Kubernetes · 23 min read · Nov 03, 2025
Основные компоненты кластера Kubernetes

Kubernetes — это платформа с открытым исходным кодом для управления контейнеризованными рабочими нагрузками и службами, которая облегчает декларативную конфигурацию и автоматизацию. Название Kubernetes произошло от греческого слова, означающего штурман или пилот. Он портативен, а также расширяем и имеет быстро растущую экосистему. Услуги и инструменты Kubernetes широко доступны.
В этой статье мы рассмотрим основные компоненты Kubernetes с высоты 10,000 футов, от того, из чего состоит каждый контейнер, до того, как контейнер в поде разворачивается и планируется на каждом из рабочих узлов. Крайне важно понимать все детали кластера Kubernetes, чтобы иметь возможность развертывать и проектировать решение на основе Kubernetes как оркестратора для контейнеризованных приложений.
Вот краткий обзор того, что мы собираемся охватить в этой статье:
- Компоненты контрольной панели
- Компоненты рабочих узлов Kubernetes
- Поды как основные строительные блоки
- Услуги Kubernetes, балансировщики нагрузки и контроллеры Ingress
- Развертывания Kubernetes и наборы демонов
- Постоянное хранилище в Kubernetes
Контрольная плоскость Kubernetes
Мастера узлов Kubernetes — это место, где находятся основные службы контрольной плоскости; не все службы должны находиться на одном узле, однако для централизации и практичности они часто разворачиваются таким образом. Это, очевидно, вызывает вопросы о доступности служб; однако их можно легко преодолеть, имея несколько узлов и обеспечивая балансировку нагрузки для достижения высокодоступного набора мастер-узлов.
Мастера узлов состоят из четырех основных служб:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- база данных etcd
Мастера узлов могут работать как на физических серверах, так и на виртуальных машинах, или в частном или публичном облаке, но не рекомендуется запускать контейнерные рабочие нагрузки на них. Мы увидим больше об этом позже.
Следующая диаграмма показывает компоненты мастер-узлов Kubernetes:
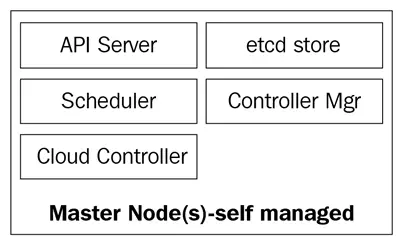
kube-apiserver
API сервер — это то, что связывает все вместе. Это фронтенд REST API кластера, который получает манифесты для создания, обновления и удаления объектов API, таких как службы, поды, Ingress и другие.
kube-apiserver — это единственная служба, с которой мы должны общаться; это также единственная служба, которая записывает и общается с базой данных etcd для регистрации состояния кластера. С помощью команды kubectl мы будем отправлять команды для взаимодействия с ним. Это будет наш швейцарский армейский нож, когда дело касается Kubernetes.
kube-controller-manager
Демон kube-controller-manager, в двух словах, представляет собой набор бесконечных контрольных циклов, которые упакованы для простоты в один бинарный файл. Он следит за определенным желаемым состоянием кластера и обеспечивает его достижение, перемещая все необходимые элементы для этого. kube-controller-manager — это не просто один контроллер; он содержит несколько различных циклов, которые следят за различными компонентами в кластере. Некоторые из них — это контроллер службы, контроллер пространства имен, контроллер учетной записи службы и многие другие. Вы можете найти каждый контроллер и его определение в репозитории Kubernetes на GitHub: https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
kube-scheduler
kube-scheduler планирует ваши вновь созданные поды на узлы с достаточным пространством для удовлетворения потребностей ресурсов подов. Он в основном слушает kube-apiserver и kube-controller-manager на предмет вновь созданных подов, которые помещаются в очередь, а затем планируются на доступный узел планировщиком. Определение kube-scheduler можно найти здесь: https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Кроме вычислительных ресурсов, kube-scheduler также читает правила аффинности и анти-аффинности узлов, чтобы выяснить, может ли узел запустить этот под или нет.
