Кластеры · 9 min read · Nov 10, 2025
Как развернуть отказоустойчивый кластер с непрерывной или высокой доступностью
Некоторые компании не могут позволить себе, чтобы их услуги были недоступны. В случае сбоя сервера оператор сотовой связи может столкнуться с простоем системы биллинга, что приведет к потере связи для всех его клиентов. Признание потенциального воздействия таких ситуаций приводит к необходимости всегда иметь план Б.
В этой статье мы освещаем различные способы защиты от сбоев серверов, а также архитектуры, используемые для развертывания VMmanager Cloud, панели управления для создания кластера высокой доступности.

Предисловие
Терминология в области отказоустойчивости кластеров различается от сайта к сайту. Чтобы избежать путаницы в различных терминах и определениях, давайте определим те, которые будут использоваться в данной статье:
- Отказоустойчивость (FT) — это способность системы продолжать свою работу после сбоя одного из ее компонентов.
- Кластер — это группа серверов (узлов кластера), соединенных через каналы связи.
- Отказоустойчивый кластер (FTC) — это кластер, в котором сбой одного сервера не приводит к полной недоступности всего кластера. Функции сбойного узла автоматически перераспределяются между оставшимися узлами.
- Непрерывная доступность (CA) означает, что пользователь может использовать услугу без каких-либо таймаутов. Не имеет значения, сколько времени прошло с момента сбоя узла.
- Высокая доступность (HA) означает, что пользователь может столкнуться с таймаутами услуги в случае, если один из узлов выходит из строя; однако система будет автоматически восстановлена с минимальным временем простоя.
- CA кластер — это кластер непрерывной доступности.
- HA кластер — это кластер высокой доступности.
Предположим, что необходимо развернуть кластер, состоящий из 10 узлов с виртуальными машинами, работающими на каждом узле. Цель — защитить виртуальные машины после сбоя сервера. Используются серверы с двумя процессорами для максимизации вычислительной плотности стоек.
На первый взгляд, наиболее привлекательным вариантом для компании является развертывание кластера непрерывной доступности, когда услуга все еще предоставляется после сбоя оборудования. Действительно, непрерывная доступность необходима, если вам нужно поддерживать работу системы биллинга или автоматизировать непрерывный производственный процесс. Однако у этого подхода также есть свои ловушки и подводные камни, которые будут рассмотрены ниже.
Непрерывная доступность
Непрерывность услуги возможна только в том случае, если создана точная копия физической или виртуальной машины с этой услугой, которая доступна в любое время. Такая модель избыточности называется 2N. Создание копии сервера после сбоя оборудования займет время, что приведет к таймауту услуги. Более того, в этом случае невозможно будет получить дамп ОЗУ с вышедшего из строя сервера, что означает, что вся информация, содержащаяся там, будет утеряна.
Существуют два метода обеспечения CA: на аппаратном и программном уровне. Давайте подробнее рассмотрим каждый из них.
Аппаратный метод представляет собой двойной сервер, где все компоненты дублируются, и вычисления выполняются одновременно и независимо. Синхронизация достигается с помощью выделенного узла, который проверяет результаты, поступающие с обеих частей. Если узел обнаруживает какое-либо несоответствие, он пытается определить проблему и исправить ошибки. Если ошибку нельзя исправить, система отключает вышедший из строя модуль.
Stratus, производитель серверов CA, гарантирует, что общее время простоя системы не превышает 32 секунд в год. Такие результаты могут быть достигнуты с использованием специального оборудования. По словам представителей Stratus, стоимость одного CA сервера с двумя процессорами для каждого синхронизированного модуля составляет около 160 000 долларов в зависимости от характеристик. Расширенная цена для всего CA кластера в этом случае составит 1 600 000 долларов.
Программный метод
Наиболее популярным программным инструментом для развертывания кластера непрерывной доступности на момент написания статьи является VMware vSphere. Технология непрерывной доступности этого продукта называется Fault Tolerance.
