Kubernetes · 27 min read · Nov 03, 2025
Componentes principales de un clúster de Kubernetes

Kubernetes es una plataforma de código abierto para gestionar cargas de trabajo y servicios en contenedores que facilita la configuración declarativa y la automatización. El nombre Kubernetes se originó del griego, que significa timonel o piloto. Es portátil y extensible, y tiene un ecosistema en rápido crecimiento. Los servicios y herramientas de Kubernetes están ampliamente disponibles.
En este artículo, vamos a dar una vista general de 10,000 pies de los principales componentes de Kubernetes, desde de qué está compuesto cada contenedor, hasta cómo se despliega y programa un contenedor en un pod a través de cada uno de los trabajadores. Es crucial entender todos los detalles del clúster de Kubernetes para poder desplegar y diseñar una solución basada en Kubernetes como orquestador de aplicaciones en contenedores.
Aquí hay un breve resumen de los temas que vamos a cubrir en este artículo:
- Componentes del panel de control
- Componentes de los trabajadores de Kubernetes
- Pods como bloques de construcción básicos
- Servicios de Kubernetes, balanceadores de carga y controladores de Ingress
- Despliegues de Kubernetes y Conjuntos de Demonios
- Almacenamiento persistente en Kubernetes
El plano de control de Kubernetes
Los nodos maestros de Kubernetes son donde residen los servicios centrales del plano de control; no todos los servicios tienen que residir en el mismo nodo; sin embargo, por centralización y practicidad, a menudo se despliegan de esta manera. Esto, obviamente, plantea preguntas sobre la disponibilidad de los servicios; sin embargo, se pueden superar fácilmente teniendo varios nodos y proporcionando solicitudes de balanceo de carga para lograr un conjunto de nodos maestros altamente disponibles.
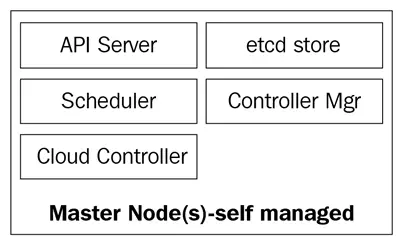
Los nodos maestros están compuestos por cuatro servicios básicos:
- El kube-apiserver
- El kube-scheduler
- El kube-controller-manager
- La base de datos etcd
Los nodos maestros pueden ejecutarse en servidores de metal desnudo, máquinas virtuales, o en una nube privada o pública, pero no se recomienda ejecutar cargas de trabajo de contenedores en ellos. Veremos más sobre esto más adelante.
El siguiente diagrama muestra los componentes de los nodos maestros de Kubernetes:
El kube-apiserver
El servidor API es lo que une todo. Es la API REST frontend del clúster que recibe manifiestos para crear, actualizar y eliminar objetos API como servicios, pods, Ingress y otros.
El kube-apiserver es el único servicio con el que deberíamos estar hablando; también es el único que escribe y habla con la base de datos etcd para registrar el estado del clúster. Con el comando kubectl, enviaremos comandos para interactuar con él. Esta será nuestra navaja suiza cuando se trata de Kubernetes.
El kube-controller-manager
El demonio kube-controller-manager, en resumen, es un conjunto de bucles de control infinitos que se envían por simplicidad en un solo binario. Observa el estado deseado definido del clúster y se asegura de que se logre y se satisfaga moviendo todas las piezas necesarias para lograrlo. El kube-controller-manager no es solo un controlador; contiene varios bucles diferentes que observan diferentes componentes en el clúster. Algunos de ellos son el controlador de servicios, el controlador de espacios de nombres, el controlador de cuentas de servicio y muchos otros. Puedes encontrar cada controlador y su definición en el repositorio de GitHub de Kubernetes: https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
El kube-scheduler
El kube-scheduler programa tus pods recién creados en nodos con suficiente espacio para satisfacer las necesidades de recursos de los pods. Básicamente, escucha al kube-apiserver y al kube-controller-manager para los pods recién creados que se ponen en una cola y luego se programan a un nodo disponible por el programador. La definición del kube-scheduler se puede encontrar aquí: https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Además de los recursos de computación, el kube-scheduler también lee las reglas de afinidad y anti-afinidad de los nodos para averiguar si un nodo puede o no ejecutar ese pod.