База данных etcd
База данных etcd — это очень надежное согласованное хранилище ключ-значение, которое используется для хранения состояния кластера Kubernetes. Она содержит текущее состояние подов, на которых работает узел, сколько узлов в кластере в настоящее время, каково состояние этих узлов, сколько реплик развертывания работает, имена служб и другие.
Как мы уже упоминали, только kube-apiserver общается с базой данных etcd. Если kube-controller-manager нужно проверить состояние кластера, он будет обращаться через API сервер, чтобы получить состояние из базы данных etcd, вместо того чтобы запрашивать хранилище etcd напрямую. То же самое происходит с kube-scheduler, если планировщик должен сообщить, что под был остановлен или выделен другому узлу; он сообщит API серверу, и API сервер сохранит текущее состояние в базе данных etcd.
С помощью etcd мы охватили все основные компоненты для наших мастер-узлов Kubernetes, чтобы мы были готовы управлять нашим кластером. Но кластер состоит не только из мастеров; нам все еще нужны узлы, которые будут выполнять тяжелую работу, запуская наши приложения.
Рабочие узлы Kubernetes
Рабочие узлы, которые выполняют эту задачу в Kubernetes, просто называются узлами. Ранее, около 2014 года, их называли миньонами, но этот термин позже был заменен на просто узлы, так как название вызывало путаницу с терминологиями Salt и заставляло людей думать, что Salt играет важную роль в Kubernetes.
Эти узлы — единственное место, где вы будете запускать рабочие нагрузки, так как не рекомендуется иметь контейнеры или нагрузки на мастер-узлах, поскольку они должны быть доступны для управления всем кластером. Узлы очень просты с точки зрения компонентов; им требуется всего три службы для выполнения своей задачи:
- Kubelet
- Kube-proxy
- Виртуальная среда выполнения контейнеров
Давайте подробнее рассмотрим эти три компонента.
Kubelet
Kubelet — это низкоуровневый компонент Kubernetes и один из самых важных после kube-apiserver; оба этих компонента необходимы для развертывания подов/контейнеров в кластере. Kubelet — это служба, которая работает на узлах Kubernetes и слушает API сервер для создания подов. Kubelet отвечает только за запуск/остановку и обеспечение того, чтобы контейнеры в подах были здоровыми; kubelet не сможет управлять никакими контейнерами, которые не были созданы им.
Kubelet достигает своих целей, общаясь с виртуальной средой выполнения контейнеров через интерфейс виртуальной среды выполнения контейнеров (CRI). CRI предоставляет возможность подключения к kubelet через gRPC-клиент, который может общаться с различными виртуальными средами выполнения контейнеров. Как мы уже упоминали, Kubernetes поддерживает несколько виртуальных сред выполнения контейнеров для развертывания контейнеров, и именно так он достигает такой разнообразной поддержки различных движков.
Вы можете проверить исходный код kubelet по адресу https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
Kube-proxy
Kube-proxy — это служба, которая находится на каждом узле кластера и делает возможным общение между подами, контейнерами и узлами. Эта служба следит за kube-apiserver на предмет изменений в определенных службах (служба — это своего рода логический балансировщик нагрузки в Kubernetes; мы подробнее рассмотрим службы позже в этой статье) и поддерживает сеть в актуальном состоянии через правила iptables, которые перенаправляют трафик к правильным конечным точкам. Kube-proxy также настраивает правила в iptables, которые выполняют случайное распределение нагрузки между подами за службой.
Вот пример правила iptables, созданного kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment –comment “default/example: has no endpoints” -m tcp –dport 80 -j REJECT –reject-with icmp-port-unreachable
Обратите внимание, что это служба без конечных точек (без подов за ней).
Виртуальная среда выполнения контейнеров
Чтобы иметь возможность запускать контейнеры, нам требуется виртуальная среда выполнения контейнеров. Это базовый движок, который создаст контейнеры в ядре узлов, чтобы наши поды могли работать. Kubelet будет общаться с этой средой выполнения и будет запускать или останавливать наши контейнеры по мере необходимости.
В настоящее время Kubernetes поддерживает любую виртуальную среду выполнения контейнеров, соответствующую стандарту OCI, такую как Docker, rkt, runc, runsc и так далее.