В отличие от аппаратного метода, эта технология имеет определенные требования, такие как:
- Процессор на физическом хосте: - Intel с архитектурой Sandy Bridge (или новее). Avoton не поддерживается.
- AMD Bulldozer (или новее).
- Машины с отказоустойчивостью должны быть подключены к одной сети 10 Гбит с низкой задержкой. VMware настоятельно рекомендует использовать выделенную сеть.
- Не более 4 виртуальных процессоров на ВМ.
- Не более 8 виртуальных процессоров на физическом хосте.
- Не более 4 виртуальных машин на физическом хосте.
- Снимки виртуальных машин недоступны.
- Storage vMotion недоступен.
Полный список ограничений и несовместимостей можно найти в официальной документации.
Лицензирование vSphere основано на физических процессорах. Цена начинается от 1750 долларов за лицензию + 550 долларов за годовую подписку и поддержку. Автоматизация управления кластером также требует VMware vCenter Server, стоимость которого составляет более 8000 долларов. Модель 2N используется для обеспечения непрерывной доступности, поэтому необходимо приобрести 10 реплицированных серверов с лицензиями для каждого из них, чтобы построить кластер из 10 узлов с виртуальными машинами.
Общая стоимость программного обеспечения составит 2[ Количество процессоров на сервер ](10[ Количество узлов с виртуальными машинами ]+10[ Количество реплицированных узлов ])(1750+550)[ Стоимость лицензии за каждый процессор ]+8000[ Стоимость VMware vCenter Server ]=$100 000. Все цены округлены.
Конкретные конфигурации узлов не описаны в этой статье, так как компоненты серверов всегда различаются в зависимости от назначения кластера. Сетевое оборудование также не описано, так как оно должно быть идентичным в каждом случае. Эта статья сосредоточена на тех компонентах, которые определенно будут различаться, а именно на стоимости лицензии.
Также важно упомянуть продукты, которые больше не разрабатываются и не поддерживаются.
Продукт под названием Remus основан на виртуализации Xen. Это бесплатное решение с открытым исходным кодом, которое использует технологию микро-снимков. К сожалению, его документация давно не обновлялась: Руководство по установке содержит инструкции для Ubuntu 12.10, срок службы которой был завершен в 2014 году. Даже поиск в Google не нашел ни одной компании, использующей Remus в своей работе.
Были предприняты попытки модифицировать QEMU для создания кластеров непрерывной доступности на этой технологии. Существуют два проекта, которые объявили о своей работе в этом направлении.
Первый из них — Kemari, продукт с открытым исходным кодом, возглавляемый Ёшиаки Тамурой. Этот проект намеревался использовать живую миграцию QEMU. Последний коммит был сделан в феврале 2011 года, что предполагает, что разработка достигла тупика и не будет продолжена.
Второй продукт — Micro Checkpointing, проект с открытым исходным кодом, основанный Майклом Хайнсом. За последний год в его журнале изменений не было найдено никакой активности, что напоминает проект Kemari.
Эти факты позволяют нам сделать вывод, что на данный момент просто нет возможности для непрерывной доступности на виртуализации KVM.
Несмотря на все преимущества систем непрерывной доступности, существует множество препятствий на пути к развертыванию и эксплуатации таких решений. Тем не менее, в некоторых случаях может потребоваться отказоустойчивость, но без необходимости быть постоянно доступным. Такие сценарии позволяют использовать кластеры с высокой доступностью.
Высокая доступность
Кластер высокой доступности обеспечивает отказоустойчивость, автоматически определяя, если оборудование вышло из строя, и затем запускает услугу на доступном узле.
Высокая доступность не поддерживает синхронизацию процессоров, запущенных на узлах, и не всегда позволяет синхронизировать локальные диски. С учетом этого рекомендуется размещать диски, используемые узлами, в отдельном независимом хранилище, таком как сетевое хранилище.