La base de datos etcd
La base de datos etcd es un almacén de clave-valor consistente y muy confiable que se utiliza para almacenar el estado del clúster de Kubernetes. Contiene el estado actual de los pods en los que se está ejecutando el nodo, cuántos nodos tiene actualmente el clúster, cuál es el estado de esos nodos, cuántas réplicas de despliegue están en ejecución, nombres de servicios y otros.
Como mencionamos antes, solo el kube-apiserver habla con la base de datos etcd. Si el kube-controller-manager necesita verificar el estado del clúster, pasará por el servidor API para obtener el estado de la base de datos etcd, en lugar de consultar directamente el almacén etcd. Lo mismo sucede con el kube-scheduler si el programador necesita hacer saber que un pod ha sido detenido o asignado a otro nodo; informará al servidor API, y el servidor API almacenará el estado actual en la base de datos etcd.
Con etcd, hemos cubierto todos los componentes principales para nuestros nodos maestros de Kubernetes para que estemos listos para gestionar nuestro clúster. Pero un clúster no solo está compuesto por maestros; todavía requerimos los nodos que realizarán el trabajo pesado ejecutando nuestras aplicaciones.
Nodos trabajadores de Kubernetes
Los nodos trabajadores que realizan esta tarea en Kubernetes se llaman simplemente nodos. Anteriormente, alrededor de 2014, se les llamaba minions, pero este término fue reemplazado más tarde por solo nodos, ya que el nombre era confuso con las terminologías de Salt y hacía que la gente pensara que Salt estaba desempeñando un papel importante en Kubernetes.
Estos nodos son el único lugar donde estarás ejecutando cargas de trabajo, ya que no se recomienda tener contenedores o cargas en los nodos maestros, ya que necesitan estar disponibles para gestionar todo el clúster. Los nodos son muy simples en términos de componentes; solo requieren tres servicios para cumplir su tarea:
- Kubelet
- Kube-proxy
- Tiempo de ejecución de contenedores
Exploraremos estos tres componentes con un poco más de profundidad.
El kubelet
El kubelet es un componente de Kubernetes de bajo nivel y uno de los más importantes después del kube-apiserver; ambos componentes son esenciales para la provisión de pods/contenedores en el clúster. El kubelet es un servicio que se ejecuta en los nodos de Kubernetes y escucha al servidor API para la creación de pods. El kubelet solo se encarga de iniciar/detener y asegurarse de que los contenedores en los pods estén saludables; el kubelet no podrá gestionar ningún contenedor que no haya creado.
El kubelet logra los objetivos hablando con el tiempo de ejecución de contenedores a través de la interfaz de tiempo de ejecución de contenedores (CRI). La CRI proporciona capacidad de conexión al kubelet a través de un cliente gRPC, que puede comunicarse con diferentes tiempos de ejecución de contenedores. Como mencionamos anteriormente, Kubernetes admite múltiples tiempos de ejecución de contenedores para desplegar contenedores, y así es como logra un soporte tan diverso para diferentes motores.
Puedes consultar el código fuente del kubelet en https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
El kube-proxy
El kube-proxy es un servicio que reside en cada nodo del clúster y es el que hace posible la comunicación entre pods, contenedores y nodos. Este servicio observa al kube-apiserver en busca de cambios en los servicios definidos (un servicio es una especie de balanceador de carga lógico en Kubernetes; profundizaremos en los servicios más adelante en este artículo) y mantiene la red actualizada a través de reglas de iptables que reenvían el tráfico a los puntos finales correctos. Kube-proxy también establece reglas en iptables que realizan balanceo de carga aleatorio entre los pods detrás de un servicio.
Aquí hay un ejemplo de una regla de iptables que fue creada por el kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment –comment “default/example: no tiene puntos finales” -m tcp –dport 80 -j REJECT –reject-with icmp-port-unreachable
Ten en cuenta que este es un servicio sin puntos finales (sin pods detrás de él).
Tiempo de ejecución de contenedores
Para poder iniciar contenedores, requerimos un tiempo de ejecución de contenedores. Este es el motor base que creará los contenedores en el núcleo de los nodos para que nuestros pods se ejecuten. El kubelet estará hablando con este tiempo de ejecución y girará o detendrá nuestros contenedores bajo demanda.
Actualmente, Kubernetes admite cualquier tiempo de ejecución de contenedores compatible con OCI, como Docker, rkt, runc, runsc, etc.
Puedes consultar esto https://github.com/opencontainers/runtime-spec para aprender más sobre todas las especificaciones de la página de Git-Hub de OCI.