Вы можете обратиться к этому https://github.com/opencontainers/runtime-spec, чтобы узнать больше обо всех спецификациях на странице Git-Hub OCI.
Теперь, когда мы исследовали все основные компоненты, которые формируют кластер, давайте посмотрим, что можно сделать с ними и как Kubernetes поможет нам оркестровать и управлять нашими контейнеризованными приложениями.
Объекты Kubernetes
Объекты Kubernetes — это именно то: они являются логическими постоянными объектами или абстракциями, которые будут представлять состояние вашего кластера. Вы отвечаете за то, чтобы сообщить Kubernetes, каково ваше желаемое состояние этого объекта, чтобы он мог работать над его поддержанием и обеспечением его существования.
Чтобы создать объект, ему необходимо иметь две вещи: статус и его спецификацию. Статус предоставляется Kubernetes, и это текущее состояние объекта. Kubernetes будет управлять и обновлять этот статус по мере необходимости, чтобы он соответствовал вашему желаемому состоянию. Поле спецификации, с другой стороны, — это то, что вы предоставляете Kubernetes, и это то, что вы говорите ему, чтобы описать желаемый вами объект. Например, изображение, которое вы хотите, чтобы контейнер работал, количество контейнеров этого изображения, которые вы хотите запустить, и так далее.
Каждый объект имеет специфические поля спецификации для типа задачи, которую они выполняют, и вы будете предоставлять эти спецификации в YAML-файле, который отправляется на kube-apiserver с помощью kubectl, который преобразует его в JSON и отправляет как API-запрос. Мы подробнее рассмотрим каждый объект и его поля спецификации позже в этой статье.
Вот пример YAML, который был отправлен на kubectl:
cat << EOF | kubectl create -f -kind: ServiceapiVersion: v1metadata: Name: frontend-servicespec: selector: web: frontend ports: - protocol: TCP port: 80 targetPort: 9256EOF
Основные поля определения объекта — это самые первые, и они не будут варьироваться от объекта к объекту и очень понятны. Давайте быстро взглянем на них:
- kind: Поле kind говорит Kubernetes, какой тип объекта вы определяете: под, служба, развертывание и так далее
- apiVersion: Поскольку Kubernetes поддерживает несколько версий API, нам нужно указать путь REST API, к которому мы хотим отправить наше определение
- metadata: Это вложенное поле, что означает, что у вас есть несколько дополнительных подполей для metadata, где вы будете писать основные определения, такие как имя вашего объекта, назначение его в конкретное пространство имен и также присвоение ему метки, чтобы связать ваш объект с другими объектами Kubernetes
Итак, мы теперь прошли через наиболее используемые поля и их содержимое; вы можете узнать больше о соглашениях API Kubernetes по адресу https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Некоторые поля объекта могут быть изменены после создания объекта, но это будет зависеть от объекта и поля, которое вы хотите изменить.
Следующий список — это краткий список различных объектов Kubernetes, которые вы можете создать:
- Под
- Объем
- Служба
- Развертывание
- Ingress
- Секрет
- ConfigMap
И это еще не все.
Давайте подробнее рассмотрим каждый из этих элементов.
Поды — основа Kubernetes
Поды — это самые базовые объекты в Kubernetes и также самые важные. Все вращается вокруг них; мы можем сказать, что Kubernetes предназначен для подов! Все остальные объекты здесь, чтобы служить им, и все задачи, которые они выполняют, направлены на то, чтобы сделать так, чтобы поды достигли вашего желаемого состояния.
Итак, что такое под и почему поды так важны?
Под — это логический объект, который запускает один или несколько контейнеров вместе в одном сетевом пространстве имен, одной межпроцессной коммуникации (IPC) и, иногда, в зависимости от версии Kubernetes, в одном пространстве имен идентификаторов процессов (PID). Это потому, что именно они будут запускать наши контейнеры и, следовательно, будут в центре внимания. Вся суть Kubernetes заключается в том, чтобы быть оркестратором контейнеров, и с помощью подов мы делаем оркестрацию возможной.
