Установка Hadoop · 9 min read · Dec 21, 2025
Как установить Apache Hadoop на Ubuntu 22.04

Apache Hadoop — это фреймворк с открытым исходным кодом для обработки и хранения больших данных. В современных отраслях Hadoop стал стандартным фреймворком для больших данных. Hadoop разработан для работы на распределенных системах с сотнями или даже тысячами кластеризованных компьютеров или выделенных серверов. Учитывая это, Hadoop может обрабатывать большие наборы данных с высокой объемностью и сложностью как для структурированных, так и для неструктурированных данных.
Каждое развертывание Hadoop содержит следующие компоненты:
- Hadoop Common: Общие утилиты, которые поддерживают другие модули Hadoop.
- Hadoop Distributed File System (HDFS): Распределенная файловая система, которая обеспечивает высокопроизводительный доступ к данным приложений.
- Hadoop YARN: Фреймворк для планирования задач и управления ресурсами кластера.
- Hadoop MapReduce: Система на основе YARN для параллельной обработки больших наборов данных.
В этом руководстве мы установим последнюю версию Apache Hadoop на сервер Ubuntu 22.04. Hadoop устанавливается на сервер с одним узлом, и мы создаем Псевдораспределенный режим развертывания Hadoop.
Предварительные требования
Чтобы завершить это руководство, вам понадобятся следующие требования:
- Сервер Ubuntu 22.04 - В этом примере используется сервер Ubuntu с именем хоста ‘hadoop’ и IP-адресом ‘192.168.5.100’.
- Непользователь с правами администратора sudo/root.
Установка Java OpenJDK
Hadoop — это большой проект под управлением Фонда Apache Software, он в основном написан на Java. На момент написания последняя версия Hadoop — v3.3.4, которая полностью совместима с Java v11.
Java OpenJDK 11 доступен по умолчанию в репозитории Ubuntu, и вы установите его через APT.
Чтобы начать, выполните следующую команду apt для обновления и обновления списков/репозиториев пакетов на вашей системе Ubuntu.
sudo apt updateТеперь установите Java OpenJDK 11 с помощью следующей команды apt. В репозитории Ubuntu 22.04 пакет ‘default-jdk’ относится к Java OpenJDK v11.
sudo apt install default-jdkКогда будет предложено, введите y для подтверждения и нажмите ENTER, чтобы продолжить. Установка Java OpenJDK начнется.
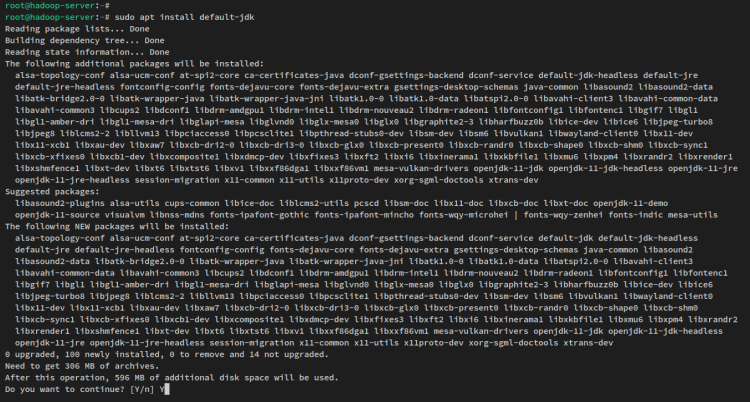
После установки Java выполните следующую команду, чтобы проверить версию Java. Вы должны получить установленную Java OpenJDK 11 на вашей системе Ubuntu.
java -versionТеперь, когда Java OpenJDK установлена, вы создадите нового пользователя с аутентификацией SSH без пароля, который будет использоваться для выполнения процессов и служб Hadoop.
Настройка пользователя и аутентификация SSH без пароля
Apache Hadoop требует, чтобы служба SSH работала на системе. Это будет использоваться скриптами Hadoop для управления удаленным демоном Hadoop на удаленном сервере. На этом этапе вы создадите нового пользователя, который будет использоваться для выполнения процессов и служб Hadoop, а затем настроите аутентификацию SSH без пароля.
