Integración · 9 min read · Oct 18, 2025
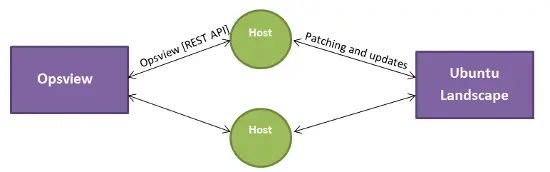
Integrando Ubuntu Landscape con Opsview Enterprise
Integrando Ubuntu Landscape con Opsview Enterprise
Recientemente hemos estado echando un vistazo al conjunto de herramientas de Ubuntu descrito en el discurso de apertura de Openstack de este año por Mark Shuttleworth; de particular interés fue Ubuntu Landscape, su herramienta de gestión de sistemas y servidores que permite la actualización y gestión de miles de servidores Ubuntu desde una sola consola.
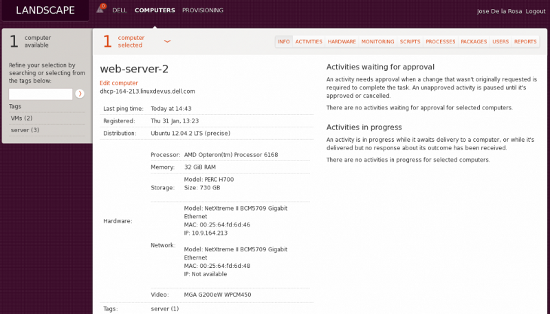
La belleza de Landscape es que si tienes 1000 servidores Ubuntu, puedes actualizar el software y parchearlos sobre la marcha desde una sola vista, incluso puedes hacer clic en cada servidor para obtener los inventarios de hardware y software, ver los informes sobre qué procesos están utilizando la CPU, etc., todo desde una sola herramienta.
Un elemento interesante desde la perspectiva de Opsview es que contiene una pestaña de “monitoreo” por dispositivo. Esta pestaña es rudimentaria en el sentido de que solo muestra lo básico del monitoreo (uso de recursos, rendimiento de la red, etc.) como se muestra a continuación:
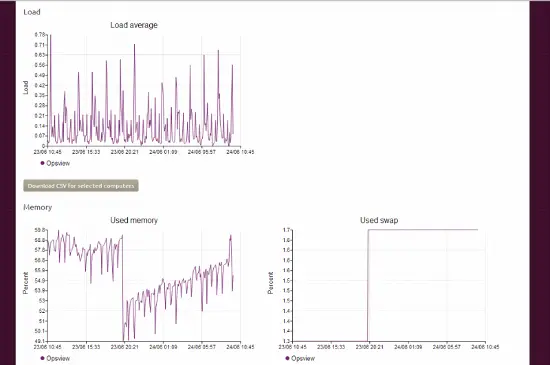
Esto presumiblemente se está recopilando / consultando a través del cliente de Landscape que se ejecuta en el servidor Ubuntu y utilizando las salidas habituales de “carga”, etc., que se están analizando y modificando. Este detalle es bastante básico, sin embargo, es poco probable que muchas personas lo utilicen como su única herramienta de monitoreo en lugar de Opsview; es más un complemento útil que te permite verificar la salud de ‘X’ mientras estás en el panel de control de Landscape.
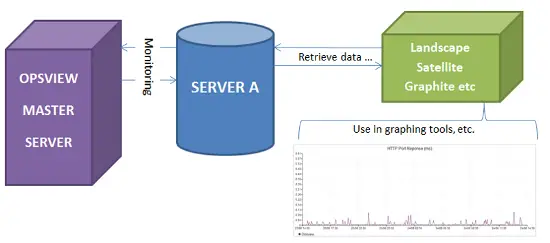
Sin embargo, esto nos hizo pensar: ¿qué pasaría si pudiéramos seguir utilizando Opsview como nuestra herramienta principal de monitoreo, que permite a los clientes iniciar sesión para ver sus sistemas a través de un panel de control, enviar informes por correo electrónico, enviar alertas por SMS, etc., pero integrar estos datos de Opsview en el panel de control de Landscape? Así, sería posible hacer clic en “Server100” en Opsview y “Server100” en Landscape, y ver los mismos gráficos. Esto podría permitirnos ver la salud del servidor, sin importar qué herramienta estemos utilizando.