Как мы уже упоминали, контейнеры в одном поде живут в “пузыре”, где они могут общаться друг с другом через localhost, так как они локальны друг к другу. Один контейнер в поде имеет тот же IP-адрес, что и другой контейнер, потому что они делят сетевое пространство имен, но в большинстве случаев вы будете запускать на основе один-к-одному, то есть один контейнер на под. Несколько контейнеров на под используются только в очень специфических сценариях, таких как когда приложение требует помощника, такого как передатчик данных или прокси, который должен быстро и надежно общаться с основным приложением.
Способ определения пода такой же, как и для любого другого объекта Kubernetes: через YAML, который содержит все спецификации и определения пода:
kind: PodapiVersion: v1metadata:name: hello-podlabels: hello: podspec: containers: - name: hello-container image: alpine args: - echo - “Hello World”
Давайте рассмотрим основные определения пода, необходимые в поле спецификации для создания нашего пода:
- Контейнеры: Контейнер — это массив; поэтому у нас есть набор нескольких подполей под ним. В основном, это то, что определяет контейнеры, которые будут работать на поде. Мы можем указать имя для контейнера, изображение, от которого он будет создан, и аргументы или команды, которые нам нужно, чтобы он выполнил. Разница между аргументами и командами такая же, как разница между CMD и ENTRYPOINT. Обратите внимание, что все поля, которые мы только что рассмотрели, относятся к массиву контейнеров. Они не являются частью спецификации пода.
- restartPolicy: Это поле именно такое: оно говорит Kubernetes, что делать с контейнером, и оно применяется ко всем контейнерам в поде в случае нулевого или ненулевого кода выхода. Вы можете выбрать один из вариантов: Never, OnFailure или Always. Always будет значением по умолчанию, если политика перезапуска не определена.
Это самые основные спецификации, которые вы собираетесь объявить в поде; другие спецификации потребуют от вас немного больше знаний о том, как их использовать и как они взаимодействуют с различными другими объектами Kubernetes. Мы вернемся к ним позже в этой статье; некоторые из них следующие:
- Объем
- Env
- Порты
- dnsPolicy
- initContainers
- nodeSelector
- Ограничения и запросы ресурсов
Чтобы просмотреть поды, которые в настоящее время работают в вашем кластере, вы можете выполнить kubectl get pods:
dsala@MININT-IB3HUA8:~$ kubectl get podsNAME READY STATUS RESTARTS AGEbusybox 1/1 Running 120 5d
В качестве альтернативы вы можете выполнить kubectl describe pods, не указывая никакой под. Это выведет описание каждого пода, работающего в кластере. В этом случае это будет только под busybox, так как это единственный, который в настоящее время работает:
dsala@MININT-IB3HUA8:~$ kubectl describe podsName: busyboxNamespace: defaultPriority: 0PriorityClassName:
Поды смертны. Как только он умирает или удаляется, его нельзя восстановить. Его IP и контейнеры, которые работали на нем, будут потеряны; они совершенно эфемерны. Данные на подах, которые смонтированы как объем, могут выжить или не выжить, в зависимости от того, как вы это настроите. Если наши поды умирают и мы теряем их, как мы можем гарантировать, что все наши микросервисы работают? Что ж, развертывания — это ответ.
Развертывания
Поды сами по себе не очень полезны, так как неэффективно иметь более одной копии нашего приложения, работающего в одном поде. Обеспечение сотен копий нашего приложения на разных подах без метода поиска их всех быстро выйдет из-под контроля.
Здесь на помощь приходят развертывания. С помощью развертываний мы можем управлять нашими подами с помощью контроллера. Это позволяет нам не только решать, сколько мы хотим запустить, но мы также можем управлять обновлениями, изменяя версию изображения или само изображение, которое запускают наши контейнеры. Развертывания — это то, с чем вы будете работать большую часть времени. С развертываниями, а также подами и любыми другими объектами, которые мы упоминали ранее, у них есть собственное определение внутри YAML-файла:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deployment labels: deployment: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
Давайте начнем исследовать их определение.
В начале YAML у нас есть более общие поля, такие как apiVersion, kind и metadata. Но под spec мы найдем специфические опции для этого API-объекта.
