Команды Linux · 5 min read · Sep 19, 2025
Учебник по команде Linux Uniq для начинающих (10 примеров)
Если вы пользователь командной строки Linux, и ваша работа связана с текстовыми файлами, вы должны знать (если еще не знаете), что существует множество утилит командной строки, которые могут быть очень полезны в различных ситуациях. Например, существует инструмент под названием ‘uniq’, который сообщает или даже удаляет повторяющиеся строки в файле.
В этой статье мы обсудим ‘uniq’ через простые для понимания примеры. Но прежде чем мы это сделаем, стоит упомянуть, что все примеры и инструкции, упомянутые в этом учебнике, были протестированы на Ubuntu 16.04LTS.
Команда Linux Uniq
Как уже упоминалось в начале, команда uniq сообщает или пропускает повторяющиеся строки. Вот общий синтаксис этой команды:
uniq [OPTION]… [INPUT [OUTPUT]]
Согласно странице man утилиты: “Фильтрует соседние совпадающие строки из INPUT (или стандартного ввода), записывая в OUTPUT (или стандартный вывод). Без опций совпадающие строки объединяются с первым вхождением.”
Следующие примеры помогут вам лучше понять инструмент.
1. Как удалить повторяющиеся строки с помощью команды uniq
Предположим, файл содержит следующие строки:
Очевидно, что каждая строка повторяется. Теперь давайте запустим Uniq на этом файле и посмотрим, что произойдет.
uniq file1Как вы можете видеть, вывод, который сгенерировала команда, не содержит повторяющихся строк. Обратите внимание, что оригинальный файл - ‘file1’ в нашем случае - остается неизменным. Вы можете перенаправить вывод инструмента в другой файл, если хотите сохранить и работать с ним.
2. Как отобразить количество повторений для каждой строки
Если хотите, вы также можете заставить uniq отображать в выводе количество раз, когда строка повторяется. Это можно сделать, используя опцию командной строки -c. Например, следующая команда:
uniq -c file1выдает следующий вывод:
Как вы можете видеть, количество повторений для каждой строки предшествует ей в выводе.
3. Как напечатать только дублирующиеся строки с помощью uniq
Чтобы заставить uniq печатать только дублирующиеся строки, используйте опцию командной строки -D. Например, предположим, что file1 теперь содержит дополнительную строку внизу (обратите внимание, что эта строка не повторяется).
Теперь, когда я запускаю следующую команду:
uniq -D file1Выдается следующий вывод:
Как вы можете видеть, опция -D заставляет uniq отображать все повторяющиеся строки в выводе, включая все их повторения. Чтобы лучше разделить, вы можете иметь пустую строку после каждой группы повторяющихся строк, что можно сделать с помощью опции –all-repeated.
uniq –all-repeated[=METHOD] file1
Эта опция требует, чтобы пользователь ввел имя метода. Значения могут быть prepend (для добавления пустой строки) или separate (для добавления пустой строки). Например, вот эта опция в действии с методом prepend.

Двигаясь дальше, если вы хотите, чтобы инструмент отображал только одну дублирующуюся строку на группу, тогда вы можете использовать опцию -d. Вот пример этого:
Очевидно, что в выводе была отображена только одна повторяющаяся строка из каждой группы.
4. Как заставить uniq избегать сравнения первых нескольких полей
Иногда, в зависимости от ситуации, схожесть двух строк определяется небольшой частью этих строк. Например, рассмотрим содержимое следующего файла:
Теперь предположим, что строки считаются схожими или различными на основе их второго поля (HTF или FF), и вы хотите сообщить об этом uniq, тогда это можно сделать с помощью опции командной строки -f.
uniq -f [number-of-fields-to-skip] [file-name]Опция -f требует, чтобы вы передали число, представляющее количество полей, которые вы хотите, чтобы команда пропустила. Например, в нашем случае мы можем передать ‘1’ в качестве аргумента для -f, так как только первое поле мы хотим, чтобы uniq пропустил.
uniq -f 1 file1Вывод четко показывает, что uniq считал как повторяющиеся как первую, так и третью строки на основе их соответствующих вторых полей.