Если у вас нет установленного SSH на вашей системе, выполните следующую команду apt для установки SSH. Пакет ‘pdsh‘ — это многопоточный клиент удаленной оболочки, который позволяет выполнять команды на нескольких хостах в параллельном режиме.
sudo apt install openssh-server openssh-client pdshТеперь выполните следующую команду для создания нового пользователя ‘hadoop’ и установки пароля для пользователя ‘hadoop’.
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoopВведите новый пароль для пользователя ‘hadoop‘ и повторите пароль.
Затем добавьте пользователя ‘hadoop’ в группу ‘sudo‘ с помощью команды usermod ниже. Это позволяет пользователю ‘hadoop’ выполнять команду ‘sudo’.
sudo usermod -aG sudo hadoopТеперь, когда пользователь ‘hadoop’ создан, войдите в пользователя ‘hadoop‘ с помощью следующей команды.
su - hadoopПосле входа ваш запрос станет таким: “hadoop@hostname..“.
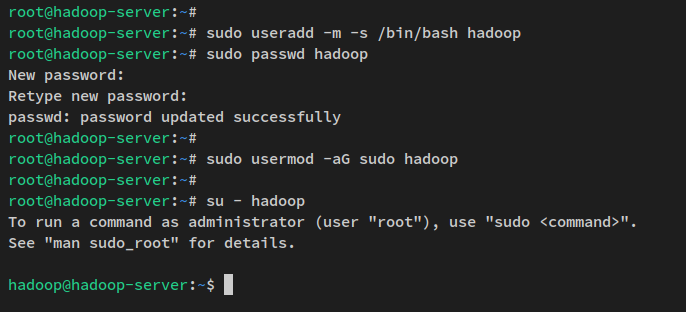
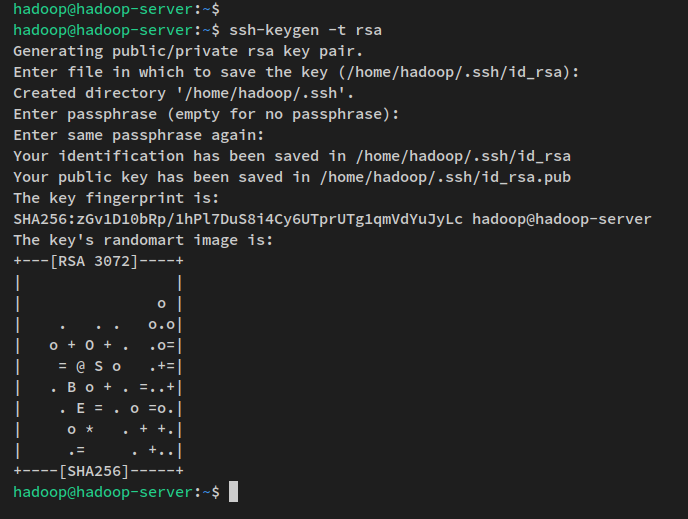
Далее выполните следующую команду для генерации SSH открытого и закрытого ключа. Когда будет предложено установить пароль для ключа, нажмите ENTER, чтобы пропустить.
ssh-keygen -t rsaSSH-ключ теперь сгенерирован в директории ~/.ssh. id_rsa.pub — это открытый ключ SSH, а файл ‘id_rsa’ — это закрытый ключ.
Вы можете проверить сгенерированный SSH-ключ с помощью следующей команды.
ls ~/.ssh/Далее выполните следующую команду, чтобы скопировать открытый ключ SSH ‘id_rsa.pub‘ в файл ‘authorized_keys‘ и изменить разрешение по умолчанию на 600.