Ahora que hemos explorado todos los componentes centrales que forman un clúster, echemos un vistazo a lo que se puede hacer con ellos y cómo Kubernetes nos ayudará a orquestar y gestionar nuestras aplicaciones en contenedores.
Objetos de Kubernetes
Los objetos de Kubernetes son exactamente eso: son objetos lógicos persistentes o abstracciones que representarán el estado de tu clúster. Eres tú quien se encarga de decirle a Kubernetes cuál es tu estado deseado de ese objeto para que pueda trabajar para mantenerlo y asegurarse de que el objeto exista.
Para crear un objeto, hay dos cosas que necesita tener: un estado y su especificación. El estado es proporcionado por Kubernetes, y es el estado actual del objeto. Kubernetes gestionará y actualizará ese estado según sea necesario para estar en conformidad con tu estado deseado. El campo de especificación, por otro lado, es lo que proporcionas a Kubernetes, y es lo que le dices para describir el objeto que deseas. Por ejemplo, la imagen que deseas que el contenedor esté ejecutando, el número de contenedores de esa imagen que deseas ejecutar, etc.
Cada objeto tiene campos de especificación específicos para el tipo de tarea que realizan, y proporcionarás estas especificaciones en un archivo YAML que se envía al kube-apiserver con kubectl, que lo transforma en JSON y lo envía como una solicitud API. Profundizaremos en cada objeto y sus campos de especificación más adelante en este artículo.
Aquí hay un ejemplo de un YAML que se envió a kubectl:
cat << EOF | kubectl create -f -kind: ServiceapiVersion: v1metadata: Name: frontend-servicespec: selector: web: frontend ports: - protocol: TCP port: 80 targetPort: 9256EOF
Los campos básicos de la definición del objeto son los primeros, y estos no variarán de objeto a objeto y son muy autoexplicativos. Echemos un vistazo rápido a ellos:
- kind: El campo kind le dice a Kubernetes qué tipo de objeto estás definiendo: un pod, un servicio, un despliegue, etc.
- apiVersion: Debido a que Kubernetes admite múltiples versiones de API, necesitamos especificar una ruta de API REST a la que queremos enviar nuestra definición.
- metadata: Este es un campo anidado, lo que significa que tienes varios subcampos más en metadata, donde escribirás definiciones básicas como el nombre de tu objeto, asignándolo a un espacio de nombres específico, y también etiquetarlo para relacionar tu objeto con otros objetos de Kubernetes.
Así que ahora hemos revisado los campos más utilizados y sus contenidos; puedes aprender más sobre las convenciones de la API de Kubernetes en https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Algunos de los campos del objeto pueden modificarse más tarde después de que el objeto haya sido creado, pero eso dependerá del objeto y del campo que desees modificar.
La siguiente es una lista corta de los diversos objetos de Kubernetes que puedes crear:
- Pod
- Volumen
- Servicio
- Despliegue
- Ingress
- Secreto
- ConfigMap
Y hay muchos más.
Echemos un vistazo más de cerca a cada uno de estos elementos.
Pods – la base de Kubernetes
Los pods son los objetos más básicos en Kubernetes y también los más importantes. Todo gira en torno a ellos; podemos decir que Kubernetes es para los pods. Todos los demás objetos están aquí para servirles, y todas las tareas que realizan son para hacer que los pods logren tu estado deseado.
Entonces, ¿qué es un pod y por qué son tan importantes los pods?
Un pod es un objeto lógico que ejecuta uno o más contenedores juntos en el mismo espacio de nombres de red, la misma comunicación entre procesos (IPC), y, a veces, dependiendo de la versión de Kubernetes, el mismo espacio de nombres de ID de proceso (PID). Esto se debe a que son los que van a ejecutar nuestros contenedores y, por lo tanto, serán el centro de atención. El objetivo de Kubernetes es ser un orquestador de contenedores, y con los pods, hacemos posible la orquestación.
Como mencionamos antes, los contenedores en el mismo pod viven en una “burbuja” donde pueden hablar entre sí a través de localhost, ya que son locales entre sí. Un contenedor en un pod tiene la misma dirección IP que el otro contenedor porque comparten un espacio de nombres de red, pero en la mayoría de los casos, estarás ejecutando en una base uno a uno, es decir, un solo contenedor por pod. Múltiples contenedores por pod solo se utilizan en escenarios muy específicos, como cuando una aplicación requiere un ayudante, como un empujador de datos o un proxy que necesita comunicarse de manera rápida y resiliente con la aplicación principal.