Под spec мы можем добавить следующие поля:
Selector: С помощью поля Selector развертывание будет знать, какие поды нацеливать, когда изменения применяются. Есть два поля, которые вы будете использовать под селектором: matchLabels и matchExpressions. С помощью matchLabels селектор будет использовать метки подов (пары ключ/значение). Важно отметить, что все метки, которые вы указываете здесь, будут связаны логическим оператором И. Это означает, что под должен иметь все метки, которые вы указываете под matchLabels.
Replicas: Это указывает количество подов, которые развертывание должно поддерживать в рабочем состоянии через контроллер репликации; например, если вы укажете три реплики, и один из подов умрет, контроллер репликации будет следить за спецификацией реплик как за желаемым состоянием и сообщит планировщику, чтобы запланировать новый под, так как текущее состояние теперь 2, поскольку под умер.
RevisionHistoryLimit: Каждый раз, когда вы вносите изменения в развертывание, это изменение сохраняется как ревизия развертывания, к которой вы позже можете вернуться к предыдущему состоянию или сохранить запись о том, что было изменено. Вы можете просмотреть свою историю с помощью kubectl rollout history deployment/<имя развертывания>. С помощью revisionHistoryLimit вы можете установить число, указывающее, сколько записей вы хотите сохранить.
Strategy: Это позволит вам решить, как вы хотите обрабатывать любое обновление или горизонтальное масштабирование подов. Чтобы переопределить значение по умолчанию, которое является rollingUpdate, вам нужно написать ключ type, где вы можете выбрать между двумя значениями: recreate или rollingUpdate.
В то время как recreate — это быстрый способ обновить ваше развертывание, он удалит все поды и заменит их новыми, но это будет означать, что вам нужно будет учитывать, что для этой стратегии будет время простоя системы. rollingUpdate, с другой стороны, более плавный и медленный и идеален для состояний приложений, которые могут перераспределять свои данные. rollingUpdate открывает дверь для двух дополнительных полей, которые maxSurge и maxUnavailable.
Первое будет указывать, сколько подов выше общего количества вы хотите, когда выполняете обновление; например, развертывание с 100 подами и 20% maxSurge вырастет до максимума в 120 подов во время обновления. Следующий параметр позволит вам выбрать, сколько подов в процентном соотношении вы готовы убить, чтобы заменить их новыми в сценарии с 100 подами. В случаях, когда maxUnavailable составляет 20%, только 20 подов будут убиты и заменены новыми, прежде чем продолжить замену остальных развертывания.
Template: Это просто вложенное поле спецификации пода, где вы включите все спецификации и метаданные подов, которые развертывание будет управлять.
Мы увидели, что с помощью развертываний мы управляем нашими подами, и они помогают нам поддерживать их в состоянии, которое мы желаем. Все эти поды все еще находятся в чем-то, называемом кластерной сетью, которая является закрытой сетью, в которой только компоненты кластера Kubernetes могут общаться друг с другом, даже имея свой собственный набор диапазонов IP. Как мы можем общаться с нашими подами извне? Как мы можем достичь нашего приложения? Здесь на помощь приходят службы.
Службы:
Название служба не полностью описывает то, что на самом деле делают службы в Kubernetes. Службы Kubernetes — это то, что направляет трафик к нашим подам. Мы можем сказать, что службы связывают поды вместе.
Представим, что у нас есть типичное приложение типа фронтенд/бэкенд, где наши фронтенд-поды общаются с нашими бэкенд-подами через IP-адреса подов. Если под в бэкенде умирает, мы теряем связь с нашим бэкендом. Это не только потому, что новый под не будет иметь тот же IP-адрес, что и под, который умер, но теперь нам также нужно перенастроить наше приложение, чтобы использовать новый IP-адрес. Эта проблема и подобные ей решаются с помощью служб.
Служба — это логический объект, который говорит kube-proxy создать правила iptables на основе того, какие поды находятся за службой. Службы настраивают свои конечные точки, которые являются тем, как поды, находящиеся за службой, называются, так же, как развертывания знают, какие поды контролировать, поле селектора и метки подов.