Причина ясна: узел не может быть достигнут после его сбоя, и информация с его устройства хранения не может быть извлечена. Система хранения данных также должна быть отказоустойчивой, в противном случае не будет возможности для высокой доступности. В результате кластер высокой доступности состоит из двух подсистем:
- Вычислительный кластер, состоящий из узлов с виртуальными машинами
- Хранилище кластера с дисками, которые используются вычислительными узлами.
На данный момент существуют следующие решения, используемые для реализации кластеров высокой доступности с виртуальными машинами на узлах кластера:
- Heartbeat, версия 1.? с DRBD;
- Pacemaker;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualization;
- Кластерирование Windows Server Failover с ролью сервера Hyper-V;
- VMmanager Cloud.
Давайте подробнее рассмотрим VMmanager Cloud.
VMmanager Cloud
VMmanager Cloud — это продукт, который позволяет развертывать кластеры высокой доступности и использует виртуализацию QEMU-KVM. Эта технология была выбрана, потому что она активно разрабатывается и поддерживается и позволяет устанавливать любую операционную систему на виртуальную машину. Продукт использует Corosync для определения доступности кластера. Если один из серверов выходит из строя, VMmanager распределяет его виртуальные машины между оставшимися узлами по одной.
В упрощенной форме этот механизм работает следующим образом:
- Система определяет узел кластера с наименьшим количеством виртуальных машин.
- Она проверяет, достаточно ли ОЗУ для размещения машины.
- Если на узле достаточно памяти для соответствующей машины, VMmanager создает новую виртуальную машину на этом узле.
- Если памяти недостаточно, система проверяет другие узлы с большим количеством виртуальных машин.
Тестирование нескольких аппаратных конфигураций и опрос многих текущих пользователей VMmanager Cloud показали, что обычно требуется 45-90 секунд для распределения и восстановления работы всех ВМ с вышедшего из строя узла, в зависимости от производительности оборудования.
Рекомендуется выделить один или несколько узлов в качестве защиты от чрезвычайных ситуаций и не развертывать ВМ на этих узлах в ходе обычной работы. Это минимизирует шансы нехватки ресурсов на живых узлах кластера для добавления виртуальных машин с вышедшего из строя узла. В случае, если используется только один резервный узел, такая модель безопасности называется N+1.
VMmanager Cloud поддерживает следующие типы хранилищ: файловая система, LVM, Сетевой LVM, iSCSI и Ceph [в частности RBD (RADOS Block Device), одна из реализаций Ceph]. Последние три используются для высокой доступности.
Одна бессрочная лицензия на десять рабочих узлов и один резервный узел стоит €3520, или $3865 на сегодняшний день (одна лицензия стоит €320 за узел независимо от количества процессоров). Лицензия включает один год бесплатных обновлений; начиная со второго года обновления предоставляются по подписке по цене €880 в год для всего кластера.
Давайте проверим, как VMmanager Cloud уже использовался для развертывания кластеров высокой доступности.
FirstByte
FirstByte начала предоставлять облачный хостинг в феврале 2016 года. Изначально их кластер был построен на OpenStack; однако нехватка специалистов для этой системы как по их доступности, так и по стоимости заставила их искать альтернативное решение. Новая система для построения кластера высокой доступности должна была соответствовать следующим требованиям:
- Возможность развертывания KVM виртуальных машин.
- Интеграция с Ceph.
- Интеграция с системой биллинга для предложения существующих услуг.
- Доступная стоимость лицензии.
- Поддержка со стороны разработчика программного обеспечения.
VMmanager Cloud соответствовал всем требованиям.
Отличительные особенности кластера FirstByte:
- Передача данных основана на технологии Ethernet и оборудовании Cisco.
- Маршрутизация выполняется с использованием Cisco ASR9001. Кластер использует около 50000 IPv6 адресов.
- Скорость соединения между вычислительными узлами и коммутаторами составляет 10 Гбит/с.
