Hadoop Ubuntu · 12 min read · Dec 21, 2025
Cómo instalar Apache Hadoop en Ubuntu 22.04

Apache Hadoop es un marco de trabajo de código abierto para procesar y almacenar grandes datos. En las industrias de hoy, Hadoop se ha convertido en el marco estándar para grandes datos. Hadoop está diseñado para ejecutarse en sistemas distribuidos con cientos o incluso miles de computadoras agrupadas o servidores dedicados. Con esto en mente, Hadoop puede manejar grandes conjuntos de datos con alto volumen y complejidad tanto para datos estructurados como no estructurados.
Cada implementación de Hadoop contiene los siguientes componentes:
- Hadoop Common: Las utilidades comunes que soportan los otros módulos de Hadoop.
- Hadoop Distributed File System (HDFS): Un sistema de archivos distribuido que proporciona acceso de alto rendimiento a los datos de la aplicación.
- Hadoop YARN: Un marco para la programación de trabajos y la gestión de recursos del clúster.
- Hadoop MapReduce: Un sistema basado en YARN para el procesamiento paralelo de grandes conjuntos de datos.
En este tutorial, instalaremos la última versión de Apache Hadoop en un servidor Ubuntu 22.04. Hadoop se instalará en un servidor de nodo único y crearemos un modo de despliegue de Hadoop Pseudo-Distribuido.
Requisitos previos
Para completar esta guía, necesitarás los siguientes requisitos:
- Un servidor Ubuntu 22.04 - Este ejemplo utiliza un servidor Ubuntu con nombre de host ‘hadoop’ y dirección IP ‘192.168.5.100’.
- Un usuario no root con privilegios de administrador sudo/root.
Instalando Java OpenJDK
Hadoop es un gran proyecto bajo la Apache Software Foundation, está principalmente escrito en Java. En el momento de escribir esto, la última versión de Hadoop es v3.3.4, que es completamente compatible con Java v11.
El Java OpenJDK 11 está disponible por defecto en el repositorio de Ubuntu, y lo instalarás a través de APT.
Para comenzar, ejecuta el siguiente comando apt para actualizar y refrescar las listas/repositories de paquetes en tu sistema Ubuntu.
sudo apt updateAhora instala el Java OpenJDK 11 a través del comando apt a continuación. En el repositorio de Ubuntu 22.04, el paquete ‘default-jdk’ se refiere al Java OpenJDK v11.
sudo apt install default-jdkCuando se te pida, ingresa y para confirmar y presiona ENTER para continuar. Y la instalación de Java OpenJDK comenzará.
Después de que Java esté instalado, ejecuta el siguiente comando para verificar la versión de Java. Deberías obtener el Java OpenJDK 11 instalado en tu sistema Ubuntu.
java -versionAhora que el Java OpenJDK está instalado, configurarás un nuevo usuario con autenticación SSH sin contraseña que se utilizará para ejecutar procesos y servicios de Hadoop.
Configurando usuario y autenticación SSH sin contraseña
Apache Hadoop requiere que el servicio SSH esté en ejecución en el sistema. Esto será utilizado por los scripts de Hadoop para gestionar el demonio remoto de Hadoop en el servidor remoto. En este paso, crearás un nuevo usuario que se utilizará para ejecutar procesos y servicios de Hadoop y luego configurarás la autenticación SSH sin contraseña.
En caso de que no tengas SSH instalado en tu sistema, ejecuta el comando apt a continuación para instalar SSH. El paquete ‘pdsh‘ es un cliente de shell remoto multihilo que te permite ejecutar comandos en múltiples hosts en modo paralelo.
sudo apt install openssh-server openssh-client pdshAhora ejecuta el siguiente comando para crear un nuevo usuario ‘hadoop’ y configurar la contraseña para el usuario ‘hadoop’.
sudo useradd -m -s /bin/bash hadoop
sudo passwd hadoopIngresa la nueva contraseña para el usuario ‘hadoop‘ y repite la contraseña.