Эта диаграмма показывает, как службы используют метки для управления трафиком:
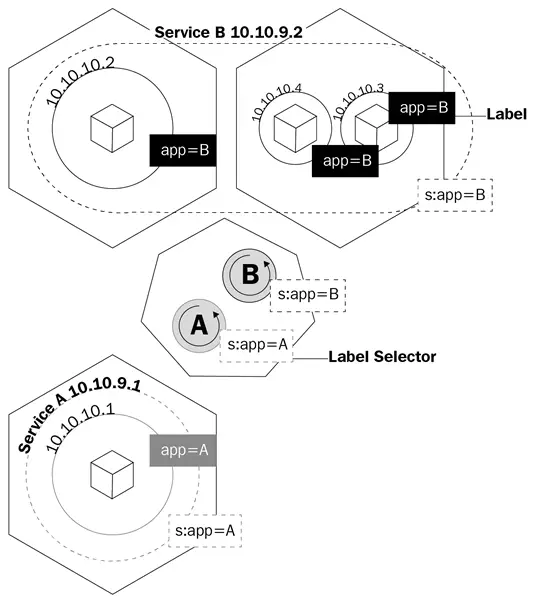
Службы не только заставляют kube-proxy создавать правила для маршрутизации трафика; они также запускают то, что называется kube-dns.
Kube-dns — это набор подов с контейнерами SkyDNS, которые работают в кластере и предоставляют DNS-сервер и пересылатель, который будет создавать записи для служб и иногда подов для удобства. Каждый раз, когда вы создаете службу, создается DNS-запись, указывающая на внутренний IP-адрес службы кластера в форме service-name.namespace.svc.cluster.local. Вы можете узнать больше о спецификациях DNS Kubernetes здесь: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Возвращаясь к нашему примеру, теперь нам нужно будет только настроить наше приложение для общения с полным доменным именем службы (FQDN), чтобы общаться с нашими бэкенд-подами. Таким образом, не будет иметь значения, какой IP-адрес имеют поды и службы. Если под, находящийся за службой, умирает, служба позаботится обо всем, используя A-запись, так как мы сможем сказать нашему фронтенду направлять весь трафик на my-svc. Логика службы позаботится обо всем остальном.
Существует несколько типов служб, которые вы можете создать, когда объявляете объект, который будет создан в Kubernetes. Давайте рассмотрим их, чтобы увидеть, какой из них будет лучше всего подходить для типа работы, которую нам нужно:
ClusterIP: Это служба по умолчанию. Каждый раз, когда вы создаете службу ClusterIP, она создаст службу с внутренним IP-адресом кластера, который будет маршрутизируем только внутри кластера Kubernetes. Этот тип идеален для подов, которые должны общаться друг с другом и не выходить за пределы кластера.
NodePort: Когда вы создаете этот тип службы, по умолчанию будет выделен случайный порт от 30000 до 32767 для перенаправления трафика к конечным подам службы. Вы можете переопределить это поведение, указав порт узла в массиве портов. Как только это определено, вы сможете получить доступ к вашим подам через
LoadBalancer: Чаще всего вы будете запускать Kubernetes на облачном провайдере. Тип LoadBalancer идеален для этих ситуаций, так как вы сможете выделить публичные IP-адреса для вашей службы через API вашего облачного провайдера. Это идеальная служба, когда вы хотите общаться с вашими подами извне вашего кластера. С LoadBalancer вы сможете не только выделить публичный IP-адрес, но и, используя Azure, выделить частный IP-адрес из вашей виртуальной частной сети. Таким образом, вы сможете общаться с вашими подами из интернета или внутренне в вашей частной подсети.
Давайте рассмотрим определение YAML службы:
apiVersion: v1kind: Servicemetadata: name: my-servicespec: selector: app: front-end type: NodePort ports: - name: http port: 80 targetPort: 8080 nodePort: 30024 protocol: TCP
YAML службы очень прост, и спецификации будут варьироваться в зависимости от типа службы, которую вы создаете. Но самое важное, что вам нужно учитывать, это определения портов. Давайте взглянем на них:
- port: Это порт службы, который открывается
- targetPort: Это порт на подах, куда служба отправляет трафик
- nodePort: Это порт, который будет открыт
Хотя мы теперь понимаем, как мы можем общаться с подами в нашем кластере, нам все еще нужно понять, как мы собираемся управлять проблемой потери наших данных каждый раз, когда под завершает работу. Здесь на помощь приходят Постоянные Объемы (PV).