- Скорость передачи данных между коммутаторами и узлами хранения составляет 20 Гбит/с, с двумя объединенными каналами по 10 Гбит/с каждый.
- Отдельная линия на 20 Гбит используется между стойками с узлами хранения для репликации.
- На всех узлах хранения установлены диски SAS в сочетании с SSD.
- Тип хранения — RBD.
Схема системы представлена ниже:
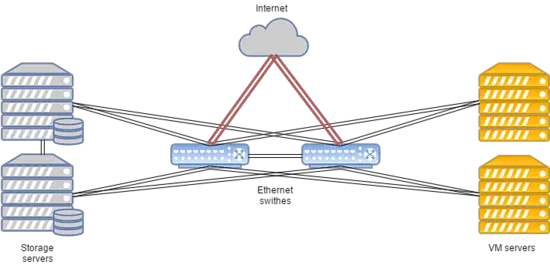
Такая конфигурация подходит для хостинга популярных веб-сайтов, игровых серверов и баз данных с нагрузкой выше средней.
FirstVDS
FirstVDS предоставляет услуги отказоустойчивого кластера, который был запущен в сентябре 2015 года.
VMmanager Cloud был выбран для этого кластера по следующим причинам:
- Солидный опыт использования панелей управления ISPsystem.
- Интеграция с BILLmanager по умолчанию.
- Высокое качество технической поддержки.
- Интеграция с Ceph.
Их кластер имеет следующие особенности:
- Передача данных основана на сети Infiniband со скоростью соединения 56 Гбит/с;
- Сеть Infiniband построена на оборудовании Mellanox;
- Узлы хранения имеют SSD-диски;
- Тип хранения — RBD.
Систему можно разложить следующим образом:
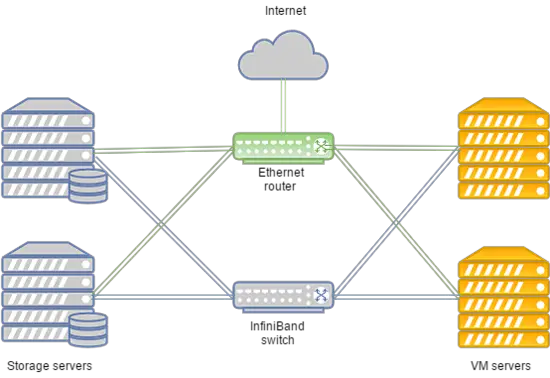
В случае сбоя сети Infiniband соединение между хранилищем дисков ВМ и вычислительными серверами устанавливается через сеть Ethernet, развернутую на оборудовании Juniper. Новое соединение настраивается автоматически.
Благодаря высокой скорости связи с хранилищем этот кластер отлично подходит для хостинга веб-сайтов с ультравысокой нагрузкой, потокового видео и контента, а также больших данных.
Заключение
Подведем ключевые выводы статьи.
Кластер непрерывной доступности необходим, когда каждая секунда простоя приносит значительные убытки. Если допустимо иметь простой в 5 минут при развертывании виртуальных машин на резервном узле, кластер высокой доступности может быть хорошим вариантом, снижающим аппаратные и программные затраты.
Также важно напомнить, что единственный способ достичь отказоустойчивости — это избыточность. Убедитесь, что вы реплицируете свои серверы, оборудование для передачи данных и каналы связи, каналы доступа в Интернет и электропитание. Реплицируйте все, что можете. Такие меры позволяют устранить узкие места и потенциальные точки отказа, которые могут вызвать простой всей системы. Приняв вышеуказанные меры, вы можете быть уверены, что у вас есть отказоустойчивый кластер, устойчивый к сбоям.
Если вы считаете, что модель высокой доступности соответствует вашим требованиям и VMmanager Cloud является хорошим инструментом для ее реализации, пожалуйста, обратитесь к руководству по установке и документации, чтобы узнать больше о системе. Я желаю вам безотказной и непрерывной работы!**
Get new posts in your inbox
No spam. Unsubscribe anytime.