La forma en que defines un pod es la misma que harías para cualquier otro objeto de Kubernetes: a través de un YAML que contiene todas las especificaciones y definiciones del pod:
kind: PodapiVersion: v1metadata:name: hello-podlabels: hello: podspec: containers: - name: hello-container image: alpine args: - echo - “Hello World”
Repasemos las definiciones básicas del pod necesarias bajo el campo spec para crear nuestro pod:
- Containers: Un contenedor es un array; por lo tanto, tenemos un conjunto de varios subcampos bajo él. Básicamente, es lo que define los contenedores que se van a ejecutar en el pod. Podemos especificar un nombre para el contenedor, la imagen de la que se va a derivar, y los argumentos o comandos que necesitamos que ejecute. La diferencia entre argumentos y comandos es la misma que la diferencia entre CMD y ENTRYPOINT. Toma nota de que todos los campos que acabamos de revisar son para el array de contenedores. No son parte directamente de la especificación del pod.
- restartPolicy: Este campo es exactamente eso: le dice a Kubernetes qué hacer con un contenedor, y se aplica a todos los contenedores en el pod en caso de un código de salida cero o no cero. Puedes elegir entre cualquiera de las opciones, Nunca, EnFallo o Siempre. Siempre será el valor predeterminado en caso de que no se defina una política de reinicio.
Estos son los specs más básicos que vas a declarar en un pod; otros specs requerirán que tengas un poco más de conocimiento sobre cómo usarlos y cómo interactúan con varios otros objetos de Kubernetes. Los revisaremos más adelante en este artículo; algunos de ellos son los siguientes:
- Volumen
- Env
- Puertos
- dnsPolicy
- initContainers
- nodeSelector
- Límites y solicitudes de recursos
Para ver los pods que están actualmente en ejecución en tu clúster, puedes ejecutar kubectl get pods:
dsala@MININT-IB3HUA8:~$ kubectl get podsNAME READY STATUS RESTARTS AGEbusybox 1/1 Running 120 5d
Alternativamente, puedes ejecutar kubectl describe pods sin especificar ningún pod. Esto imprimirá una descripción de cada pod en ejecución en el clúster. En este caso, será solo el pod busybox, ya que es el único que está actualmente en ejecución:
dsala@MININT-IB3HUA8:~$ kubectl describe podsName: busyboxNamespace: defaultPriority: 0PriorityClassName:
Los pods son mortales. Una vez que mueren o son eliminados, no pueden ser recuperados. Su IP y los contenedores que estaban en ejecución en él desaparecerán; son totalmente efímeros. Los datos en los pods que están montados como un volumen pueden o no sobrevivir, dependiendo de cómo lo configures. Si nuestros pods mueren y los perdemos, ¿cómo aseguramos que todos nuestros microservicios estén en ejecución? Bueno, los despliegues son la respuesta.
Despliegues
Los pods por sí mismos no son muy útiles, ya que no es muy eficiente tener más de una sola instancia de nuestra aplicación ejecutándose en un solo pod. Proveer cientos de copias de nuestra aplicación en diferentes pods sin tener un método para buscarlas todas se volverá incontrolable muy rápidamente.
Aquí es donde entran en juego los despliegues. Con los despliegues, podemos gestionar nuestros pods con un controlador. Esto nos permite no solo decidir cuántos queremos ejecutar, sino que también podemos gestionar actualizaciones cambiando la versión de la imagen o la imagen misma que están ejecutando nuestros contenedores. Los despliegues son con los que estarás trabajando la mayor parte del tiempo. Con los despliegues, así como con los pods y cualquier otro objeto que mencionamos antes, tienen su propia definición dentro de un archivo YAML:
apiVersion: apps/v1kind: Deploymentmetadata: name: nginx-deployment labels: deployment: nginxspec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80
Comencemos a explorar su definición.
Al principio del YAML, tenemos campos más generales, como apiVersion, kind y metadata. Pero bajo spec es donde encontraremos las opciones específicas para este objeto API.
