novas postagens na sua caixa de entrada
Sem spam. Cancele a assinatura a qualquer momento.