A continuación, agrega el usuario ‘hadoop’ al grupo ‘sudo‘ a través del comando usermod a continuación. Esto permite que el usuario ‘hadoop’ ejecute el comando ‘sudo’.
sudo usermod -aG sudo hadoopAhora que el usuario ‘hadoop’ está creado, inicia sesión en el usuario ‘hadoop‘ a través del siguiente comando.
su - hadoopDespués de iniciar sesión, tu prompt se verá así: “ hadoop@hostname.. “.
A continuación, ejecuta el siguiente comando para generar la clave pública y privada SSH. Cuando se te pida configurar la contraseña para la clave, presiona ENTER para omitir.
ssh-keygen -t rsaLa clave SSH ahora se ha generado en el directorio ~/.ssh. El id_rsa.pub es la clave pública SSH y el archivo ‘id_rsa’ es la clave privada.
Puedes verificar la clave SSH generada a través del siguiente comando.
ls ~/.ssh/A continuación, ejecuta el siguiente comando para copiar la clave pública SSH ‘id_rsa.pub‘ al archivo ‘authorized_keys‘ y cambiar el permiso predeterminado a 600.
En ssh, el archivo ‘authorized_keys‘ es donde almacenas la clave pública ssh, que puede ser múltiples claves públicas. Cualquiera que tenga la clave pública almacenada en el archivo ‘authorized_keys‘ y tenga la clave privada correcta podrá conectarse al servidor como usuario ‘hadoop‘ sin una contraseña.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
Con la configuración de SSH sin contraseña terminada, puedes verificar conectándote a la máquina local a través del comando ssh a continuación.
ssh localhostIngresa yes para confirmar y agregar la huella digital SSH y estarás conectado al servidor sin autenticación por contraseña.
Ahora que el usuario ‘hadoop‘ está creado y la autenticación SSH sin contraseña configurada, procederás a la instalación de Hadoop descargando el paquete binario de Hadoop.
Descargando Hadoop
Después de crear un nuevo usuario y configurar la autenticación SSH sin contraseña, ahora puedes descargar el paquete binario de Apache Hadoop y configurar el directorio de instalación para él. En este ejemplo, descargarás Hadoop v3.3.4 y el directorio de instalación objetivo será el directorio ‘/usr/local/hadoop‘.
Ejecuta el siguiente comando wget para descargar el paquete binario de Apache Hadoop al directorio de trabajo actual. Deberías obtener el archivo ‘hadoop-3.3.4.tar.gz‘ en tu directorio de trabajo actual.
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gzA continuación, extrae el paquete de Apache Hadoop ‘hadoop-3.3.4.tar.gz’ a través del comando tar a continuación. Luego, mueve el directorio extraído a ‘/usr/local/hadoop‘.
tar -xvzf hadoop-3.3.4.tar.gz
sudo mv hadoop-3.3.4 /usr/local/hadoopPor último, cambia la propiedad del directorio de instalación de Hadoop ‘/usr/local/hadoop’ al usuario ‘hadoop‘ y grupo ‘hadoop‘.
sudo chown -R hadoop:hadoop /usr/local/hadoop
En este paso, descargaste el paquete binario de Apache Hadoop y configuraste el directorio de instalación de Hadoop. Con eso en mente, ahora puedes comenzar a configurar la instalación de Hadoop.
Configurando variables de entorno de Hadoop
Abre el archivo de configuración ‘~/.bashrc‘ a través del comando del editor nano a continuación.
nano ~/.bashrcAgrega las siguientes líneas al archivo. Asegúrate de colocar las siguientes líneas al final del archivo.
# Variables de entorno de Hadoop
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Guarda el archivo y sal del editor cuando hayas terminado.