Bajo spec, podemos agregar los siguientes campos:
Selector: Con el campo Selector, el despliegue sabrá qué pods apuntar cuando se apliquen cambios. Hay dos campos que estarás utilizando bajo el selector: matchLabels y matchExpressions. Con matchLabels, el selector utilizará las etiquetas de los pods (pares clave/valor). Es importante notar que todas las etiquetas que especifiques aquí se combinarán con un AND. Esto significa que el pod requerirá que tenga todas las etiquetas que especifiques bajo matchLabels.
Replicas: Esto indicará el número de pods que el despliegue necesita mantener en ejecución a través del controlador de replicación; por ejemplo, si especificas tres réplicas, y uno de los pods muere, el controlador de replicación observará el spec de réplicas como el estado deseado e informará al programador para que programe un nuevo pod, ya que el estado actual ahora es 2 desde que el pod murió.
RevisionHistoryLimit: Cada vez que realizas un cambio en el despliegue, este cambio se guarda como una revisión del despliegue, a la que luego puedes revertir a ese estado anterior o mantener un registro de lo que se cambió. Puedes consultar tu historial con kubectl rollout history deployment/
Strategy: Esto te permitirá decidir cómo deseas manejar cualquier actualización o escalado horizontal de pods. Para sobrescribir el valor predeterminado, que es rollingUpdate, necesitas escribir la clave type, donde puedes elegir entre dos valores: recreate o rollingUpdate.
Mientras que recreate es una forma rápida de actualizar tu despliegue, eliminará todos los pods y los reemplazará por nuevos, pero implicará que deberás tener en cuenta que habrá un tiempo de inactividad del sistema para este tipo de estrategia. El rollingUpdate, por otro lado, es más suave y lento y es ideal para aplicaciones con estado que pueden reequilibrar sus datos. El rollingUpdate abre la puerta a dos campos más, que son maxSurge y maxUnavailable.
El primero será cuántos pods por encima de la cantidad total deseas al realizar una actualización; por ejemplo, un despliegue con 100 pods y un 20% maxSurge crecerá hasta un máximo de 120 pods mientras se actualiza. La siguiente opción te permitirá seleccionar cuántos pods en porcentaje estás dispuesto a eliminar para reemplazarlos por nuevos en un escenario de 100 pods. En casos donde hay un 20% maxUnavailable, solo 20 pods serán eliminados y reemplazados por nuevos antes de continuar reemplazando el resto del despliegue.
Template: Este es solo un campo de especificación de pod anidado donde incluirás todas las especificaciones y metadatos de los pods que el despliegue va a gestionar.
Hemos visto que, con los despliegues, gestionamos nuestros pods, y nos ayudan a mantenerlos en un estado que deseamos. Todos estos pods todavía están en algo llamado red del clúster, que es una red cerrada en la que solo los componentes del clúster de Kubernetes pueden hablar entre sí, incluso teniendo su propio conjunto de rangos de IP. ¿Cómo hablamos con nuestros pods desde el exterior? ¿Cómo llegamos a nuestra aplicación? Aquí es donde entran en juego los servicios.
Servicios:
El nombre servicio no describe completamente lo que los servicios realmente hacen en Kubernetes. Los servicios de Kubernetes son los que dirigen el tráfico a nuestros pods. Podemos decir que los servicios son los que unen los pods.
Imaginemos que tenemos una aplicación típica de tipo frontend/backend donde nuestros pods frontend hablan con nuestros pods backend a través de las direcciones IP de los pods. Si un pod en el backend muere, perdemos la comunicación con nuestro backend. Esto no solo se debe a que el nuevo pod no tendrá la misma dirección IP que el pod que murió, sino que ahora también tenemos que reconfigurar nuestra aplicación para usar la nueva dirección IP. Este problema y problemas similares se resuelven con servicios.
Un servicio es un objeto lógico que le dice al kube-proxy que cree reglas de iptables basadas en qué pods están detrás del servicio. Los servicios configuran sus puntos finales, que es como se llaman los pods detrás de un servicio, de la misma manera que los despliegues saben qué pods controlar, el campo selector y las etiquetas de los pods.