Para hacer esto en Landscape, en realidad es bastante simple (una vez que te acostumbras a los matices del sistema). Primero, desde nuestra consola principal, debemos navegar a “Gráficos personalizados” como se muestra a continuación:
A continuación, debemos hacer clic en “Agregar gráfico personalizado”, lo que trae una página como la siguiente (hemos ahorrado tiempo al completar el campo ya):
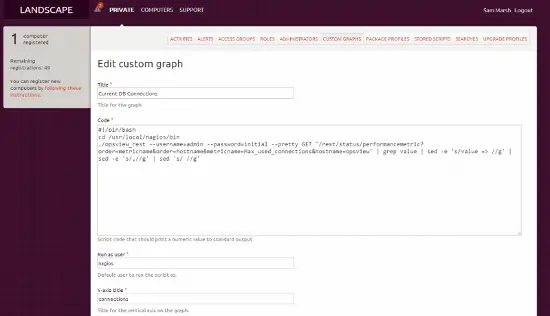
Como puede ser difícil de leer en la imagen, el “código” se pega a continuación:
#!/bin/bash
cd /usr/local/nagios/bin
./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview' | grep value | sed -e 's/value => //g' | sed -e 's/,//g' | sed 's/ //g' Esto básicamente utiliza el comando opsview_rest para conectarse al sistema de monitoreo Opsview y obtener la métrica “max_used_connections” del host “opsview” y luego realiza algunas modificaciones para darnos un valor graficable, es decir, “28”, en lugar de “value=>28;21;s…” que a Ubuntu no le gusta :)
Lo que esto nos permite hacer es tener nuestro sistema de monitoreo Opsview agregado como un host de Landscape y permitirnos monitorear la salud del sistema de monitoreo a través de Landscape, junto con la salud de cualquier otro host que esté siendo monitoreado por el sistema Opsview, y cualquier verificación de servicio que se esté ejecutando contra él. Podemos obtener esta información ejecutando el comando:
opsview_rest --username=admin --password=initial --pretty GET /rest/status/performancemetric/?hostname=opsviewDonde “?hostname” es el host del que estamos tratando de ver los datos de rendimiento. Una vez que esto está configurado y guardado según la captura de pantalla anterior, necesitamos establecer nuestro “ejecutar como usuario:” (ya sea root o un usuario diferente) y “Título del eje Y” (segundos, conexiones de base de datos, temperatura, etc.). Una vez hecho esto, hacemos clic en “Guardar” y esto se aplicará a todos los hosts (si has marcado la casilla).
Luego, después de un día más o menos, podemos ir al host y ver la pestaña de “monitoreo” y ver nuestros gráficos personalizados:
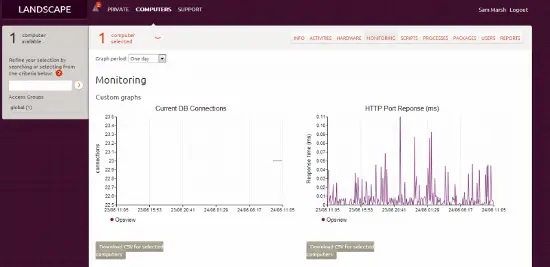
…y así es como podemos integrar Opsview con Ubuntu Landscape.
El Desafío
El desafío que enfrentamos a continuación fue que el dispositivo gestionado por Landscape ejecuta el comando:
./opsview_rest --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'..lo cual utiliza “opsview_rest” a través de bash y se ejecuta localmente. Lo ideal sería ejecutar esto desde cualquier lugar (es decir, el servidor que estamos gestionando en Landscape) pero aún así ejecutar contra nuestro sistema Opsview. Lo último es fácil; podemos agregar un prefijo como se muestra a continuación:
./opsview_rest *--url-prefix=monitoringtool.company.com* --username=admin --password=initial --pretty GET '/rest/status/performancemetric?order=metricname&order=hostname&metricname=Max_used_connections&hostname=opsview'…pero esto aún depende del comando “opsview_rest”, que obviamente debe estar disponible en la caja local ya que los gráficos personalizados ejecutan el script localmente en el sistema gestionado por Ubuntu Landscape. Y también esto expone el nombre de usuario y la contraseña al servidor host, es decir, tu servidor web ahora tiene detalles de inicio de sesión para Opsview. Sin embargo, podemos restringir este último problema permitiendo que ese rol tenga acceso muy específico solo para lectura, y solo para lectura de algunos elementos específicos.
Lo que necesitamos es la capacidad de que el host que está siendo monitoreado por Opsview y gestionado por Ubuntu Landscape, tenga la capacidad de consultar Opsview a través de la API REST sobre su propia salud, para que pueda proporcionar esta información de vuelta a Landscape para graficar. Sin embargo, no podemos distribuir opsview_rest debido a problemas de Perl, dependencias, etc., así que, ¿qué podemos hacer?