A continuación, ejecuta el siguiente comando para aplicar los nuevos cambios dentro del archivo ‘~/.bashrc‘.
source ~/.bashrcDespués de que se ejecute el comando, las nuevas variables de entorno se aplicarán. Puedes verificar revisando cada variable de entorno a través del siguiente comando. Y deberías obtener la salida de cada variable de entorno.
echo $JAVA_HOME
echo $HADOOP_HOME
echo $HADOOP_OPTSA continuación, también configurarás la variable de entorno JAVA_HOME en el script ‘hadoop-env.sh‘.
Abre el archivo ‘hadoop-env.sh’ usando el siguiente comando del editor nano. El archivo ‘hadoop-env.sh’ está disponible en el directorio ‘$HADOOP_HOME‘, que se refiere al directorio de instalación de Hadoop ‘/usr/local/hadoop‘.
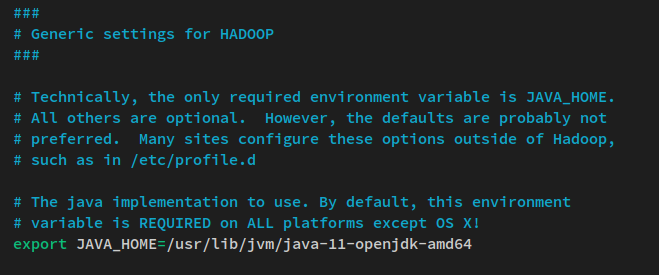
nano $HADOOP_HOME/etc/hadoop/hadoop-env.shDescomenta la línea de entorno JAVA_HOME y cambia el valor al directorio de instalación de Java OpenJDK ‘/usr/lib/jvm/java-11-openjdk-amd64‘.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64Guarda el archivo y sal del editor cuando hayas terminado.
Con la configuración de variables de entorno, ejecuta el siguiente comando para verificar la versión de Hadoop en tu sistema. Deberías ver Apache Hadoop 3.3.4 instalado en tu sistema.
hadoop version
En este punto, estás listo para configurar y desplegar el clúster de Hadoop, que puede ser desplegado en múltiples modos.
Configurando el clúster de Apache Hadoop: Modo Pseudo-Distribuido
En Hadoop, puedes crear un clúster en tres modos diferentes:
- Modo Local (Standalone) - instalación predeterminada de Hadoop, que se ejecuta como un solo proceso Java y en modo no distribuido. Con esto, puedes depurar fácilmente el proceso de Hadoop.
- Modo Pseudo-Distribuido - Esto te permite ejecutar un clúster de Hadoop en modo distribuido incluso con solo un nodo/servidor único. En este modo, los procesos de Hadoop se ejecutarán en procesos Java separados.
- Modo Totalmente Distribuido - gran despliegue de Hadoop con múltiples o incluso miles de nodos/servidores. Si deseas ejecutar Hadoop en producción, deberías usar Hadoop en modo totalmente distribuido.
En este ejemplo, configurarás un clúster de Apache Hadoop con modo Pseudo-Distribuido en un solo servidor Ubuntu. Para hacer eso, harás cambios en algunas de las configuraciones de Hadoop:
- core-site.xml - Esto se utilizará para definir el NameNode para el clúster de Hadoop.
- hdfs-site.xml - Esta configuración se utilizará para definir el DataNode en el clúster de Hadoop.
- mapred-site.xml - La configuración de MapReduce para el clúster de Hadoop.
- yarn-site.xml - Configuración de ResourceManager y NodeManager para el clúster de Hadoop.
Configurando NameNode y DataNode
Primero, configurarás el NameNode y DataNode para el clúster de Hadoop.
Abre el archivo ‘$HADOOP_HOME/etc/hadoop/core-site.xml‘ usando el siguiente comando del editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlAgrega las siguientes líneas al archivo. Asegúrate de cambiar la dirección IP del NameNode, o puedes reemplazarla con ‘0.0.0.0’ para que el NameNode se ejecute en todas las interfaces y direcciones IP.
fs.defaultFS
hdfs://192.168.5.100:9000
Guarda el archivo y sal del editor cuando hayas terminado.