Este diagrama te muestra cómo los servicios utilizan etiquetas para gestionar el tráfico:
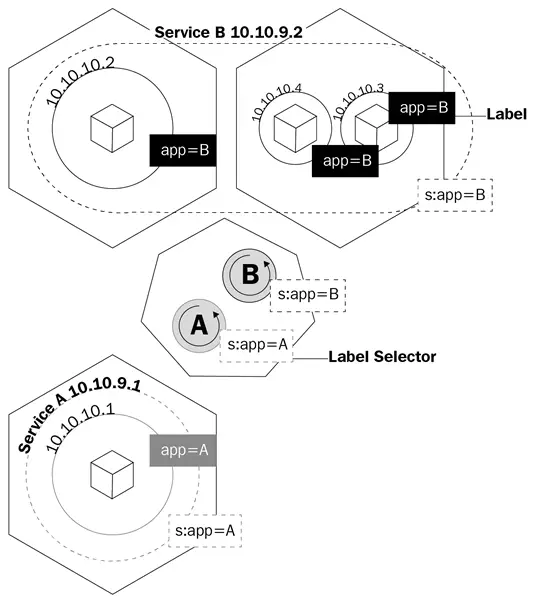
Los servicios no solo harán que kube-proxy cree reglas para dirigir el tráfico; también activará algo llamado kube-dns.
Kube-dns es un conjunto de pods con contenedores SkyDNS que se ejecutan en el clúster que proporciona un servidor DNS y reenvío, que creará registros para servicios y, a veces, pods para facilitar su uso. Cada vez que creas un servicio, se creará un registro DNS que apunta a la dirección IP interna del clúster del servicio con la forma service-name.namespace.svc.cluster.local. Puedes aprender más sobre las especificaciones de DNS de Kubernetes aquí: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Volviendo a nuestro ejemplo, ahora solo tendremos que configurar nuestra aplicación para hablar con el nombre de dominio completamente calificado (FQDN) del servicio para hablar con nuestros pods backend. De esta manera, no importará qué dirección IP tengan los pods y servicios. Si un pod detrás del servicio muere, el servicio se encargará de todo utilizando el registro A, ya que podremos decirle a nuestro frontend que dirija todo el tráfico a my-svc. La lógica del servicio se encargará de todo lo demás.
Hay varios tipos de servicio que puedes crear cada vez que declares el objeto que se va a crear en Kubernetes. Vamos a revisarlos para ver cuál será el más adecuado para el tipo de trabajo que necesitamos:
ClusterIP: Este es el servicio predeterminado. Cada vez que creas un servicio ClusterIP, creará un servicio con una dirección IP interna del clúster que solo será enrutada dentro del clúster de Kubernetes. Este tipo es ideal para pods que solo necesitan hablar entre sí y no salir del clúster.
NodePort: Cuando creas este tipo de servicio, por defecto se asignará un puerto aleatorio del 30000 al 32767 para reenviar tráfico a los pods de puntos finales del servicio. Puedes anular este comportamiento especificando un puerto de nodo en el array de puertos. Una vez que esto esté definido, podrás acceder a tus pods a través de
LoadBalancer: La mayoría de las veces, estarás ejecutando Kubernetes en un proveedor de nube. El tipo LoadBalancer es ideal para estas situaciones, ya que podrás asignar direcciones IP públicas a tu servicio a través de la API de tu proveedor de nube. Este es el servicio ideal para cuando deseas comunicarte con tus pods desde fuera de tu clúster. Con LoadBalancer, podrás no solo asignar una dirección IP pública, sino también, utilizando Azure, asignar una dirección IP privada de tu red privada virtual. Así, podrás hablar con tus pods desde internet o internamente en tu subred privada.
Revisemos la definición YAML de un servicio:
apiVersion: v1kind: Servicemetadata: name: my-servicespec: selector: app: front-end type: NodePort ports: - name: http port: 80 targetPort: 8080 nodePort: 30024 protocol: TCP
El YAML de un servicio es muy simple, y las especificaciones variarán, dependiendo del tipo de servicio que estés creando. Pero lo más importante que debes tener en cuenta son las definiciones de puertos. Echemos un vistazo a estos:
- port: Este es el puerto del servicio que se expone
- targetPort: Este es el puerto en los pods al que el servicio está enviando tráfico
- nodePort: Este es el puerto que se expondrá
Aunque ahora entendemos cómo podemos comunicarnos con los pods en nuestro clúster, todavía necesitamos entender cómo vamos a gestionar el problema de perder nuestros datos cada vez que un pod es terminado. Aquí es donde entran en juego los Volúmenes Persistentes (PV).