El único elemento que parece funcionar o satisfacer nuestros criterios es usar check_nrpe de la “manera no tradicional”. Lo que quiero decir con eso, es que tradicionalmente NRPE es un programa del lado del cliente que es consultado por Opsview para obtener información, es decir, “¿Qué tan ocupado está tu CPU? ¿Qué tan llenos están tus discos?”. Estos valores se devuelven a Opsview y se almacenan para informes, paneles de control y similares y se utilizan para alertas.
Lo que encontramos en este ejemplo, es que podríamos instalar el Cliente NRPE (Agente Opsview) en el host monitoreado/gestionado y usar eso para consultar NRPE que se ejecuta en el maestro de Opsview.
En este maestro de Opsview, especificaríamos nuestros comandos NRPE en “/usr/local/nagios/etc/nrpe_local/overrides.cfg” (este archivo no existe, necesitas crearlo) y agregar las líneas como se muestra a continuación:
############################################################################
# Archivo de configuración NRPE adicional para Opsview
############################################################################
check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl $ARG1$ $ARG2$Donde “get_rest” es el comando que llamaremos de forma remota, y cualquier cosa “al este del signo igual” es el comando real que se ejecuta localmente.
Puedes ver en lo anterior, que estamos ejecutando algo llamado “landscape_monitor.pl”; un script de Perl que escribimos para tomar el argumento del host (es decir, $ARG1$ podría ser “server00156” o “networkswitch-X624” en Opsview (el ‘nombre del host’)). Esto significa que en lugar de tener que crear un check_command para cada uno, es decir:
check_command[get_rest]=/usr/local/nagios/bin/landscape_monitor.pl server1
check_command[get_rest2]=/usr/local/nagios/bin/landscape_monitor.pl server2
check_command[get_rest3]=/usr/local/nagios/bin/landscape_monitor.pl server3 Podemos simplemente usar $ARG1$ y hacer que nuestro script de Perl lo espere. A continuación, tenemos el script real (esto utiliza JSON e IPC, por lo que necesitamos los siguientes paquetes instalados en el sistema Opsview: libipc-run-perl libjson-any-perl)
#!/usr/bin/perl Shell
use strict;
use warnings;
use IPC::Run qw(run);
use JSON;
my $hostname = $ARGV[0] || '';
my $perf_metric = $ARGV[1] || '';
my @cmd = qw(/usr/local/nagios/bin/opsview_rest --username admin --password initial --data-format json GET);
push @cmd, '/rest/status/performancemetric?order=metricname&order=hostname&metricname='. $perf_metric .'&hostname='. $hostname;
run \\@cmd, \\undef, \\my $out;
my $data = decode_json($out);
print $data->{list}->[0]->{value};Como podemos ver arriba, tomamos una variable (el nombre del host) y la agregamos al comando opsview_rest que estamos construyendo. También tomamos la métrica de rendimiento y después de ejecutar el comando construido, luego imprimimos la salida del comando en formato JSON – “23” en nuestro ejemplo. Esto nos ahorra tener que grep / sed la hell out de él para obtener el valor real que Landscape puede usar.
Así que, una vez que hayas agregado tu script “landscape_monitor.pl” a /usr/local/nagios/bin/, y chmod / chown’d it – puedes proceder a crear el archivo overrides.cfg y agregar la línea como se muestra arriba.
Finalmente, inicia NRPE en el dispositivo monitoreado/gestionado – y estamos listos para descansar como se muestra a continuación.
Escenario
Etapa 1: Tenemos el entorno de monitoreo estándar; Opsview monitorea “Servidor A” y solicita información como estadísticas de DB, estadísticas de apache, etc., y muestra esta información en paneles de control a los usuarios a través de la GUI, envía alertas por correo electrónico/mensaje de texto, etc., cuando surgen problemas.
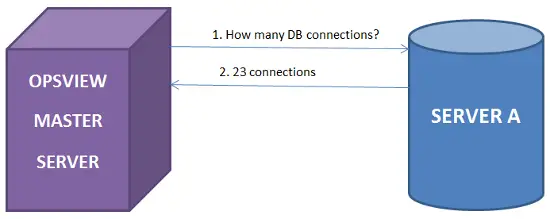
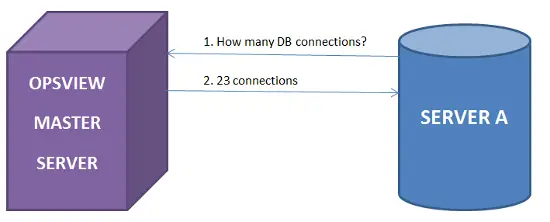
Etapa 2: Ahora que Opsview está recopilando miles de métricas y estadísticas de nuestros servidores, podemos usar la API REST para consultar esas estadísticas desde el servidor monitoreado, es decir, “Servidor A”, utilizando el script perl anterior. Para hacer esto, simplemente ejecutamos los comandos como se muestra a continuación:
./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connectionsubunt@serverA:/usr/local/nagios/libexec$ ./check_nrpe -H opsview-master-server -c get_rest -a serverA Max_used_connections
23
ubunt@serverA:/usr/local/nagios/libexec$Al usar check_nrpe en ServerA y pasar nuestro nombre de host, es decir, “ServerA”, podemos ver el valor max_db_connections que Opsview tiene para nosotros.