A continuación, ejecuta el siguiente comando para crear nuevos directorios que se utilizarán para el DataNode en el clúster de Hadoop. Luego, cambia la propiedad de los directorios del DataNode al usuario ‘hadoop‘.
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsDespués de eso, abre el archivo ‘$HADOOP_HOME/etc/hadoop/hdfs-site.xml’ usando el siguiente comando del editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlAgrega la siguiente configuración al archivo. En este ejemplo, configurarás el clúster de Hadoop en un solo nodo, por lo que debes cambiar el valor de ‘dfs.replication’ a ‘1’. Además, debes especificar el directorio que se utilizará para el DataNode.
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
Guarda el archivo y sal del editor cuando hayas terminado.
Con el NameNode y DataNode configurados, ejecuta el siguiente comando para formatear el sistema de archivos de Hadoop.
hdfs namenode -formatRecibirás una salida como esta:
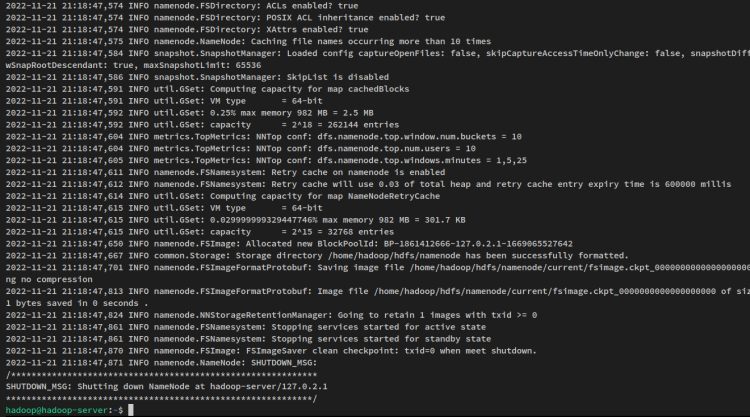
A continuación, inicia el NameNode y DataNode a través del siguiente comando. El NameNode se ejecutará en la dirección IP del servidor que has configurado en el archivo ‘core-site.xml’.
start-dfs.shVerás una salida como esta:
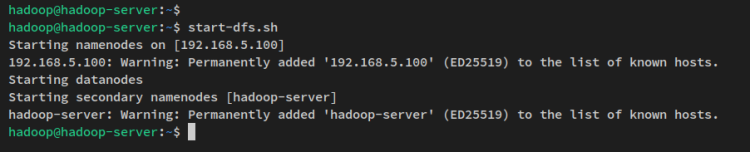
Ahora que el NameNode y DataNode están en ejecución, verificarás ambos procesos a través de la interfaz web.
La interfaz web del NameNode de Hadoop se ejecuta en el puerto ‘9870‘. Así que, abre tu navegador web y visita la dirección IP del servidor seguida del puerto 9870 (es decir: http://192.168.5.100:9870/).
Deberías obtener ahora la página como la siguiente captura de pantalla - El NameNode está actualmente activo.