В ssh файл ‘authorized_keys‘ — это то место, где вы храните открытый ключ ssh, который может содержать несколько открытых ключей. Любой, у кого есть открытый ключ, хранящийся в файле ‘authorized_keys‘ и имеющий правильный закрытый ключ, сможет подключиться к серверу как пользователь ‘hadoop‘ без пароля.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys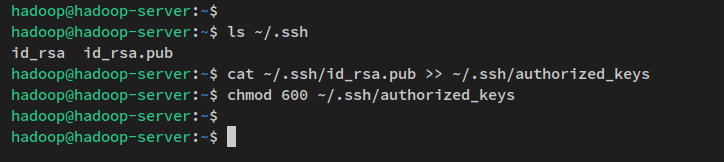
С завершением конфигурации SSH без пароля вы можете проверить, подключившись к локальной машине с помощью следующей команды ssh.
ssh localhostВведите yes для подтверждения и добавления отпечатка SSH, и вы будете подключены к серверу без аутентификации по паролю.
Теперь, когда пользователь ‘hadoop‘ создан и аутентификация SSH без пароля настроена, вы перейдете к установке Hadoop, загрузив бинарный пакет Hadoop.
Загрузка Hadoop
После создания нового пользователя и настройки аутентификации SSH без пароля вы можете загрузить бинарный пакет Apache Hadoop и настроить каталог установки для него. В этом примере вы загрузите hadoop v3.3.4, а целевой каталог установки будет каталогом ‘/usr/local/hadoop‘.
Выполните следующую команду wget, чтобы загрузить бинарный пакет Apache Hadoop в текущий рабочий каталог. Вы должны получить файл ‘hadoop-3.3.4.tar.gz‘ в вашем текущем рабочем каталоге.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gzДалее извлеките пакет Apache Hadoop ‘hadoop-3.3.4.tar.gz’ с помощью следующей команды tar. Затем переместите извлеченный каталог в ‘/usr/local/hadoop‘.
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoopНаконец, измените владельца каталога установки Hadoop ‘/usr/local/hadoop’ на пользователя ‘hadoop‘ и группу ‘hadoop‘.
sudo chown -R hadoop:hadoop /usr/local/hadoop
На этом этапе вы загрузили бинарный пакет Apache Hadoop и настроили каталог установки Hadoop. Учитывая это, вы можете начать настраивать установку Hadoop.
Настройка переменных окружения Hadoop
Откройте файл конфигурации ‘~/.bashrc‘ с помощью команды редактора nano ниже.
nano ~/.bashrcДобавьте следующие строки в файл. Обязательно разместите следующие строки в конце файла.
# Переменные окружения Hadoop
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Сохраните файл и выйдите из редактора, когда закончите.
Далее выполните следующую команду, чтобы применить новые изменения в файле ‘~/.bashrc‘.
source ~/.bashrcПосле выполнения команды новые переменные окружения будут применены. Вы можете проверить, проверив каждую переменную окружения с помощью следующей команды. И вы должны получить вывод каждой переменной окружения.
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTSДалее вы также настроите переменную окружения JAVA_HOME в скрипте ‘hadoop-env.sh‘.
Откройте файл ‘hadoop-env.sh’ с помощью следующей команды редактора nano. Файл ‘hadoop-env.sh’ доступен в каталоге ‘$HADOOP_HOME‘, который относится к каталогу установки Hadoop ‘/usr/local/hadoop‘.
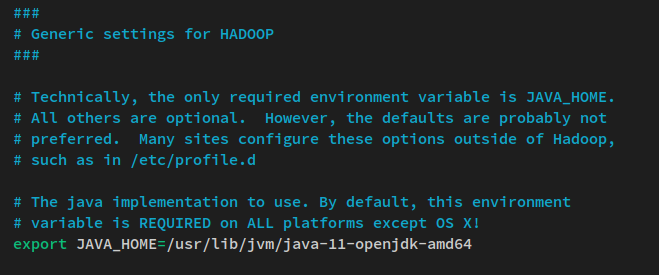
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shРаскомментируйте строку переменной окружения JAVA_HOME и измените значение на каталог установки Java OpenJDK ‘/usr/lib/jvm/java-11-openjdk-amd64‘.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64Сохраните файл и выйдите из редактора, когда закончите.