Kubernetes и постоянное хранилище
Постоянное хранилище в мире контейнеров — это серьезная проблема. Единственное хранилище, которое является постоянным между запусками контейнеров, — это слои изображения, и они являются только для чтения. Слой, на котором работает контейнер, является читаемым/записываемым, но все данные в этом слое удаляются, как только контейнер останавливается. С подами это то же самое. Когда контейнер умирает, данные, записанные в него, исчезают.
Kubernetes имеет набор объектов для управления хранилищем между подами. Первым, о котором мы поговорим, являются объемы.
Объемы
Объемы решают одну из самых больших проблем, когда речь идет о постоянном хранилище. Прежде всего, объемы на самом деле не являются объектами, а определением спецификации пода. Когда вы создаете под, вы можете определить объем в поле спецификации пода. Контейнеры в этом поде смогут смонтировать объем в своем пространстве имен монтирования, и объем будет доступен между перезапусками или сбоями контейнеров. Однако объемы привязаны к подам, и если под удаляется, объем также исчезнет. Данные на объеме — это другая история; сохранение данных будет зависеть от бэкенда этого объема.
Kubernetes поддерживает несколько типов объемов или источников объемов и как они называются в спецификациях API, которые варьируются от файловых систем, карт из локального узла, виртуальных дисков облачных провайдеров и объемов, поддерживаемых программным обеспечением. Местные монтирования файловой системы — это самые распространенные, которые вы увидите, когда речь идет о обычных объемах. Важно отметить, что недостатком использования локальной файловой системы узла является то, что данные не будут доступны на всех узлах кластера, а только на том узле, где под был запланирован.
Давайте рассмотрим, как под с объемом определяется в YAML:
apiVersion: v1kind: Podmetadata: name: test-pdspec: containers: - image: k8s.gcr.io/test-webserver name: test-container volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: path: /data type: Directory
Обратите внимание, что есть поле, называемое volumes, под spec, а затем есть еще одно, называемое volumeMounts.
Первое поле (volumes) — это то, где вы определяете объем, который хотите создать для этого пода. Это поле всегда требует имени, а затем источника объема. В зависимости от источника требования будут различаться. В этом примере источником будет hostPath, который является локальной файловой системой узла. hostPath поддерживает несколько типов сопоставлений, начиная от директорий, файлов, блочных устройств и даже сокетов Unix.
Под вторым полем, volumeMounts, у нас есть mountPath, который указывает путь внутри контейнера, куда вы хотите смонтировать ваш объем. Параметр name — это то, как вы указываете поду, какой объем использовать. Это важно, потому что вы можете иметь несколько типов объемов, определенных под volumes, и имя будет единственным способом для пода знать, какой
Вы можете узнать больше о различных типах объемов здесь https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes и в документе справки API Kubernetes (https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.11/#volume-v1-core).
Смерть объемов вместе с подами не является идеальной ситуацией. Нам требуется хранилище, которое сохраняется, и именно так возникла необходимость в PV.
Постоянные объемы, запросы постоянных объемов и классы хранилищ
Основное отличие между объемами и PV заключается в том, что, в отличие от объемов, PV на самом деле являются объектами API Kubernetes, поэтому вы можете управлять ими индивидуально как отдельными сущностями, и, следовательно, они сохраняются даже после удаления пода.
Вы, возможно, задаетесь вопросом, почему этот подраздел включает PV, постоянные объемы запросов (PVC), и классы хранилищ, все смешано вместе. Это потому, что все они зависят друг от друга, и важно понимать, как они взаимодействуют друг с другом для обеспечения хранилища для наших подов.
Давайте начнем с PV и PVC. Как и объемы, PV имеют источник хранилища, поэтому тот же механизм, который применим к объемам, применяется и здесь. У вас будет либо кластер программно определенного хранилища, предоставляющий логический блок номер (LUN), облачный провайдер, предоставляющий виртуальные диски, или даже локальная файловая система для узла Kubernetes, но здесь, вместо того чтобы называться источниками объемов, они называются постоянными объемами типа.