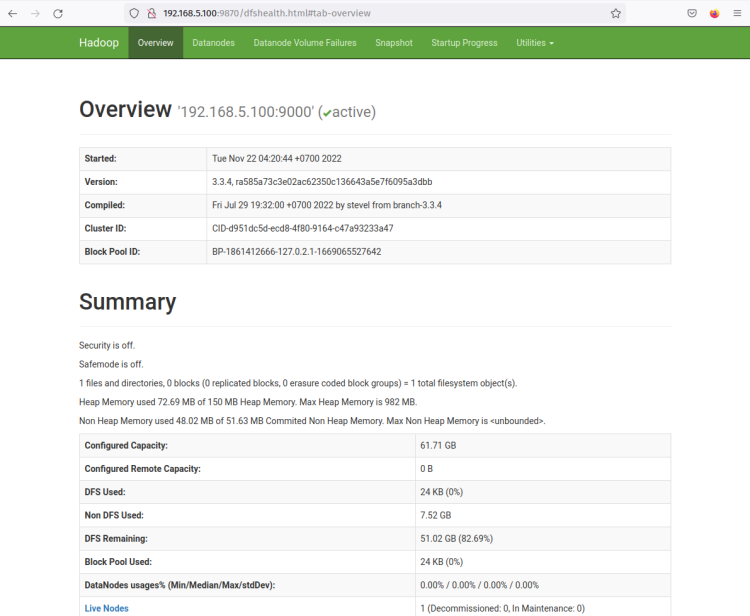
Ahora haz clic en el menú ‘Datanodes’ y deberías obtener el DataNode actual que está activo en el clúster de Hadoop. La siguiente captura de pantalla confirma que el DataNode está en ejecución en el puerto ‘9864‘ en el clúster de Hadoop.
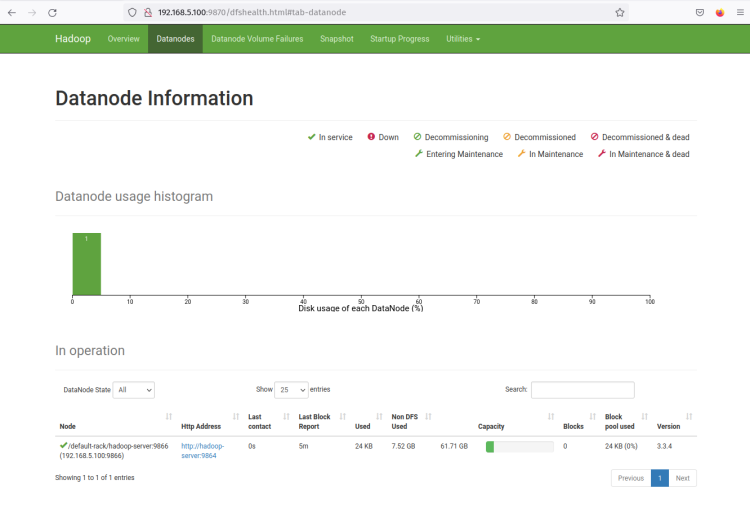
Haz clic en la ‘ Http Address ‘ del DataNode y deberías obtener una nueva página con información detallada sobre el DataNode. La siguiente captura de pantalla confirma que el DataNode está en ejecución con el directorio de volumen ‘/home/hadoop/hdfs/datanode‘.
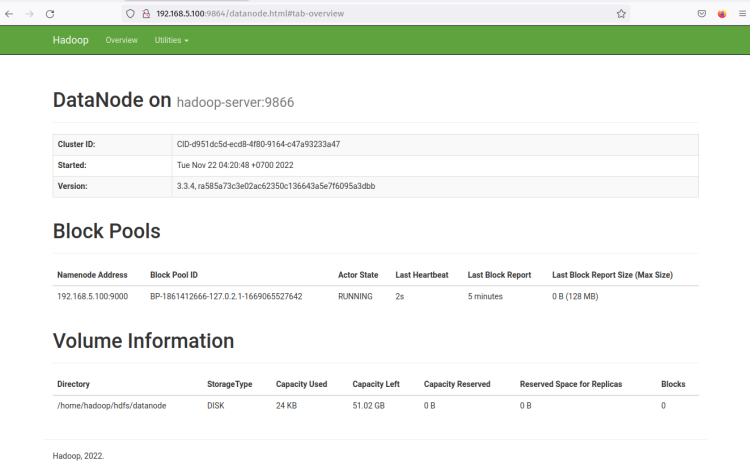
Con el NameNode y DataNode en ejecución, a continuación configurarás y ejecutarás MapReduce en el gestor Yarn (Yet Another ResourceManager y NodeManager).