Etapa 3: Debido a que ahora tenemos la capacidad para que el dispositivo monitoreado conozca sus propias métricas, las posibilidades de lo que podemos hacer son infinitas. En nuestro ejemplo, simplemente queremos usar Landscape para graficar nuestras métricas recopiladas por Opsview para que podamos tener acceso a los gráficos “de un vistazo” en nuestro sistema Landscape, junto con la capacidad de profundizar en Opsview para ver informes / paneles de control y los elementos más específicos de monitoreo. Sin embargo, no hay nada que nos impida usar esta tecnología para integrar Opsview con otras herramientas de graficación, etc.
Para integrar esto con Landscape, es muy simple. Simplemente necesitamos crear otro “Gráfico Personalizado” como describimos anteriormente en el documento, y en el cuadro de texto agregar:
#!/bin/bash
cd /usr/local/nagios/bin
./check_nrpe –H opsviewserver –c get_rest -a servername max_used_connections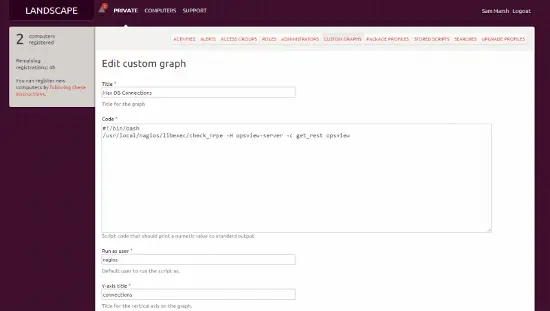
Finalmente, aplicamos este gráfico al único host que queremos – y voila, ahora estamos monitoreando las “máximas conexiones de DB” del servidor, a través de Landscape. Luego podemos construir sobre esto, cambiar la métrica, etc., así que, en esencia, puedes ver todas las métricas recopiladas por Opsview, desde dentro de Ubuntu Landscape, RH Satellite, etc.
Una última mirada
Así que, en teoría, ahora tenemos el siguiente escenario:
- 100 servidores Ubuntu siendo gestionados y parchados, etc., por Ubuntu Landscape.
- 100 servidores Ubuntu siendo monitoreados y alertados, etc., por Opsview Enterprise.
Tendríamos los hosts añadidos tanto a Landscape como a Opsview, y usaríamos Opsview para el nivel más granular de monitoreo, alertas, informes, paneles de control, NetFlow, etc., y luego integrar las métricas particularmente interesantes “de un vistazo” en la página de Landscape de esos hosts.
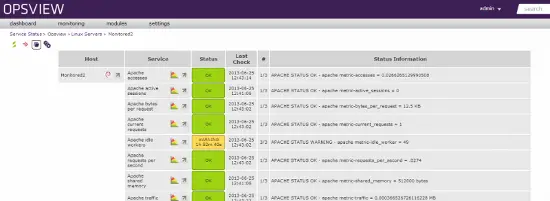
Host en Opsview
El host se agrega en Opsview como se mencionó anteriormente; podemos ver todas las métricas, graficar sobre ellas, controlar cuándo se monitorean, cambiar métricas basadas en el período de tiempo, etc.
Host en Landscape
También tenemos el host en Landscape; desde esta vista podemos ver el activo (hardware, etc.), actualizar paquetes, ver informes sobre la salud del sistema, etc. También podemos hacer clic en “Monitoreo” y ver nuestra información recopilada por Opsview “de un vistazo”, desde dentro de Landscape, como se muestra a continuación:
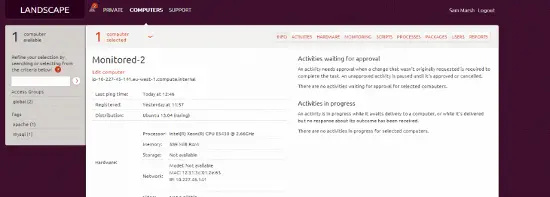
(aunque, ¡un servidor Apache muy poco utilizado! ^_^ ).
Prueba Opsview Enterprise ›
Prueba Ubuntu Landscape ›
Recibe nuevas publicaciones en tu bandeja de entrada.
No spam. Cancela la suscripción en cualquier momento.