Kubernetes y almacenamiento persistente
El almacenamiento persistente en el mundo de los contenedores es un problema serio. El único almacenamiento que es persistente a través de las ejecuciones de contenedores son las capas de la imagen, y son de solo lectura. La capa donde se ejecuta el contenedor es de lectura/escritura, pero todos los datos en esta capa se eliminan una vez que el contenedor se detiene. Con los pods, esto es lo mismo. Cuando un contenedor muere, los datos escritos en él desaparecen.
Kubernetes tiene un conjunto de objetos para manejar el almacenamiento a través de los pods. El primero que discutiremos son los volúmenes.
Volúmenes
Los volúmenes resuelven uno de los mayores problemas cuando se trata de almacenamiento persistente. Primero que nada, los volúmenes no son realmente objetos, sino una definición de la especificación de un pod. Cuando creas un pod, puedes definir un volumen bajo el campo de especificación del pod. Los contenedores en este pod podrán montar el volumen en su espacio de nombres de montaje, y el volumen estará disponible a través de reinicios o fallos de contenedores. Sin embargo, los volúmenes están vinculados a los pods, y si el pod es eliminado, el volumen también desaparecerá. La persistencia de los datos en el volumen es otra historia; la persistencia de datos dependerá del backend de ese volumen.
Kubernetes admite varios tipos de volúmenes o fuentes de volúmenes y cómo se llaman en las especificaciones de la API, que van desde mapas de sistemas de archivos del nodo local, discos virtuales de proveedores de nube, y volúmenes respaldados por almacenamiento definido por software. Los montajes de sistemas de archivos locales son los más comunes que verás cuando se trata de volúmenes regulares. Es importante notar que la desventaja de usar el sistema de archivos local del nodo es que los datos no estarán disponibles a través de todos los nodos del clúster, y solo en ese nodo donde se programó el pod.
Examinemos cómo se define un pod con un volumen en YAML:
apiVersion: v1kind: Podmetadata: name: test-pdspec: containers: - image: k8s.gcr.io/test-webserver name: test-container volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: path: /data type: Directory
Nota cómo hay un campo llamado volumes bajo spec y luego hay otro llamado volumeMounts.
El primer campo (volumes) es donde defines el volumen que deseas crear para ese pod. Este campo siempre requerirá un nombre y luego una fuente de volumen. Dependiendo de la fuente, los requisitos serán diferentes. En este ejemplo, la fuente sería hostPath, que es el sistema de archivos local de un nodo. hostPath admite varios tipos de mapeos, que van desde directorios, archivos, dispositivos de bloque, e incluso sockets Unix.
Bajo el segundo campo, volumeMounts, tenemos mountPath, que es donde defines la ruta dentro del contenedor donde deseas montar tu volumen. El parámetro name es cómo especificas al pod qué volumen usar. Esto es importante porque puedes tener varios tipos de volúmenes definidos bajo volumes, y el nombre será la única forma para que el pod sepa cuál usar.
Puedes aprender más sobre los diferentes tipos de volúmenes aquí https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes y en el documento de referencia de la API de Kubernetes ( https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.11/#volume-v1-core).
Hacer que los volúmenes mueran con los pods no es ideal. Requerimos almacenamiento que persista, y así es como surgió la necesidad de los PVs.
Volúmenes Persistentes, Reclamaciones de Volumen Persistente y Clases de Almacenamiento
La principal diferencia entre los volúmenes y los PVs es que, a diferencia de los volúmenes, los PVs son en realidad objetos de la API de Kubernetes, por lo que puedes gestionarlos individualmente como entidades separadas, y por lo tanto persisten incluso después de que un pod es eliminado.
Puede que te estés preguntando por qué esta subsección tiene PV, reclamaciones de volumen persistente (PVCs), y clases de almacenamiento todas mezcladas. Esto se debe a que todos dependen unos de otros, y es crucial entender cómo interactúan entre sí para proporcionar almacenamiento para nuestros pods.
Comencemos con los PVs y PVCs. Al igual que los volúmenes, los PVs tienen una fuente de almacenamiento, por lo que el mismo mecanismo que tienen los volúmenes se aplica aquí. Tendrás un clúster de almacenamiento definido por software que proporciona un número de unidad lógica (LUN), un proveedor de nube que da discos virtuales, o incluso un sistema de archivos local al nodo de Kubernetes, pero aquí, en lugar de ser llamados fuentes de volumen, se llaman tipos de volumen persistente.