С конфигурацией переменных окружения выполните следующую команду, чтобы проверить версию Hadoop на вашей системе. Вы должны увидеть Apache Hadoop 3.3.4, установленный на вашей системе.
hadoop version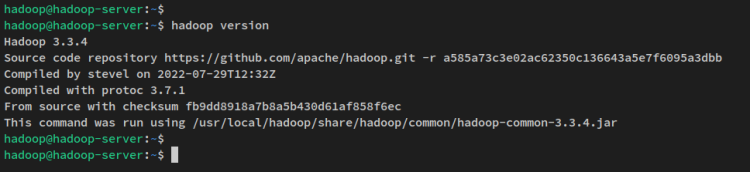
На этом этапе вы готовы настроить и сконфигурировать кластер Hadoop, который может быть развернут в нескольких режимах.
Настройка кластера Apache Hadoop: Псевдораспределенный режим
В Hadoop вы можете создать кластер в трех разных режимах:
- Локальный режим (Standalone) - стандартная установка Hadoop, которая запускается как один процесс Java и в нераспределенном режиме. С этим вы можете легко отлаживать процесс Hadoop.
- Псевдораспределенный режим - это позволяет вам запустить кластер Hadoop в распределенном режиме даже с только одним узлом/сервером. В этом режиме процессы Hadoop будут выполняться в отдельных процессах Java.
- Полностью распределенный режим - большое развертывание Hadoop с несколькими или даже тысячами узлов/серверов. Если вы хотите запустить Hadoop в производственной среде, вам следует использовать Hadoop в полностью распределенном режиме.
В этом примере вы настроите кластер Apache Hadoop с псевдораспределенным режимом на одном сервере Ubuntu. Для этого вам нужно будет внести изменения в некоторые конфигурации Hadoop:
- core-site.xml - Это будет использоваться для определения NameNode для кластера Hadoop.
- hdfs-site.xml - Эта конфигурация будет использоваться для определения DataNode в кластере Hadoop.
- mapred-site.xml - Конфигурация MapReduce для кластера Hadoop.
- yarn-site.xml - Конфигурация ResourceManager и NodeManager для кластера Hadoop.
Настройка NameNode и DataNode
Сначала вы настроите NameNode и DataNode для кластера Hadoop.
Откройте файл ‘$HADOOP_HOME/etc/hadoop/core-site.xml‘ с помощью следующей команды редактора nano.
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlДобавьте следующие строки в файл. Обязательно измените IP-адрес NameNode, или вы можете заменить его на ‘0.0.0.0’, чтобы NameNode работал на всех интерфейсах и IP-адресах.
fs.defaultFS
hdfs://192.168.5.100:9000
Сохраните файл и выйдите из редактора, когда закончите.
Далее выполните следующую команду, чтобы создать новые каталоги, которые будут использоваться для DataNode в кластере Hadoop. Затем измените владельца каталогов DataNode на пользователя ‘hadoop‘.
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsПосле этого откройте файл ‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’ с помощью следующей команды редактора nano.
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlДобавьте следующую конфигурацию в файл. В этом примере вы настроите кластер Hadoop в одном узле, поэтому вы должны изменить значение ‘dfs.replication’ на ‘1’. Также вы должны указать каталог, который будет использоваться для DataNode.
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
Сохраните файл и выйдите из редактора, когда закончите.
С настроенными NameNode и DataNode выполните следующую команду, чтобы отформатировать файловую систему Hadoop.
hdfs namenode -formatВы получите вывод, подобный этому:
Далее запустите NameNode и DataNode с помощью следующей команды. NameNode будет работать на IP-адресе сервера, который вы настроили в файле ‘core-site.xml’.
start-dfs.shВы увидите вывод, подобный этому:
Теперь, когда NameNode и DataNode работают, вы можете проверить оба процесса через веб-интерфейс.
Веб-интерфейс NameNode Hadoop работает на порту ‘9870‘. Поэтому откройте веб-браузер и перейдите по IP-адресу сервера, добавив порт 9870 (например: http://192.168.5.100:9870/).
Теперь вы должны получить страницу, подобную следующему скриншоту - NameNode в настоящее время активен.