5. Как заставить uniq отображать все строки, разделяя повторяющиеся группы пустой строкой
Если требуется отображать все строки, разделяя повторяющиеся группы строк пустой строкой, тогда вы можете использовать опцию –group. Как и опция –all-repeated, о которой мы говорили ранее, –group также требует, чтобы вы указали позицию пустой строки (prepend, append или both).
Вот пример:
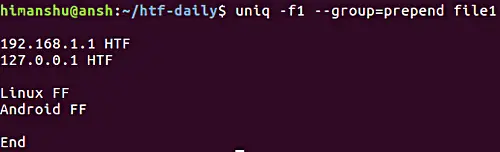
Обратите внимание, что опцию -f мы уже обсуждали в предыдущем разделе.
6. Как заставить uniq печатать только неповторяющиеся строки
Как вы уже поняли, по умолчанию команда uniq отображает только повторяющиеся строки в выводе. Но если вы хотите, вы можете вместо этого заставить ее отображать только неповторяющиеся или уникальные строки. Это можно сделать с помощью опции командной строки -u.
uniq -u [file-name]Итак, в нашем случае:
uniq -u file1
Вот пример:
Обратите внимание, что опцию -f мы уже обсуждали в разделе/пункте номер 4.
7. Как заставить uniq избегать сравнения заданного числа начальных символов
В одном из наших предыдущих примеров мы обсуждали, как вы можете заставить uniq пропускать поля. Однако, если хотите, вы также можете заставить инструмент пропускать заданное количество начальных символов. Эта функция может быть доступна с помощью опции командной строки -s.
uniq -s [number-of-char] filename
Например, предположим, что файл содержит следующие строки:
Теперь, если вы хотите, чтобы uniq пропустил первые 4 символа в каждой строке перед сравнением, тогда это можно сделать следующим образом:
uniq -s 4 file1
Вот эта команда в действии:
Таким образом, вы можете видеть, что четвертая строка (faq_forge), которая изначально была, была пропущена в выводе. Это потому, что после пропуска первых четырех символов третья и четвертая строки были одинаковыми и, следовательно, считались повторяющимися uniq.
8. Как ограничить сравнение заданным количеством символов
Аналогично тому, как вы пропускаете символы, вы также можете попросить uniq ограничить сравнение заданным количеством символов. Для этого вам нужно будет использовать опцию командной строки -w.
uniq -w [num-of-chars] [file-name]
Например, предположим, что файл содержит следующие строки:
Теперь, если требуется ограничить сравнение первыми 3 символами, тогда это можно сделать следующим образом:
uniq -w 3 file1
Вот эта команда в действии:
Поскольку первые 3 символа третьей и четвертой строк одинаковы, эти строки были признаны повторяющимися. Следовательно, только третья строка отображается в выводе.
9. Как сделать сравнение uniq нечувствительным к регистру
По умолчанию сравнение, которое выполняет uniq, является чувствительным к регистру. Однако вы можете сделать процесс нечувствительным к регистру, используя опцию командной строки -i.
Например, рассмотрим тот же случай, который мы обсуждали в предыдущем разделе, только что четвертая строка начинается с заглавной H, O и W.
Теперь, если вы попробуете запустить ту же команду, которую мы использовали в предыдущем разделе, вы увидите, что вывод отличается:
Это потому, что первые три символа третьей и четвертой строк различаются для uniq из-за их регистра. В таких ситуациях вы можете сделать сравнение нечувствительным к регистру, используя опцию -i.
10. Как сделать вывод uniq с окончанием NUL
По умолчанию вывод, который генерирует uniq, заканчивается новой строкой. Однако, если вы хотите, вы можете получить вывод с окончанием NUL вместо этого (полезно при работе с uniq в скриптах). Это можно сделать с помощью опции командной строки -z.
uniq -z [file-name]
Заключение
Мы охватили практически все опции командной строки, которые предлагает команда uniq, так что просто практикуйтесь с тем, что мы обсудили здесь, и вы должны получить четкое представление о том, как работает uniq и какие функции он предоставляет. Как всегда, в случае любых вопросов или сомнений сначала ознакомьтесь со страницей man команды.
Get new posts in your inbox
No spam. Unsubscribe anytime.