Gestor Yarn
Para ejecutar un MapReduce en Yarn en el modo pseudo-distribuido, necesitas hacer algunos cambios en los archivos de configuración.
Abre el archivo ‘$HADOOP_HOME/etc/hadoop/mapred-site.xml‘ usando el siguiente comando del editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlAgrega las siguientes líneas al archivo. Asegúrate de cambiar el mapreduce.framework.name a ‘yarn’.
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
Guarda el archivo y sal del editor cuando hayas terminado.
A continuación, abre la configuración de Yarn ‘$HADOOP_HOME/etc/hadoop/yarn-site.xml‘ usando el siguiente comando del editor nano.
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlCambia la configuración predeterminada con los siguientes ajustes.
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
Guarda el archivo y sal del editor cuando hayas terminado.
Ahora ejecuta el siguiente comando para iniciar los demonios de Yarn. Y deberías ver que tanto ResourceManager como NodeManager están iniciando.
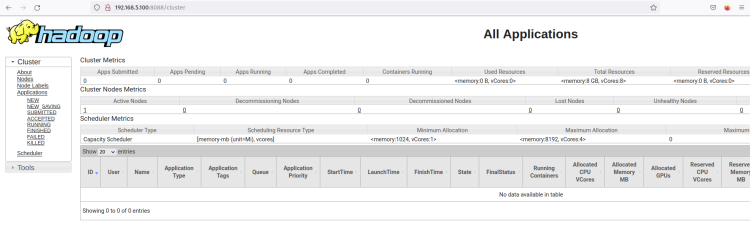
start-yarn.shEl ResourceManager debería estar ejecutándose en el puerto predeterminado 8088. Regresa a tu navegador web y visita la dirección IP del servidor seguida del puerto ResourceManager ‘8088’ (es decir: http://192.168.5.100:8088/).
Deberías ver la interfaz web del ResourceManager de Hadoop. Desde aquí, puedes monitorear todos los procesos en ejecución dentro del clúster de Hadoop.
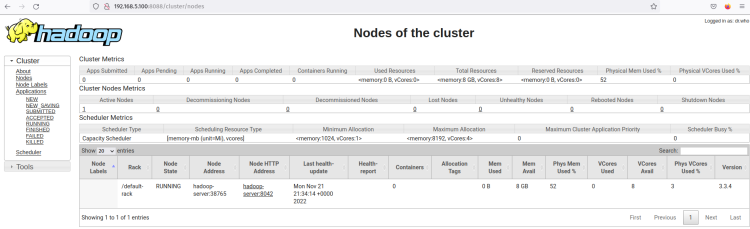
Haz clic en el menú Nodes y deberías obtener el nodo actual en ejecución en el clúster de Hadoop.
Ahora el clúster de Hadoop está en ejecución en modo pseudo-distribuido. Esto significa que cada proceso de Hadoop se está ejecutando como un solo proceso en un único servidor Ubuntu 22.04, que incluye el NameNode, DataNode, MapReduce y Yarn.
Conclusión
En esta guía, instalaste Apache Hadoop en un servidor Ubuntu 22.04 de máquina única. Instalaste Hadoop con el modo Pseudo-Distribuido habilitado, lo que significa que cada componente de Hadoop se está ejecutando como un solo proceso Java en el sistema. En esta guía, también aprendiste cómo configurar Java, configurar variables de entorno del sistema y configurar autenticación SSH sin contraseña a través de clave pública-privada SSH.
Este tipo de despliegue de Hadoop, modo Pseudo-Distribuido, se recomienda solo para pruebas. Si deseas un sistema distribuido que pueda manejar conjuntos de datos medianos o grandes, puedes desplegar Hadoop en modo Clúster, que requiere más sistemas de computación y proporciona alta disponibilidad para tu aplicación.
Recibe nuevas publicaciones en tu bandeja de entrada.
No spam. Cancela la suscripción en cualquier momento.