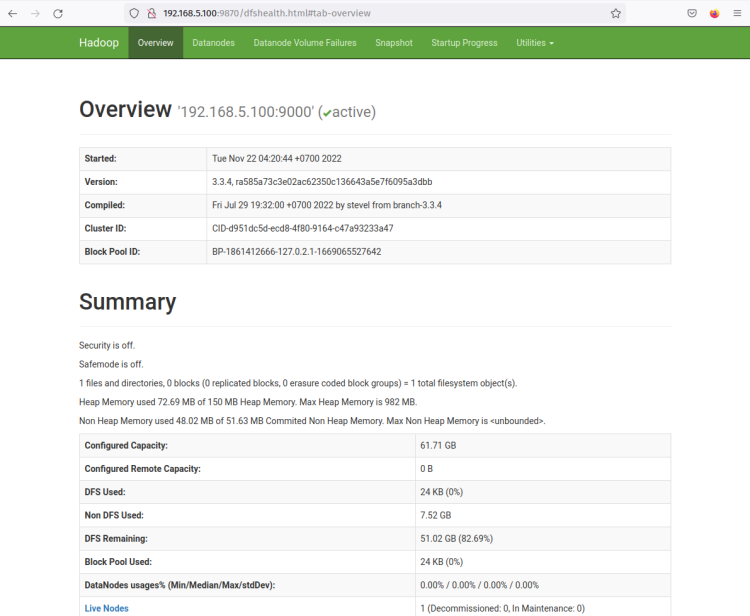
Теперь нажмите на меню ‘Datanodes’, и вы должны увидеть текущий DataNode, который активен в кластере Hadoop. Следующий скриншот подтверждает, что DataNode работает на порту ‘9864‘ в кластере Hadoop.
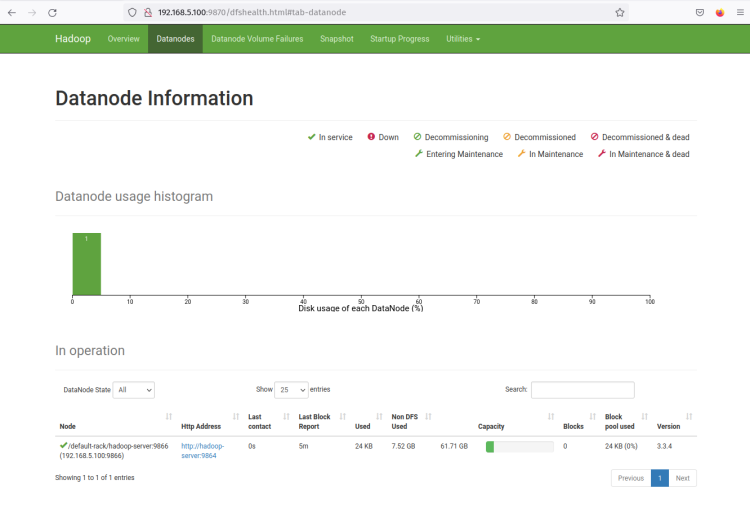
Нажмите на ‘Http Address’ DataNode, и вы должны получить новую страницу с подробной информацией о DataNode. Следующий скриншот подтверждает, что DataNode работает с каталогом объема ‘/home/hadoop/hdfs/datanode‘.
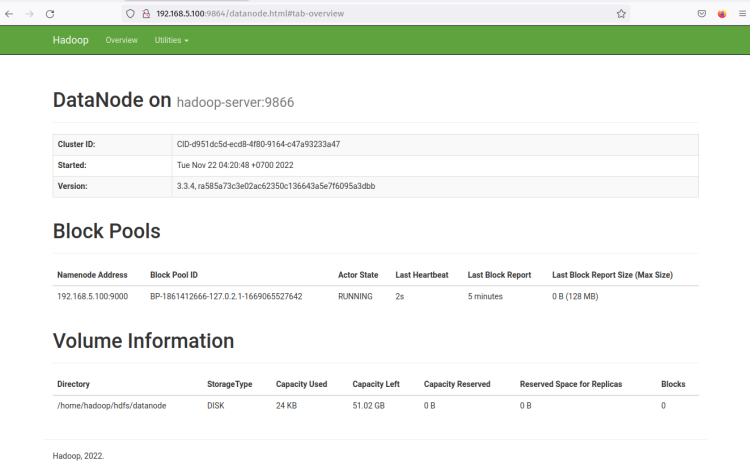
С работающими NameNode и DataNode вы далее настроите и запустите MapReduce на менеджере Yarn (Yet Another ResourceManager и NodeManager).