PV в основном похожи на LUN в массиве хранилищ: вы их создаете, но без сопоставления; это просто куча выделенного хранилища, ожидающего использования. PVC — это как сопоставления LUN: они поддерживаются или связаны с PV и также являются тем, что вы фактически определяете, связываете и делаете доступным для пода, который затем может использовать его для своих контейнеров.
Способ использования PVC в подах точно такой же, как и с обычными объемами. У вас есть два поля: одно для указания, какой PVC вы хотите использовать, и другое, чтобы сказать поду, на каком контейнере использовать этот PVC.
YAML для определения объекта API PVC должен содержать следующий код:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: gluster-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi
YAML для пода должен содержать следующий код:
kind: PodapiVersion: v1metadata: name: mypodspec: containers: - name: myfrontend image: nginx volumeMounts: - mountPath: “/mnt/gluster” name: volume volumes: - name: volume persistentVolumeClaim: claimName: gluster-pvc
Когда администратор Kubernetes создает PVC, есть два способа, которыми этот запрос удовлетворяется:
- Статический: Несколько PV уже были созданы, и когда пользователь создает PVC, любой доступный PV, который может удовлетворить требования, будет связан с этим PVC.
- Динамический: Некоторые типы PV могут создавать PV на основе определений PVC. Когда PVC создается, тип PV динамически создаст объект PV и выделит хранилище в бэкенде; это динамическое обеспечение. Проблема с динамическим обеспечением заключается в том, что вам требуется третий тип объекта хранилища Kubernetes, называемый классом хранилища.
Классы хранилища — это как способ уровней вашего хранилища. Вы можете создать класс, который обеспечивает медленные объемы хранилища, или другой с гипербыстрыми SSD-дисками. Однако классы хранилища немного сложнее, чем просто уровни. Как мы упоминали в двух способах создания PVC, классы хранилища — это то, что делает динамическое обеспечение возможным. При работе в облачной среде вы не хотите вручную создавать каждый бэкенд-диск для каждого PV. Классы хранилища настроят то, что называется обеспечивателем, который вызывает плагин объема, необходимый для общения с API вашего облачного провайдера. У каждого обеспечивателя есть свои настройки, чтобы он мог общаться с указанным облачным провайдером или провайдером хранилища.
Вы можете обеспечить классы хранилища следующим образом; это пример класса хранилища, использующего Azure-disk в качестве обеспечивателя дисков:
kind: StorageClassapiVersion: storage.k8s.io/v1metadata: name: my-storage-classprovisioner: kubernetes.io/azure-diskparameters: storageaccounttype: Standard_LRS kind: Shared
Каждый обеспечиватель класса хранилища и тип PV будут иметь различные требования и параметры, как и объемы, и мы уже получили общее представление о том, как они работают и для чего мы можем их использовать. Изучение конкретных классов хранилища и типов PV будет зависеть от вашей среды; вы можете узнать больше о каждом из них, нажав на следующие ссылки:
- https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner
- https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
В этой статье мы узнали, что такое Kubernetes, его компоненты и каковы преимущества использования оркестрации. С этим, идентификация каждого объекта API Kubernetes, их назначения и случаи использования должны быть простыми. Теперь вы должны быть в состоянии понять, как мастер-узлы контролируют кластер и планирование контейнеров в рабочих узлах.
Если вы нашли эту статью полезной, то книга ‘ Hands-On Linux for Architects ’ должна быть полезной для вас. С этой книгой вы охватите все, от компонентов и функциональностей Linux до аппаратной и программной поддержки, что поможет вам реализовать и настроить эффективные решения на базе Linux. Вы получите обзор методологии проектирования Linux и основных концепций проектирования решения. Если вы системный администратор Linux, инженер поддержки Linux, инженер DevOps, консультант по Linux или кто-то, кто хочет изучить или расширить свои знания в архитектуре, эта книга для вас.
Get new posts in your inbox
No spam. Unsubscribe anytime.