Los PVs son prácticamente como LUNs en un arreglo de almacenamiento: los creas, pero sin un mapeo; son solo un montón de almacenamiento asignado esperando ser utilizado. Los PVCs son como mapeos de LUN: están respaldados o vinculados a un PV y también son lo que realmente defines, relacionas y haces disponible para el pod que luego puede usarlo para sus contenedores.
La forma en que usas PVCs en los pods es exactamente la misma que con los volúmenes normales. Tienes dos campos: uno para especificar qué PVC deseas usar, y el otro para decirle al pod en qué contenedor usar ese PVC.
El YAML para una definición de objeto API de PVC debería tener el siguiente código:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: gluster-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi
El YAML para el pod debería tener el siguiente código:
kind: PodapiVersion: v1metadata: name: mypodspec: containers: - name: myfrontend image: nginx volumeMounts: - mountPath: “/mnt/gluster” name: volume volumes: - name: volume persistentVolumeClaim: claimName: gluster-pvc
Cuando un administrador de Kubernetes crea un PVC, hay dos formas en que se satisface esta solicitud:
- Estática: Se han creado varios PVs, y luego cuando un usuario crea un PVC, cualquier PV disponible que pueda satisfacer los requisitos será vinculado a ese PVC.
- Dinámica: Algunos tipos de PV pueden crear PVs basados en definiciones de PVC. Cuando se crea un PVC, el tipo de PV creará dinámicamente un objeto PV y asignará el almacenamiento en el backend; esto es aprovisionamiento dinámico. El inconveniente del aprovisionamiento dinámico es que requieres un tercer tipo de objeto de almacenamiento de Kubernetes, llamado clase de almacenamiento.
Las clases de almacenamiento son como una forma de clasificar tu almacenamiento. Puedes crear una clase que aprovisione volúmenes de almacenamiento lentos, o otra con discos SSD hiper-rápidos. Sin embargo, las clases de almacenamiento son un poco más complejas que solo clasificar. Como mencionamos en las dos formas de crear PVC, las clases de almacenamiento son lo que hace posible el aprovisionamiento dinámico. Al trabajar en un entorno en la nube, no deseas estar creando manualmente cada disco de backend para cada PV. Las clases de almacenamiento configurarán algo llamado aprovisionador, que invoca el complemento de volumen que es necesario para hablar con la API de tu proveedor de nube. Cada aprovisionador tiene su propia configuración para poder comunicarse con el proveedor de nube o de almacenamiento especificado.
Puedes aprovisionar clases de almacenamiento de la siguiente manera; este es un ejemplo de una clase de almacenamiento utilizando Azure-disk como aprovisionador de disco:
kind: StorageClassapiVersion: storage.k8s.io/v1metadata: name: my-storage-classprovisioner: kubernetes.io/azure-diskparameters: storageaccounttype: Standard_LRS kind: Shared
Cada aprovisionador de clase de almacenamiento y tipo de PV tendrá diferentes requisitos y parámetros, así como los volúmenes, y ya hemos tenido una visión general de cómo funcionan y para qué podemos usarlos. Aprender sobre clases de almacenamiento específicas y tipos de PV dependerá de tu entorno; puedes aprender más sobre cada uno de ellos haciendo clic en los siguientes enlaces:
- https://kubernetes.io/docs/concepts/storage/storage-classes/#provisioner
- https://kubernetes.io/docs/concepts/storage/persistent-volumes/#types-of-persistent-volumes
En este artículo, aprendimos qué es Kubernetes, sus componentes y cuáles son las ventajas de usar la orquestación. Con esto, identificar cada uno de los objetos de la API de Kubernetes, su propósito y sus casos de uso debería ser fácil. Ahora deberías ser capaz de entender cómo los nodos maestros controlan el clúster y la programación de los contenedores en los nodos trabajadores.
Si encontraste útil este artículo, ‘ Hands-On Linux for Architects ’ debería ser útil para ti. Con este libro, cubrirás todo, desde componentes y funcionalidades de Linux hasta soporte de hardware y software, lo que te ayudará a implementar y ajustar soluciones efectivas basadas en Linux. Se te llevará a través de una visión general de la metodología de diseño de Linux y los conceptos centrales del diseño de una solución. Si eres un administrador de sistemas Linux, ingeniero de soporte de Linux, ingeniero de DevOps, consultor de Linux o cualquier persona que busque aprender o expandir su conocimiento en arquitectura, este libro es para ti.
Recibe nuevas publicaciones en tu bandeja de entrada.
No spam. Cancela la suscripción en cualquier momento.