Yarn Manager
Чтобы запустить MapReduce на Yarn в псевдораспределенном режиме, вам нужно внести несколько изменений в конфигурационные файлы.
Откройте файл ‘$HADOOP_HOME/etc/hadoop/mapred-site.xml‘ с помощью следующей команды редактора nano.
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlДобавьте следующие строки в файл. Обязательно измените mapreduce.framework.name на ‘yarn’.
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
Сохраните файл и выйдите из редактора, когда закончите.
Далее откройте конфигурацию Yarn ‘$HADOOP_HOME/etc/hadoop/yarn-site.xml‘ с помощью следующей команды редактора nano.
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlИзмените конфигурацию по умолчанию на следующие настройки.
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
Сохраните файл и выйдите из редактора, когда закончите.
Теперь выполните следующую команду, чтобы запустить демоны Yarn. И вы должны увидеть, что и ResourceManager, и NodeManager запускаются.
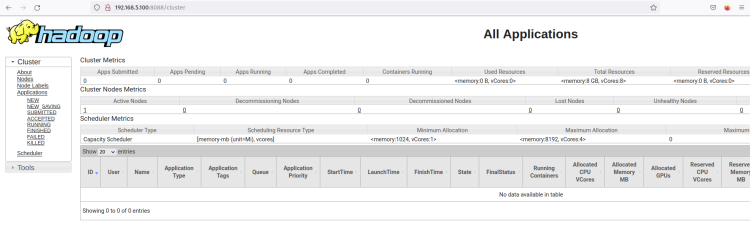
start-yarn.shResourceManager должен работать на порту по умолчанию 8088. Вернитесь в веб-браузер и перейдите по IP-адресу сервера, добавив порт ResourceManager ‘8088’ (например: http://192.168.5.100:8088/).
Вы должны увидеть веб-интерфейс менеджера ресурсов Hadoop. Отсюда вы можете контролировать все запущенные процессы внутри кластера Hadoop.
Нажмите на меню Узлы, и вы должны увидеть текущий работающий узел в кластере Hadoop.
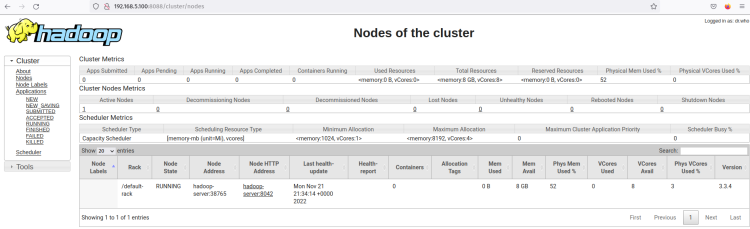
Теперь кластер Hadoop работает в псевдораспределенном режиме. Это означает, что каждый процесс Hadoop работает как один процесс на одном узле сервера Ubuntu 22.04, включая NameNode, DataNode, MapReduce и Yarn.
Заключение
В этом руководстве вы установили Apache Hadoop на одном сервере Ubuntu 22.04. Вы установили Hadoop с включенным псевдораспределенным режимом, что означает, что каждый компонент Hadoop работает как один процесс Java в системе. В этом руководстве вы также узнали, как настроить Java, настроить системные переменные окружения и настроить аутентификацию SSH без пароля через открытый и закрытый ключ SSH.
Этот тип развертывания Hadoop, псевдораспределенный режим, рекомендуется только для тестирования. Если вы хотите распределенную систему, которая может обрабатывать средние или большие наборы данных, вы можете развернуть Hadoop в кластерном режиме, который требует больше вычислительных систем и обеспечивает высокую доступность для вашего приложения.
Get new posts in your inbox
No spam. Unsubscribe anytime.